IRAM Original Plan
310 likes | 337 Views
Explore the IRAM original plan for a processor architecture tailored for embedded/portable systems running media applications. This processor is based on media processing and embedded DRAM, offering a simple, scalable, and efficient design with good compiler targeting. Discover the microprocessor prototype specifications, architecture details, modular vector unit design, power consumption strategies, VIRAM compiler features, and in-depth updates on testing and verification efforts. Stay informed about the progress and upcoming tasks related to the VIRAM-1 project.

IRAM Original Plan
E N D
Presentation Transcript
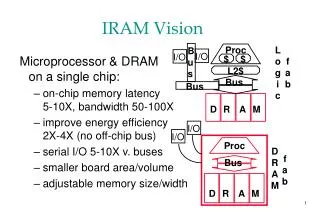
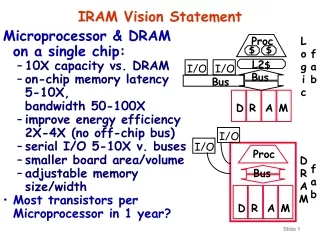
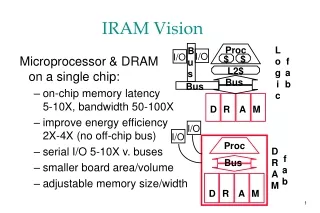
IRAM Original Plan • A processor architecture for embedded/portable systems running media applications • Based on media processing and embedded DRAM • Simple, scalable, and efficient • Good compiler target • Microprocessor prototype with • 256-bit media processor, 16 MBytes DRAM • 150 million transistors, 290 mm2 • 3.2 Gops, 2W at 200 MHz • Industrial strength compiler • Implemented by 6 graduate students
Architecture Details Review • MIPS64™ 5Kc core (200 MHz) • Single-issue core with 6 stage pipeline • 8 KByte, direct-map instruction and data caches • Single-precision scalar FPU • Vector unit (200 MHz) • 8 KByte register file (32 64b elements per register) • 4 functional units: • 2 arithmetic (1 FP), 2 flag processing • 256b datapaths per functional unit • Memory unit • 4 address generators for strided/indexed accesses • 2-level TLB structure: 4-ported, 4-entry microTLB and single-ported, 32-entry main TLB • Pipelined to sustain up to 64 pending memory accesses
Vector Reg. Elements Vector Reg. Elements Vector Reg. Elements Vector Reg. Elements Integer Datapath 0 Integer Datapath 1 Integer Datapath 0 Integer Datapath 1 Integer Datapath 0 Integer Datapath 1 Integer Datapath 1 Integer Datapath 0 FP Datapath FP Datapath FP Datapath FP Datapath Flag Reg. Elements & Datapaths Flag Reg. Elements & Datapaths Flag Reg. Elements & Datapaths Flag Reg. Elements & Datapaths Xbar IF Xbar IF Xbar IF Xbar IF 64b 64b 64b 64b Modular Vector Unit Design 256b • Single 64b “lane” design replicated 4 times • Reduces design and testing time • Provides a simple scaling model (up or down) without major control or datapath redesign • Most instructions require only intra-lane interconnect • Tolerance to interconnect delay scaling Control
“VIRAM-7MB” 4 lanes, 8 Mbytes 190 mm2 3.2 Gops at 200 MHz(32-bit ops) Alternative Floorplans (1) “VIRAM-2Lanes” 2 lanes, 4 Mbytes 120 mm2 1.6 Gops at 200 MHz “VIRAM-Lite” 1 lane, 2 Mbytes 60 mm2 0.8 Gops at 200 MHz
Power Consumption • Power saving techniques • Low power supply for logic (1.2 V) • Possible because of the low clock rate (200 MHz) • Wide vector datapaths provide high performance • Extensive clock gating and datapath disabling • Utilizing the explicit parallelism information of vector instructions and conditional execution • Simple, single-issue, in-order pipeline • Typical power consumption: 2.0 W • MIPS core: 0.5 W • Vector unit: 1.0 W (min ~0 W) • DRAM: 0.2 W (min ~0 W) • Misc.: 0.3 W (min ~0 W)
VIRAM Compiler • Based on the Cray’s PDGCS production environment for vector supercomputers • Extensive vectorization and optimization capabilities including outer loop vectorization • No need to use special libraries or variable types for vectorization Frontends Optimizer Code Generators C T3D/T3E Cray’s PDGCS C++ C90/T90/SV1 Fortran95 SV2/VIRAM
The IRAM Team • Hardware: • Joe Gebis, Christoforos Kozyrakis, Ioannis Mavroidis, Iakovos Mavroidis, Steve Pope, Sam Williams • Software: • Alan Janin, David Judd, David Martin, Randi Thomas • Advisors: • David Patterson, Katherine Yelick • Help from: • IBM Microelectronics, MIPS Technologies, Cray, Avanti
IRAM update • Verification of chip • Scheduled tape-out • Package • Clock cycle time/Power Estimates • Demo board
Current Debug / Verification Efforts Current • m5kc+fpu : program simulation on RTL • m5kc+vu+xbar+dram : program simulation on RTL • Arithmetic Unit (AU) : corner cases + random values on VERILOG netlist • Vector Register File : only a few cases have been (layout) spiced, 100’s of tests were run thru timemill. To Do • Entire VIRAM-1 : program simulation on RTL (m5kc+vu+fpu+xbar+dram)
Progress • MIPS testsuite is about 1700 test-mode combinations + <100 FP tests-mode combinations that are valid for the VIRAM-1 FPU • Additionally, entire VIRAM-1 testsuite has about 2700 tests, ~ 24M instructions, and 4M lines of asm code • Vector unit currently passes about all of them for a big endian, user mode. • There are about 200 exception tests for both coprocessors • Kernel tests are long, but there are only about 100 of them • Arithmetic Kernels must be run on the combined design • Additional microarchitecture specific, and vector TAP tests have been run. • Currently running random tests to find bugs. Entire VIRAM-1 Testsuite vsim ISA XC’s Arith. Kernels TLB Kernels random compiled m5kc MIPS Testsuite Testsuite on Synthesized FPU Subset of VIRAM-1 Testsuite + MIPS FPU Testsuite m5kc+fpu Testsuite on Synthesized ISA MIPS XC’s Arith. Kernels random compiled Vector Subset of VIRAM-1 Testsuite m5kc+vu+ xbar+dram ISA XC’s Arith. Kernels TLB Kernels random compiled Testsuite on Synthesized VIRAM-1 (superset of above) Entire VIRAM-1 Testsuite Testsuite on Synthesized
IRAM update: Schedule • Scheduled tape-out was May 1, 2001 • Based on schedule IBM was expecting June, July 2001 • We think which we’ll make June 2001
IRAM update: Package/Impact • Kyocera 304 pin Quad Flat Pack • Cavity is 20.0 x 20.0 mm • Must allow space around die - 1.2 mm • Simplify bonding by putting pads on all 4 sides • Need to shrink DRAM to make it fit • Simplify routing by allowing extra height in lane: 14 MB=>3.0 mm, 13 MB=>3.8, 12=>4.8 => 13 MB +- 1 MB, depending on how routing (Also shows strength of design style in that can adjust memory, die size at late stage)
Floorplan • Technology: IBM SA-27E • 0.18mm CMOS • 6 metal layers (copper) • 280 mm2 die area • 18.72 x 15 mm • ~200 mm2 for memory/logic • DRAM: ~140 mm2 • Vector lanes: ~50 mm2 • Transistor count: >100M • Power supply • 1.2V for logic, 1.8V for DRAM 15 mm 18.7 mm
IRAM update: Clock cycle/power • Clock cycle rate was 200 MHz, 1.2v for logic to keep at 2W total • MIPS synthesizable core will not run at 200 MHz at 1.2v • Keep 2W (1.2v) target, and whatever clock rate (~170 v. 200 MHz), or keep 200 MHz clock rate target, and increase voltage to whatever it needs (1.8v?)? • Plan is to stay with 1.2v since register file designed at 1.2v
MIPS Demo Board • Runs Linix, has Ethernet +I/O • Main board + daughter card = MIPS CPU chip + interfaces • ISI designs VIRAM daughter card? • Meeting with ISI soon to discuss
Embedded DRAM in the News • Sony ISSCC 2001 • 462-mm2 chip with 256-Mbit of on-chip embedded DRAM (8X Emotion engine) • 0.18-micron design rules • 21.7 x 21.3-mm and contains 287.5 million transistors • 2,000-bit internal buses can deliver 48 gigabytes per second of bandwidth • Demonstrated at Siggraph 2000 • Used in multiprocessor graphics system?
High Confidence Computing? • High confidence => a system can be trusted or relied upon? • You can't rely on a system that's down • High Confidence includes more than availability, but availability a prerequisite to high confidence?
Goals,Assumptions of last 15 years • Goal #1: Improve performance • Goal #2: Improve performance • Goal #3: Improve cost-performance • Assumptions • Humans are perfect (they don’t make mistakes during wiring, upgrade, maintenance or repair) • Software will eventually be bug free (good programmers write bug-free code) • Hardware MTBF is already very large, and will continue to increase (~100 years between failures)
Lessons learned from Past Projects for High Confidence Computing • Major improvements in Hardware Reliability • 1990 Disks 50,000 hour MTBF to 1,200,000 in 2000 • PC motherboards from 100,000 to 1,000,000 hours • Yet Everything has an error rate • Well designed and manufactured HW: >1% fail/year • Well designed and tested SW: > 1 bug / 1000 lines • Well trained, rested people doing routine tasks: >1% • Well run collocation site (e.g., Exodus): 1 power failure per year, 1 network outage per year • Components fail slowly • Disks, Memory, software give indications before fail (Interfaces don’t pass along this information)
Lessons learned from Past Projects for High Confidence Computing • Maintenance of machines (with state) expensive • ~10X cost of HW per year • Stateless machines can be trivial to maintain (Hotmail) • System administration primarily keeps system available • System + clever human = uptime • Also plan for growth, fix performance bugs, do backup • Software upgrades necessary, dangerous • SW bugs fixed, new features added, but stability? • Admins try to skip upgrades, be the last to use one
Lessons learned from Past Projects for High Confidence Computing • Failures due to people up, hard to measure • VAX crashes ‘85, ‘93 [Murp95]; extrap. to ‘01 • HW/OS 70% in ‘85 to 28% in ‘93. In ‘01, 10%? • How get administrator to admit mistake? (Heisenberg?)
Lessons learned from Past Projects for High Confidence Computing • Component performance varies • Disk inner track vs. outer track: 1.8X Bandwidth • Refresh of DRAM • Daemon processes in nodes of cluster • Error correction, retry on some storage accesses • Maintenance events in switches (Interfaces don’t pass along this information) • Know how to improve performance (and cost) • Run system against workload, measure, innovate, repeat • Benchmarks standardize workloads, lead to competition, evaluate alternatives; turns debates into numbers
An Approach to High Confidence "If a problem has no solution, it may not be a problem, but a fact, not be solved, but to be coped with over time." Shimon Peres, quoted in Rumsfeld's Rules • Rather than aim towards (or expect) perfect hardware, software, & people, assume flaws • Focus on Mean Time To Repair (MTTR), for whole system including people who maintain it • Availability = MTTR / MTBF, so 1/10th MTTR just as valuable as 10X MTBF • Improving MTTR and hence availability should improve cost of administration/maintenance as well
An Approach to High Confidence • Assume we have a clean slate, not constrained by 15 years of cost-performance optimizations • 4 Parts to Time to Repair: 1) Time to detect error, 2) Time to pinpoint error (“root cause analysis”), 3) Time to chose try several possible solutions fixes error, and 4) Time to fix error
An Approach to High Confidence 1) Time to Detect errors • Include interfaces that report faults/errors from components • May allow application/system to predict/identify failures • Periodic insertion of test inputs into system with known results vs. wait for failure reports
An Approach to High Confidence 2) Time to Pinpoint error • Error checking at edges of each component • Design each component so it can be isolated and given test inputs to see if performs • Keep history of failure symptoms/reasons and recent behavior (“root cause analysis”)
An Approach to High Confidence • 3) Time to try possible solutions: • History of errors/solutions • Undo of any repair to allow trial of possible solutions • Support of snapshots, transactions/logging fundamental in system • Since disk capacity, bandwidth is fastest growing technology, use it to improve repair? • Caching at many levels of systems provides redundancy that may be used for transactions?
An Approach to High Confidence 4) Time to fix error: • Create Repair benchmarks • Competition leads to improved MTTR • Include interfaces that allow Repair events to be systematically tested • Predictable fault insertion allows debugging of repair as well as benchmarking MTTR • Since people make mistakes during repair, “undo” for any maintenance event • Replace wrong disk in RAID system on a failure; undo and replace bad disk without losing info • Undo a software upgrade
Other Ideas for High Confidence • Continuous preventative maintenance tasks? • ~ 10% resources to repair errors before fail • Resources reclaimed when failure occurs to mask performance impact of repair? • Sandboxing to limit the scope of an error? • Reduce error propagation since can have large delay between fault and failure discovery • Processor level support for transactions? • Today on failure try to clean up shared state • Common failures: not or repeatedly freeing memory, data structure inconsistent, forget release latch • Transactions make failure rollback reliable?
Other Ideas for High Confidence • Use interfaces that report, expect performance variability vs. expect consistency? • Especially when trying to repair • Example: work allocated per server based on recent performance vs. based on expected performance • Queued interfaces, flow control accommodate performance variability, failures? • Example: queued communication vs. Barrier/Bulk Synchronous communication for distributed program
Conclusion • New foundation to reduce MTTR • Cope with fact that people, SW, HW fail (Peres) • Transactions/snapshots to undo failures, bad repairs • Repair benchmarks to evaluate MTTR innovations • Interfaces to allow error insertion, input insertion, report module errors, report module performance • Module I/O error checking and module isolation • Log errors and solutions for root cause analysis, pick approach to trying to solve problem • Significantly reducing MTTR => increased availability=> foundation for High Confidence Computing