Optimal Discretization of Random Variables Using Normal Distribution Mapping
110 likes | 232 Views
This paper explores the discretization of sample values for random variables X and Y by mapping them to normal distributions. The aim is to achieve a uniform representation of their relationship through appropriate partitioning points, identified using Equation (15). This approach is critical, especially when dealing with multiple random variables, to avoid noise and ensure meaningful data representation. Additionally, the paper details methods to compute mutual information in gene expression data under different treatment conditions, facilitating a deeper understanding of variable interactions.

Optimal Discretization of Random Variables Using Normal Distribution Mapping
E N D
Presentation Transcript
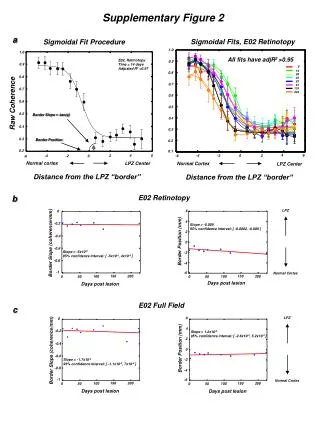
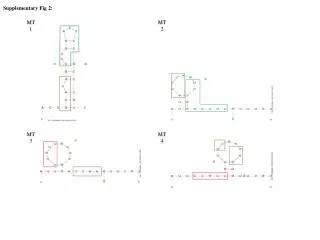
Supplementary Text 2 If the relationship between two random variables X and Y is approximately illustrated in the following figure, then how can we discretize the sample values of them? N(μ1,σ1) Fig. A μ1 t1,1 t1,2 t1,3 t1,4 Fig. B N(μ2,σ2) t2,1 t2,2 t2,3 t2,4 μ2
To uniformly describe the relation ship between X and Y, we can map them to normal distribution. And the corresponding relationship would be change into that illustrated in the figure below. Fig. C N(0,1) 0 t1 t2 t3 t4 Fig. D N(0,1) 0 t1 t2 t3 t4
The data transformation between Figure A and C is implemented with the Equation (14) in the paper. And the data transformation between Figure B and D is also implemented with Equation (14) in the paper. Then our goal is to find the best common partitioning points t1, t2, …, tk. The Purpose of Equation (15) in the paper is to determine the best common partitioning points for both variable X and Y, while simultaneously making both of them as evenly partitioned as possible. The structures of the variables shown in Figure B and D reveal the essence of the relationship between the two random variables of the same kind. This is of more importance when the number of random variables becomes large. It makes the partition not “casual” just in order to adapt to the data, some of which are just noise.
Example 3 The gene expression data is partially listed below. Suppose that Gene #1 and #2 have been divided in the same group G1, while Gene #3, #4, and #5 are in the same group G2.
For the data in the table above, we define 15 vectors as follows.
To compute the mutual information between the two groups G1 and G2about low pressure treatment described in Equation (17) in the paper, we can use the following detailed equation in stead of (17):
To compute the mutual information between the two groups G1 and G2about high pressure treatment described in Equation (18) in the paper, we can use the following detailed equation in stead of (18):
To compute the mutual information between the two groups G1 and G2about bothhigh pressure and the high pressure treatment described in Equation (19) in the paper, we can use the following detailed equation in stead of (19):
To compute the mutual information between the treatment low pressure and the treatment high pressure within the group G1described in Equation (20) in the paper, we can use the following detailed equation in stead of (20):
To compute the mutual information between the treatment low pressure and the treatment high pressure within the group G2described in Equation (20) in the paper, we can use the following detailed equation in stead of (20):