Download

1 / 19
190 likes | 385 Views
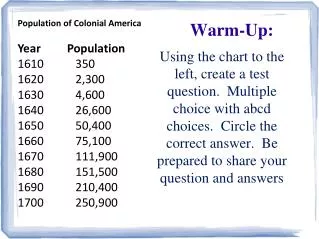
Warm-up. Find a range for the p-value for a left tail test where t = -2.31 Find a range for p-value for a 2 sided tail test where t = 1.56 Sample size is 25. The T-Test. What shall we do if we don’t know the population standard deviation?. The T-Distribution.

E N D
Warm-up • Find a range for the p-value for a left tail test where t = -2.31 • Find a range for p-value for a 2 sided tail test where t = 1.56 Sample size is 25.
The T-Test What shall we do if we don’t know the population standard deviation?
The T-Distribution • T-Distribution is flatter than the standard normal curve (more area in the tails) • The flatness depends on something called degrees of freedom(dof) • Degrees of freedom = sample size – 1 • As dof goes up t-distribution becomes more like the standard normal curve. • http://www-stat.stanford.edu/~naras/jsm/TDensity/TDensity.html
T-Test Inference for population mean • Step 1 The same as before • What is the population and parameter • Step 2 Different • What inference procedure will you use (z-test or t-test) • Conditions: (1) Data from an SRS (2) Normal pop. distribution • For small sample sizes (n < 30): we check normality by making a stemplot, boxplot, histogram, or normal probability curve with our sample data. We look for any great skewness or outliers. • For large sample sizes (n >= 30): we can use the t-distribution even for clearly skewed data. • Step 3 Different • Calculate t-statistic and p-value • Step 4 The same • Interpret the results in the context of the problem
Test for population mean • Suppose a CEO of a large company wants to determine whether the average amount of time spent on personal use of computer technology for his company is greater than the reported national average of 70 minutes. In an SRS of 10 employees, the following results were obtained. Does this data indicate the mean time spent by employees of this company is greater than 70 minutes? Use
Solution • The population is all the employees of the company and we are interested in their mean time spent using the computer for personal use. We will conduct a hypothesis test with: The mean time spent using the computer for personal use is 70 minutes The mean time spent using the computer for personal use is greater than 70 minutes
Solution • We will conduct a one sample t-test since we do not know . The conditions are checked below: (1) SRS: The problem states the employees are picked from an SRS (2) Normality of population distribution The data is slightly skewed right but there are no outliers. Because there is no great skewness or outliers, it is plausible the population distribution is normal. So we proceed believing the population distribution is normal and thus the sampling distribution is normal 6|3 6|6 9 7|0 1 1 7|5 8| 8|6 8 9
Solution • To calculate the t-statistics we need to estimate the standard deviation (s). • Put your data into L1 • Stats 1 Variable Statistics L1 gives us Sx and • degrees of freedom = n – 1 = 10 – 1 = 9 • Notice 1.606 is between .10 and .05 thus
Solution • The p-value is greater than the 1% significance level – thus we accept the null hypothesis. This means we do not have evidence at the 1% significance level to say that the time employees of this company spend using the computer for personal use is greater than the national average of 70 minutes.
T-Test Intervals • Step 1 The same as before • What is the population and parameter • Step 2 Different • What inference procedure will you use (z-interval/t-interval) • Conditions: (1) Data from an SRS (2) Normal pop. distribution • For small sample sizes (n < 30): we check normality by making a stemplot, boxplot, histogram, or normal probability curve with our sample data. We look for any great skewness or outliers. • For large sample sizes (n >= 30): we can use the t-distribution even for clearly skewed data. • Step 3 Different • Construct the interval • Step 4 The same • Interpret the results in the context of the problem • “I am ____ % confident that…”
Interval for population mean • Confidence Interval t* is the critical value associated with the confidence level • From the 1st Example: Construct a 95% confidence interval for mean personal time spent using the computer.
Comparing two means • Many time we want to compare two means rather than compare a mean to some hypothesized value • What you do depends on whether the we take samples are independent/dependent • We start with samples that are dependent though a matched pairs procedure
Matched Pairs • You must be able to recognize a matched pairs experiment. • Each matched pairs experiment has 2 treatments. • There are 2 ways to conduct matched pairs: • Give each individual subject the 2 different treatments. Measure after each treatment. “Before ACT prep…After ACT Prep” or • Match up groups of 2 subjects by some similar characteristics and randomly given them the treatments.
Matched Pairs t procedure • We use the same one-sample procedures we just learned to the difference of the observations. • We treat the difference between the observations as our random variable.
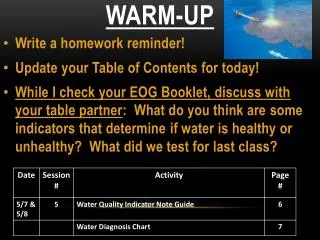
Matched Pairs Example • Police trainees were seated in a darkened room facing a projector screen. Ten different license planes were projected on the screen, one at a time, for 5 seconds each, separated by 15-second intervals. After the last 15-second interval, the lights were turned on and the police trainees were asked to write down as many of the 10 license plate numbers as possible, in any order at all. A random sample of 15 trainees who took this test where then given a week-long memory training course. They were then retested. The results are shown in the table below. Notice a positive value means they did better after training.
Solution • To assess whether the training improved performance we will conduct a hypothesis test with being the mean difference in the population from which the subjects were drawn. The test we will run is The null hypothesis is that there is no improvement The alternative is that there is an improvement in memory after the training.
Solution • We don’t know the standard deviation of the population differences so we will perform a one-sample t test for the matched pairs experiment. Next we check the conditions (1) The data comes from a randomized, matched pairs experiment so we can view our sample as an SRS from the population. (2) A stemplot of the difference reveals a slight skew to the left but the graph is approximately normal in shape. There are no outliers. It is reasonable to assume the population of the differences is normal. -0| 3 -0| 1 0| 0 0 0 0 0| 2 2 2 2 3 3 3 0| 5 5 Key: -0|3 = -3 0|2 = 2
Solution • Note: x is the sample mean of the differences s is the standard deviation of the differences degrees of freedom = 15 – 1 = 14
Solution • The chance we received a sample like the one given is between .5% and 1%. Since this is very unlikely, the evidence suggests that the training course has improved the officers ability to identify plates.