Vector Processing
Vector Processing. Ben Helmer Matt Sagerstrand Daniel Yingling. EARLY VECTOR PROCESSING. Vector Processing was used in supercomputers of the 1970's.


Vector Processing
E N D
Presentation Transcript
Vector Processing Ben Helmer Matt Sagerstrand Daniel Yingling
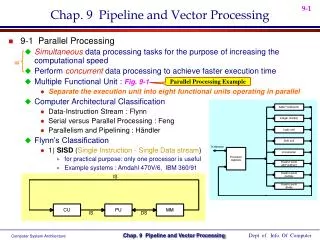
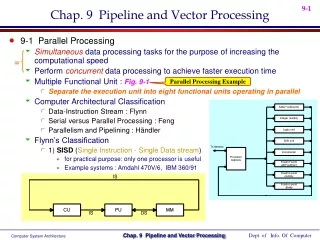
EARLY VECTOR PROCESSING • Vector Processing was used in supercomputers of the 1970's. • First successful implementations of Vector Processing are the CDC (Control Data Corporation) Cyber 100 and the Texas Instruments Advanced Scientific Computer (ASC). • Both of these were imperfect implementations. For example, the CDC Cyber 100 required a considerable amount of time to simply decode the vector instructions before calculation could be accomplished. • This meant that only a very specific set of computations could be "sped up" in this fashion.
The Cray-1 machine was the first computer to fully exploit Vector Processing. Rather than leaving the vector instructions in memory (as did the ASC and Cyber 100), the Cray-1 used sixty-four 64-bit "vector registers" for its Vector Processing. THE CRAY-1
THE CRAY-1 (Cont’d) • These vector-specific registers provided for faster computations than requiring memory access would allow. • The Cray-1 also used a process called "vector chaining" whereby the vector instructions themselves were pipelined. • "The Cray-1 normally had a performance of about 80 MFLOPS, but with up to three chains running it could peak at 240 MFLOPS – a respectable number even today." (http://encyclopedia.thefreedictionary.com/Vector%20processing).
SEYMOUR CRAY (1925-1996) • Born in Chippewa Falls, Wisconsin in 1925. • Received a B.S. in Electrical Engineering in 1950 from the University of Minnesota. Received M.S. in Applied Mathematics in 1951. • Worked at Engineering Research Associates (ERA) from 1950 to 1957. Digital computers came to be thought of as Cray's area of expertise.
SEYMOUR CRAY (Cont’d) • Formed CDC in 1957 with a number of his ERA colleagues. • Helped to create the first "supercomputer" in 1960, the CDC 6600. • Left CDC in 1972 and formed Cray Research, frustrated by CDC's lack of work on "large computers" (though the split was amicable). • Ignoring nay-sayers, Cray went ahead with his designs for the uniprocessor Cray-1, the first of which was sold in 1976 to a lab in Los Alamos for $8.8 Million. • Roughly 80 Cray-1's of each type were sold, worldwide.
SEYMOUR CRAY (Cont’d) • A number of follow-up computers came from Cray Research after this, including the successful Cray-2 (1985). • The Cray-3's design was headed up by a new company, Cray Computer Corporation, but it was a commercial failure in 1989. The company went bankrupt in 1995 during the design of the "Cray-4.“ • Seymour Cray died tragically from injuries sustained in a car accident in 1996. Cray Research has since been bought up by Silicon Graphics, Inc. • Seymour Cray is the single most important name in the field of Vector Processing. He proved that it was not only feasible from a design standpoint, but that it could also be commercially successful, particularly with his Cray-1 machine.
A number of companies attempted to follow up on the success of the Cray-1 machine, but none could really compete with Cray. Cray continued its dominance of the Vector Processing field with its Cray-2, Cray X-MP, and Cray Y-MP computers. LATER VECTOR PROCESSING
Since this time, however, the supercomputer industry has shifted its focus to "massive parallel processing" with Vector Processing now much less popular. Elements of Vector Processing are now common to most home PC's, though they are now referred to as SIMD (Single Instruction, Multiple Data). SIMD implementations generally run beside the main, scalar CPU and are only used when necessary. LATER VECTOR PROCESSING (Cont’d)
What is vector processing? • A vector processor is one that can compute operations on entire vectors with one simple instruction. • A vector compiler will attempt to translate loops into single vector instructions. • Example - Suppose we have the following do loop: do 5 i = 1, n X(i) = Y(i) + Z(i) 10 continue • This will be translated into one long vector of length n and a vector add instruction will be executed.
Why is this more efficient? • #1: Because there is only a need for one instruction, the vector processor will not have to fetch and decode as many instructions; Thus, memory bandwidth and the control unit overhead are reduced considerably. • #2: The Vector Processor, after recieving the instruction, will be told that it must fetch x amount of pairs of operands. These operands will be have a set pattern of arrangement in memory. Therefore the vector processor is able to request each pair at a consistent rate (one per cycle with an interleaved memory). When recieved, they will be passed on directly to a pipelined data unit to process them.
There are 2 specific kinds of machines • #1: Memory to memory: operands are fetched from memory and passed on directly to the functional unit. The results are then written back out to memory to complete the process. • #2: Register to register: operands are loaded into a set of vector registers, the operands are fetched from the vector registers and the results are returned to a vector register.
What are the advantages of these? • Both have their advantages. • Memory to memory is able to process very lengthy vectors but register to register has to break long vectors down into fixed-length segments. • Memory to memory contains a sizeable overhead in its startup time. This is the time it takes from the initialization of the instruction to the first result to come out of the pipeline.
Advantages (Cont’d) • Because of this and the fact that register accesses are quicker than memory accesses (quicker startup time), the register to register machine is better suited for smaller vectors and the memory to memory machine is better suited for longer vectors. • To determine which to use, startup time can be computed by the following formula: T = s + aN s = startup time a = an instruction dependent constant (which is usually either 1/2, 1, or 2) N = the length of the vector
What machines implement these? • Texas Instruments Inc. Advanced Scientific Computer, Cyber 200 series, ETA-10, all of which became outdated as a result of their long development cycles (~10 years - 1970s - 1980s). • Y-MP, C-90 (each by Cray Research Inc.), Fujitsu, Hitachi and NEC. • These use the most popular approach which is register to register. • Clock cycles have a range between 2.5 ns and 4.2 ns, and performance benchmarks between 1 and 2 GFLOPS.
More in depth on the Cray computers • 8 vector registers (V0 - V7), each of which hold 64 64-bit words. • 8 scalar registers, each of which hold single 64-bit words. • 8 address registers, each of which hold 20-bit words. • 14 pipelined data processing units, split up for addition, multiplication, computation of reciprocals, and logical operations. • Division is done by multiplying the numerator by the reciprocal of the denominator (i.e. X/Y = X * 1/Y).
Cray Computers (Cont’d) • Backup registers for both the scalar and address registers are used in place of a cache and are regulated by program control as opposed to hardware (registers instead of memory). • Cray computers also implement a special feature named vector chaining.
Cray Computers (Cont’d) • For example, consider the following: v0 = v1 * v2 v3 = v2 * v4 • During this process, there will be a point when operands from V1 and V2 still need to be fetched and send to the pipeline, and results placed into V0 are just leaving the pipeline. The process of vector chaining will send the result from V0 directly to the pipelined adder (at the same time it is stored in the vector register), and combined with the appropriate value from V4. Thus the second instruction will be able to begin before the first is finished and the machine creates 2 results as opposed to 1. This is very similar to the MIPS pipeline and forwarding. The result of this is approximately 3 times the peak performance.
Limitations of Vector Processors • Consider Amdahl's Law, which states that the performance of a parallel program is limited by the sequential part of the program. The speedup can be computed in the following way: 1 Speedup(a,T) = ----------------- a + (1 - a) / T a = the non-vectorizable portion of the program T = number of times the vector execution is faster than the sequential execution • As you can see, as T approaches infinity, this formula approaches 1/a. However, if there is a large portion of the program which can only be implemented in a sequential manner, the speedup is greatly reduced and may become negligible. This is one of the limitations to vector processors.
Since the Cray Y-MP, the super computer market has focused mostly on implementations of massively parallel processing as opposed to vector processor implementations. Vector Processor Implementation
Now implemented in most modern computers under the name SIMD (Single Input, Multiple Data), which is often used in multimedia processing, such as in the DIV-X codecs. The picture to the left shows the development of the Fifth Element, which used graphics exploiting vector processing. Implementation in Multimedia
Implementation Examples • When changing the brightness or contract of an image, a value is added or subtracted from three sets of data (for each r,b and g set). This can be done using vector processing, as multiple sets of data are being operated on. • Data can be loaded in blocks instead of one at a time. Instead of saying "get pixel 1, get pixel 2, etc," it would simply say "get all" or "get n." • Operations here would operate on all data at once, as opposed to individual data points.
Limitations • “Sadly, many SIMD designers are hampered by design considerations outside their control. One of these considerations is the cost of adding registers for holding the data to be processed. Ideally one would want the SIMD units of a CPU to have their own registers, but many are forced for practical reasons to re-use existing CPU registers - typically the floating point registers. These tend to be 64-bits in size, smaller than optimal for SIMD use, as well as leading to problems if the code attempts to use both SIMD and normal floating point instructions at the same time - at which point the units fight over the registers.” (http://en.wikipedia.org/wiki/Vector_processor)
Uses Today • Today, you can find SIMD/Vector Processing in most computers, including Intel, AMD, Power PC, MIPS MDMX and MIPS-3D. However, most software does not exploit these instructions. Computer Graphics is one exception to this, although as graphics cards evolve, these instructions may fall into even less use.
Uses (Cont’d) • "CSI Media Architecture. The Complex Streamed Instruction Set Architecture (CSI) is a memory-to-memory vector architecture targeted at multimedia applications. A single CSI instruction can process data streams of arbitrary length and, in addition to traditional arithmetic and logical operations, performs data accesses, conversion between storage and computation formats (packing and unpacking), and complex arithmetic hardwired computation. The main new features of the CSI are elimination of the vector sectioning instructions, elimination of the packing/unpacking instructions, and introduction of new complex media related arithmetic instructions.“ (http://ce.et.tudelft.nl/iliad/)
VECTOR PROCESSING - EXAMPLE • Consider the following vector-multiplication problem: X * Y = Z, where X, Y, and Z are 100- value vectors (arrays of size 100). • In FORTRAN (to help visualize the connection to the Vector and MIPS Pseudo-Code) this would be written as: DO 10 I = 1, 100 Z(I) = X(I) * Y(I) 10 CONTINUE
Example (Cont’d) • Were this to be implemented in a MIPS machine, each addition would take 4 clock-cycles. The entire loop would be in excess of 400 cycles. • Were this to be implemented in a Vector Processing machine, first, a number of elements from X and a number from Y would be loaded into separate vector registers (can be done simultaneously).
Example (Cont’d) • Next, the multiply pipeline would begin taking in elements from X and Y. After a single clock-cycle, another set of elements would be fed into this pipeline. After 4 clock-cycles the first result would be completed and stored in vector register Z. The second result would be completed in clock-cycle 5, and so on. • Finally, once all this is complete, the values are taken from vector register Z and stored in main memory. • The time it takes for the multiplication by itself is a mere 103 clock-cycles.
PSEUDO CODE - VECTOR PROCESSING • VLOAD X VR1 //loading X into VR1, a vector register VLOAD Y VR2 //loading Y into VR2, a vector register VMULT VR1 VR2 VR3 //vector multiplying VR1 by VR2, storing results in VR3 VSTORE VR3 Z //store vector register VR3 into main memory as Z
PSEUDO CODE – MIPS • LW X[i], $a0 //load first element of X into a register • LW Y[i], $a1 //load first element of Y into a register • “MULT” $a2, $a0, $a1 //multiply $a0 and $a1 and store result in $a2 • SW $a2, Z[i] //store $a2 into memory • //Repeat 100 times
SUMMARY • The Vector machine is faster at performing mathematical operations on larger vectors than is the MIPS machine. • The Vector processing computer’s vector register architecture makes it better able to compute vast amounts of data quickly.
CONCLUSIONS • While Vector Processing is not widely popular today, it still represents a milestone in supercomputing achievement. • It is still in use today in home PC’s as SIMD units which augment the scalar CPU when necessary (usually multi-media applications).
Sources • http://research.microsoft.com/users/gbell/craytalk/sld061.htm • http://encyclopedia.thefreedictionary.com • http://en.wikipedia.org/wiki/Vector_processor • http://ce.et.tudelft.nl/iliad/ • http://csep1.phy.ornl.gov/ca/node24.html • http://www.crhc.uiuc.edu/ece412/lectures/lecture8.PDF • http://www.pcc.qub.ac.uk/tec/courses/cray/ohp/CRAY-slides_3.html