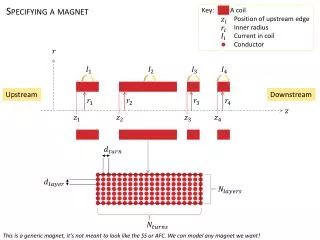
Enhancing Library Cataloging Through Upstream Metadata Workflows
This document discusses the evolving role of catalogers and the importance of descriptive metadata in libraries, highlighting the need for improved workflows in bibliographic control. It outlines past practices, recent developments in electronic metadata availability, and recommendations from the Library of Congress Working Group on Bibliographic Control. Key suggestions include automating cataloging processes, utilizing metadata from publishers effectively, and streamlining workflows to allow catalogers to focus on unique collections. This approach aims to enhance accessibility and user experience in libraries.


Enhancing Library Cataloging Through Upstream Metadata Workflows
E N D
Presentation Transcript
Upstream Metadata Library needs and workflows Diane Boehr Head of Cataloging National Library of Medicine, NIH, DHHS boehrd@mail.nlm.nih.gov
Role of the cataloger • Descriptive metadata • Authority work • Subject analysis
Past Practices • In the past, there was no way for catalogers to get information into the catalog without manually transcribing the data from the piece
What’s changed? • Even for print products, there is now metadata available in electronic format early in the creation process, particularly for the basic descriptive information
LC Working Group on the Future of Bibliographic Control • The Library of Congress commissioned a Working Group in the fall of 2006 charged to: • Present findings on how bibliographic control and other descriptive practices can effectively support management of and access to library materials in the evolving information and technology environment • Recommend ways in which the library community can collectively move toward achieving this vision • Advise the Library of Congress on its role and priorities
LC Working Group • Their final report was issued in Jan. 2008, entitled: On the Record http://www.loc.gov/bibliographic-future/news/lcwg-ontherecord-jan08-final.pdf
On the Record • Recommendation 1 • Increase the efficiency of bibliographic record production and maintenance • 1.1 Eliminate redundancies • Libraries have so far taken minimal advantage of descriptive data being created in other venues. Given the explosion of material requiring bibliographic control, the model of item-by-item full manual transcription can no longer be sustained
On the Record • 1.1.1 Make Use of More Bibliographic Data Available Earlier in the Supply Chain • 1.1.1.1 Be more flexible in accepting bibliographic data from others that do not conform precisely to U.S. library standards • 1.1.1.3 Develop standard crosswalks for the conversion of publisher/vendor data to library system formats • 1.1.1.4 Develop managed processes for creating and sharing conversion programs so that programming is not done redundantly at multiple institutions
National Library Needs • A great deal of original cataloging done by the national libraries is for CIP (cataloging-in-publication) titles • Recommendation 1.1.3: Fully Automate the CIP Process
Potential CIP data workflow • Publishers participating in the CIP program would submit their descriptive metadata to LC in ONIX (or similar XML format that could be easily mapped to a MARC record) and then be ingested directly into the library ILS using a standard crosswalk • Catalogers would no longer have to highlight and paste data from a title page image and could focus on the tasks of authority work and subject analysis to create the complete CIP record
Advantages • Streamlined workflow • Publishers get their CIP data back promptly • Cataloger’s time is freed up to devote to material lacking upstream metadata, often the unique and “hidden treasures” of their collections (another LC report recommendation) • Users get richer records, with summaries and tables of contents if the publisher provides that data
Non-CIP Data Workflows • Publishers could store their descriptive metadata openly on their websites in ONIX (or similar XML format easily converted to MARC) • Vendors would be able to supply this data to libraries along with the books • Libraries could harvest that data and import directly into their catalogs using readily available conversion programs
Related Needs • Development of conversion programs from ONIX to MARC and a central repository for these (a possible role for LC or OCLC or NISO) • Even better—revise ONIX so that the data coming from publishers is more consistent and only one conversion program is needed
How OCLC Might Help • For CIPs, publishers could continue to submit the galleys and CIP data forms to LC, while simultaneously submitting the descriptive metadata to OCLC • OCLC creates the basic preliminary MARC record. The national library imports this record into their ILS to complete the cataloging—enhancing the record with controlled name access points, subject headings and classification numbers • The completed catalog record is uploaded to OCLC and sent to the publisher for printing in the book
Other Potential Enhancements • OCLC searches the WorldCat database for possible author matches and supplies likely name access points where possible • OCLC searches the WorldCat database for other editions of the work and supplies suggested subjects and classification • Cataloger’s work is greatly streamlined
Potential Enhancements Outside of OCLC • NLM already has the ability to run the preliminary MARC record through its Medical Text Indexing software and get suggested MeSH • LC could do similar types of automated analysis on their database to suggest subjects and classification for new manifestations • Mappings could be developed between MeSH and LCSH to streamline subject analysis on shared records
Author Identifiers • Work would be greatly streamlined if the community developed an author identifier standard • This numeric ID would be used by publishers to allow libraries to correctly identify and disambiguate authors
Publisher’s Metadata • For upstream metadata to work efficiently libraries need complete, accurate, consistent data from the publishers • It does not need to be in MARC format, nor does it need to follow ISBD styles of capitalization and punctuation • Publishers must be aware of what constitutes a “chief source of information”, e.g. book title must come from the title page, not the cover or spine