VECTOR PROCESSING
VECTOR PROCESSING. Τσόλκας Χρήστος & Αντωνίου Χρυσόστομος. Contents. Introduction Vector Processor Definition Components & Properties of Vector Processors Advantages/Disadvantages of Vector Processors Vector Machines & Architectures Virtual Processors Model Vectorization Inhibitors


VECTOR PROCESSING
E N D
Presentation Transcript
VECTOR PROCESSING Τσόλκας Χρήστος & Αντωνίου Χρυσόστομος
Contents • Introduction • Vector Processor Definition • Components & Properties of Vector Processors • Advantages/Disadvantages of Vector Processors • Vector Machines & Architectures • Virtual Processors Model • Vectorization Inhibitors • Improving Performance • Vector Metrics • Applications
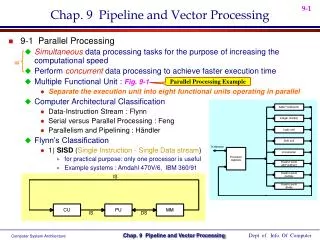
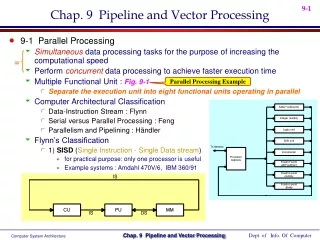
Architecture Classification • SISD • Single Instruction Single Data • SIMD • Single Instruction Multiple Data • MIMD • Multiple Instruction Multiple Data • MISD • Multiple Instruction Single Data
Alternative Forms of Machine Parallelism • Instruction Level Parallelism (ILP) • Thread Level Parallelism (TLP) • vector Data Parallelism (DP)
Drawbacks of ILP and TLP • Coherency • Synchronization • Large Overhead • instruction fetch and decode: at some point, its hard to fetch and decode more instructions per clock cycle • cache hit rate: some long-running (scientific) programs have very large data sets accessed with poor locality; others have continuous data streams (multimedia) and hence poor locality
What is a Vector Processor? • Provides high-level operations that work on vectors • Vector is a linear array of numbers • Type of number can vary, but usually 64 bit floating point (IEEE 754, 2’s complement) • Length of the array also varies depending on hardware • Example vectors would be 64 or 128 elements in length • Small vectors (e.g. MMX/SSE) are about 4 elements in length
Components of Vector Processor • Vector Registers • Fixed length bank holding a single vector • Has at least 2 read and 1 write ports • Typically 8-32 vector registers, each holding 64-128 64-bit elements • Vector Functional Units • Fully pipelined, start new operation every clock • Typically 4-8 FUs: FP add, FP mult, FP reciprocal, integer add, logical, shift • Scalar Registers • Single element for FP scalar or address • Load Store Units
Vector Processor Properties • Computation of each result must be independent of previous results • Single vector instruction specifies a great deal of work • Equivalent to executing an entire loop • Vector instructions must access memory in a known access pattern • Many control hazards can be avoided since the entire loop is replaced by a vector instruction
Advantages of Vector Processors • Increase in code density • Decrease in total number of instructions • Data is organized in patterns which is easier for the hardware to compute • Simple loops are replaced with vector instructions, hence decrease in overhead • Scalable
Disadvantages of Vector Processors • Expansion of the Instruction Set Architecture (ISA) is needed • Additional vector functional units and registers • Modification of the memory system
Example Vector Machines • Machine Year Clock Regs Elements FUs LSUs • Cray 1 1976 80 MHz 8 64 6 1 • Cray XMP 1983 120 MHz 8 64 8 2 L, 1 S • Cray YMP 1988 166 MHz 8 64 8 2 L, 1 S • Cray C-90 1991 240 MHz 8 128 8 4 • Cray T-90 1996 455 MHz 8 128 8 4 • Conv. C-1 1984 10 MHz 8 128 4 1 • Conv. C-4 1994 133 MHz 16 128 3 1 • Fuj. VP2001982 133 MHz 8-256 32-1024 3 2 • NEC SX/2 1984 160 MHz 8+8K 256+var 16 8 • NEC SX/3 1995 400 MHz 8+8K 256+var 16 8
Vector Instruction Execution • Static scheduling • Prefetching • Dynamic scheduling
Styles of Vector Architectures • Memory-memory vector processors • All vector operations are memory to memory • CDC Star 100 • Vector-register processors • All vector operations between vector registers • Vector equivalent of load-store architecture • Includes all vector machines since late 1980s • Cray, Convex, Fujitsu, Hitachi, NEC
Memory operations • Load/store operations move groups of data between registers and memory • Three types of addressing • Unit stride access • Fastest • Non-unit (constant) stride access • Indexed (gather-scatter) • Vector equivalent of register indirect • Increases number of programs that vectorize
Vector Stride • Position of the elements we want in memory may not be sequential • Consider following code: Do 10 I=1, 100 Do 10 j =1, 100 A(I,j) = 0.0 Do 10 k =1,100 A(I,j) = A(I,j) + B(I,k)*C(k,j) 10 Continue
Virtual Processor Model • Vector operations are SIMD (single instruction multiple data)operations • Each element is computed by a virtual processor (VP) • Number of VPs given by vector length
Vectorization Example DO 100 I = 1, N A(I) = B(I) + C(I) 100 CONTINUE • Scalar process: • B(1) will be fetched from memory • C(1) will be fetched from memory • A scalar add instruction will operate on B(1) and C(1) • A(1) will be stored back to memory • Step (1) to (4) will be repeated N times.
Vectorization Example DO 100 I = 1, N A(I) = B(I) + C(I) 100 CONTINUE • Vector process: • A vector of values in B(I) will be fetched from memory • A vector of values in C(I) will be fetched from memory. • A vector add instruction will operate on pairs of B(I) and C(I) values. • After a short start-up time, stream of A(I) values will be stored back to memory, one value every clock cycle.
Example (2): Y=aX+Y Scalar Code: LD F0, A ADDI R4,Rx, #512 ; Last addr Loop: LD F2, 0(Rx) MULTD F2, F0, F2 ; A * X[I] LD F4, 0(Ry) ADDD F4, F2, F4 ; + Y[I] SD 0(Ry), F4 ADDI Rx, Rx, #8 ; Inc index ADDI Ry, Ry, #8 SUB R20, R4, Rx BNEZ R20, Loop Vector Code: LD F0, A LV V1, Rx ; Load vecX MULTSV V2, F0, V1 ; Vec Mult LV V3, Ry ; Load vecY ADDV V4, V2, V3 ; Vec Add SV Ry, V4 ; Store result 64 is element size .So we need no loop now 1+5*64=321 operations Vector/Scalar=1.8x Loop goes 64 times. 2+9*64=578 operations
Vector Length • We would like loops to iterate the same number of times that we have elements in a vector • But unlikely in a real program • Also the number of iterations might be unknown at compile time • Problem: n, number of iterations, greater than MVL (Maximum Vector Length) • Solution: Strip Mining • Create one loop that iterates a multiple of MVL times • Create a final loop that handles any remaining iterations, which must be less than MVL
Strip Mining Example low=1 VL = (n mod MVL) ; Find odd-sized piece Do 1 j=0,(n/MVL) ; Outer Loop Do 10 I = low, low+VL-1 ; runs for length VL Y(I) = a*X(I)+Y(I) ; Main operation 10 continue low = low + VL VL = MVL 1 Continue Executes loop in blocks of MVL Inner loop can be vectorized
Strip Mining Example low=1 ; low=1 VL = (n mod MVL) ; VL=2 Do 1 j=0,(n/MVL) ; j=1 Do 10 I = low, low+VL-1 ; I=1 .. 2 Y(I) = a*X(I)+Y(I) ; Υ(1) and Υ(2) 10 continue ; low = low + VL ; low=3 VL = MVL ; VL=32 1 Continue ;
Strip Mining Example low=1 ; low=3 VL = (n mod MVL) ; VL=32 Do 1 j=0,(n/MVL) ; j=2 Do 10 I = low, low+VL-1 ; I=3 .. 34 Y(I) = a*X(I)+Y(I) ; Υ(3) .. Υ(34) 10 continue ; low = low + VL ; low=35 VL = MVL ; VL=32 1 Continue ;
Strip Mining Example low=1 ; low=99 VL = (n mod MVL) ; VL=32 Do 1 j=0,(n/MVL) ; j=4 Do 10 I = low, low+VL-1 ; I=99 .. 130 Y(I) = a*X(I)+Y(I) ; Υ(99) .. Υ(130) 10 continue ; low = low + VL ; low=130 VL = MVL ; VL=32 1 Continue ;
Vectorization Inhibitors • Subroutine calls • I/O Statements • Character data • Unstructured branches • Data dependencies • Complicated programming
Vectorization Inhibitors • Subroutine calls • I/O Statements • Character data • Unstructured branches • Data dependencies • Complicated programming
Subroutine callsSolution: Inline inline double radius( double x, double y, double z ) { return sqrt( x*x + y*y + z*z ); } .. int main() { .. for( int i=1; i<=n; ++i ){ r[i] = radius( x[i], y[i], z[i] ); } .. }
Vectorization Inhibitors • Subroutine calls • I/O Statements • Character data • Unstructured branches • Data dependencies • Complicated programming
Vectorization Inhibitors • Subroutine calls • I/O Statements • Character data • Unstructured branches • Data dependencies • Complicated programming
Vectorization Inhibitors • Subroutine calls • I/O Statements • Character data • Unstructured branches • Data dependencies • Complicated programming
Vectorization Inhibitors • Subroutine calls • I/O Statements • Character data • Unstructured branches • Data dependencies • Complicated programming
Dependence Example do i=2,n a(i) = a(i-1) enddo do i=2,n temp(i) = a(i-1) ! temporary vector enddo temp(1) = a(1) do i=1,n a(i) = temp(i) enddo
Vectorization Inhibitors • Subroutine calls • I/O Statements • Character data • Unstructured branches • Data dependencies • Complicated programming
Improving Vector Performance • Better compiler techniques • As with all other techniques, we may be able to rearrange code to increase the amount of vectorization • Techniques for accessing sparse matrices • Hardware support to move between dense (no zeros), and normal (include zeros) representations • Chaining • Same idea as forwarding in pipelining • Consider: • MULTV V1, V2, V3 • ADDV V4, V1, V5 • ADDV must wait for MULTV to finish • But we could implement forwarding; as each element from the MULTV finishes, send it off to the ADDV to start work
Chaining Example 7 64 6 64 Total = 141 Unchained MULTV ADDV 7 64 Chained MULTV Total = 77 6 64 ADDV 6 and 7 cycles are start-up-times of the adder and multiplier Every vector processor today performs chaining
Improving Performance • Conditionally Executed Statements • Consider the following loop • Do 100 i=1, 64 • If (a(i) .ne. 0) then • a(i)=a(i)-b(i) • Endif • 100 continue • Not vectorizable due to the conditional statement • But we could vectorize this if we could somehow only include in the vector operation those elements where a(i) != 0
Conditional Execution • Solution: Create a vector mask of bits that corresponds to each vector element • 1=apply operation • 0=leave alone • As long as we properly set the mask first, we can now vectorize the previous loop with the conditional • Implemented on most vector processors today
Conditional Execution lv v1 ra ;load vector into v1 lv v2 rb ;load vector into v2 id f0 #0 ;f0=0 vsnes f0 v1 ;set VM to 1 if v1(i)!=0 vsub v1 v1 v2 ;sub. under vector mask cvm ;set vector mask all to 1 sv ra v1 ; store the reslult to a
Common Vector Metrics • Rn: MFLOPS rate on an infinite-length vector • Real problems do not have unlimitend vector lengths, and the start-up penalties encountered in real problems will be larger • (Rn is the MFLOPS rate for a vector of length n) • N1/2: The vector length needed to reach one-half of Rn • a good measure of the impact of start-up • NV: The vector length needed to make vector mode faster than scalar mode • measures both start-up and speed of scalars relative to vectors, quality of connection of scalar unit to vector unit
Applications • Linear Algebra • Image processing (Convolution, Composition, Compressing, etc.) • Audio synthesis • Compression • Cryptography • Speech recognition
Applications in multimedia KernelVector length • Matrix transpose/multiply # vertices at once • DCT (video, communication) image width • FFT (audio) 256-1024 • Motion estimation (video) image width,iw/16 • Gamma correction (video) image width • Median filter (image processing) image width • Separable convolution (img. proc.) image width
Vector Summary • Alternate model,doesn’t rely on caches as does Out-Of-Order and superscalar implementations • Handles memory in a more organized way • Powerful instructions that replace loops • Cope with multimedia applications • Ideal architecture for scientific simulation