
Human Speech Communication
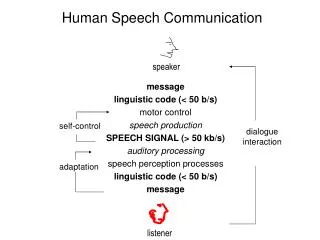
message linguistic code (< 50 b/s) motor control speech production SPEECH SIGNAL (> 50 kb/s) auditory processing speech perception processes linguistic code (< 50 b/s) message. speaker. self-control. dialogue interaction. adaptation. listener. Human Speech Communication. speaker.

Human Speech Communication
E N D
Presentation Transcript
message linguistic code (< 50 b/s) motor control speech production SPEECH SIGNAL (> 50 kb/s) auditory processing speech perception processes linguistic code (< 50 b/s) message speaker self-control dialogue interaction adaptation listener Human Speech Communication
speaker h h e e l l o o w w o o r r l l d d u u listener very low bit rate message low bit rate knowledge high bit rate shared low bit rate very low bit rate message knowledge
h h e e l l o o w w o o r r l l d d u u Machine recognition of speech high bit rate machine recognition of speech word another word low bit rate message
o u COARTICULATION
h e l o w o r l d u hello world w h e l u o r l d o coarticulation+ talker idiosyncrasies + environmental variability = a big mess
Two dominant sources of variability in speech • FEATURE VARIABILITY • different people sound different, communication environment different, coarticulation effects, … • TEMPORAL VARIABILITY • people can say the same thing with different speeds • “Doubly stochastic” process (Hidden Markov Model) • Speech as a sequence of hidden states (phonemes) - recover the sequence • never know for sure which data will be generated from a given state • never know for sure in which state we are
already old Greeks …….. wall fire echoes activity shadows
f0=195 125 140 120 185 130 145 190 245 155 130 Hz hi hi hi hi hi hi hi hi hi hi hi • Know • what are the typical ranges of boy’s and girl’s voices ? • how likely a boy walks first? • how many boys and girls go typically together? • how many more boys is typically there? • Want to know • where are the boys (girls) ?
the model pm pf P(sound|gender) 1-pm m f m f f0 1-pf P(gender) p1m pm pf Given this knowledge, generate all possible sequences of boys and girls and find which among them could most likely generate the observed sequence
girls girls boys boys boys compute distributions of parameters for each state find the best alignment of states given the parameters compute distributions of parameters for each state find the best alignment of states given the parameters Getting the parameters (training of the model) hi hi hi hi hi hi hi hi hi hi hi f0=140 120 190 125 155 130 145 160 245 165 150 Hz “Forced alingnment” of the model with the data
Machine recognition of speech more complex model architecture
How to find w (efficiently) ? Form of the model M ( wi )? What is the data x?
Data x? • Describes changes in acoustic pressure • original purpose is reconstruction of speech • rather high bit-rate Speech signal ? • additional processing is necessary to alleviate the irrelevant information
acoustic training data prior knowledge speech signal best matching utterance acoustic processing decoding (search) pre-processing Machine for recognition of speech
frequency time time
frequency time
time frequency get spectral components time Short-term Spectrum 10-20 ms /j/ /u/ /ar/ /j/ /o/ /j/ /o/
Short-term Fourier analysis log gain p 0 frequency [rad/s]
Spectral resolution of hearing spectral resolution of hearing decreases with frequency (critical bands of hearing, perception of pitch,…) 10000 5000 2000 1000 critical bandwidth [Hz] 500 100 50 50 100 500 1000 5000 10000 frequency [Hz]
frequency energies in “critical bands”
loudness = intensity 0.33 intensity (power spectrum) intensity ≈ signal 2 [w/m2] loudness [Sones] |.|0.33 loudness
Not all spectral details are important a) compute Fourier transform of the logarithmic auditory spectrum and truncate it (Mel cepstrum) b) approximate the auditory spectrum by an autoregressive model (Perceptual Linear Prediction – PLP) 6th order AR model 14th order AR model power (loudness) power (loudness) frequency (tonality) frequency (tonality)
Current state-of-the-art speech recognizers typically use high model order PLP
It’s about time (to talk about TIME)
masker increase in threshold signal stronger masker t time 0 t 200 ms Masking in Time • suggests ~200 ms buffer (critical interval) in auditory system
time trajectories of the spectrum in critical bands of hearing filter with time constant > 200 ms (temporal buffer > 200 ms)
spectrogram (short-term Fourier spectrum) time [s] Perceptual Linear Prediction (PLP) (12th order model) RASTA-PLP
filter spectrogram spectrum from RASTA-PLP
/f/ /v/ /ay/ time data Data-guided feature extraction Spectrogram Posteriogram artificial neural network trained on large amounts of labeled data frequency preprocessing time
increase in threshold of perception of the target stronger masker 0 t 200 ms critical bandwidth Masking in time Masking in frequency • what happens outside the critical interval, does not affect detection of signal within the critical interval what happens outside the critical band does not affect decoding of the sound in the critical band increase in threshold of perception of the target Signal components inside the critical time-frequency window interact noise bandwidth
t0 32 2-D projections with variable resolutions data1 data2 32 2-D projections with variable resolutions dataN Emulation of cortical processing(MRASTA) 16 x 14 bands = 448 projections frequency peripheral processing (critical-band spectral analysis) time
Spectro-temporal basis formed by outer products of example time frequency frequency 3 critical bands central band frequency derivative -500 0 500 time [ms] 0 -500 500 time [ms] Multi-resolution RASTA (MRASTA) (Interspeech 05) Bank of 2-D (time-frequency) filters (band-pass in time, high-pass in frequency) RASTA-like: alleviates stationary components multi-resolution in time
Spectral dynamics (much) more interesting than spectral shape Old way of getting spectral dynamics f0 short-term spectral components t0 time Older way of getting spectral dynamics (Spectrograph™) f0 spectral components t0 time
critical-band spectrum from all-pole models of auditory-like spectrum (PLP) frequency time critical-band spectrum from all-pole models of temporal envelopes of the auditory-like spectrum (FDPLP) frequency time
Reverberant speech Telephone speech Gain included Gain excluded Digit recognition accuracy [%] - ICSI Meeting Room Digit Corpus clean reverberated PLP 99.7 71.6 FDPLP 99.2 87.0 Improvements on real reverberations similar (IEEE Signal Proc.Letters 08) Phoneme recognition accuracy [%] TIMIT HTIMIT PLP-MRASTA 67.6 47.8 FDPLP 68.1 53.5
FDPLP with static and dynamic compression Recognition accuracy [%] on TIMIT, HTIMIT, CTS and NIST RT05 meeting tasks PLP FDPLP TIMIT 64.9 65.4 HTIMIT 34.4 52.7 CTS 52.3 59.3 RT05 60.4 64.1 logarithmically compressed FDLP fit Hilbert envelope FDLP fit compressed by PEMO model FDLP fit to Hilbert envelope
histogram of one element TANDEM(Hermansky et al., ICASSP 2000) • features for conventional speech recognizer should be Normally distributed and uncorrelated principal component projection to HMM (Gaussian mixture based) classifier posteriors of speech sounds pre-softmax outputs correlation matrix of features
Summary • Alternatives to short-term spectrum based attributes could be beneficial • data-driven phoneme posterior based • extract speech-specific knowledge from large out-of-domain corpora • larger temporal spans • exploit coarticulation patterns of individual speech sounds • models of temporal trajectories • improved modeling of fine temporal details • allows for partial alleviation of channel distortions and reverberation effects
o h e l w o r l d u human speech production coarticulation human auditory perception o h e l w o r l d u Coarticulation
unequally distributed identities of individual speech sounds (phonemes) low bit rate h e l o w o r l d u equally distributed posterior probabilities of speech sounds pre-processing to emulate known properties of peripheral and cortical auditory processes Hierarchical bottom-up event-based recognition ? high bit rate
/n/ /ay/ /n/ /ay/ /n/ /n/ phoneme posterior probability matched filtering One way of going from phoneme posteriors to phonemes
Perceptual processes, involved in decoding of message in speech ? where and how ? higher levels (cortical) probably most relevant acoustic “events” for speech ? Cognitive issues what to “listen for” ? roles of “bottom-up” and “top-down” channels ? coding alphabet (phonemes) ? category forming invariants when to make decision ? e.t.c. ???????????????? SPEECH SIGNAL (high bit-rate) auditory perception acoustic “events” ??? cognitive processes ??? linguistic code (low bit rate) ??? cognitive processes ??? message (even lower bit rate) (some of) the Issues





















