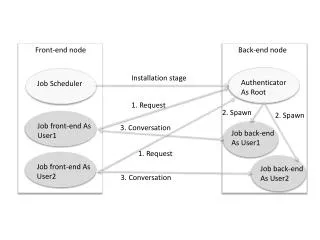
The Front End
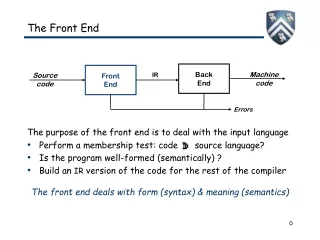
The Front End. The purpose of the front end is to deal with the input language Perform a membership test: code source language? Is the program well-formed (semantically) ? Build an IR version of the code for the rest of the compiler
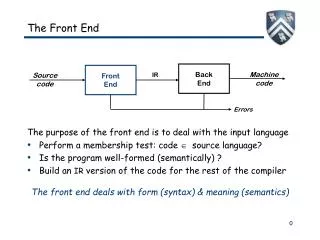

The Front End
E N D
Presentation Transcript
The Front End The purpose of the front end is to deal with the input language Perform a membership test: code source language? Is the program well-formed (semantically) ? Build an IR version of the code for the rest of the compiler The front end deals with form (syntax) & meaning (semantics) Back End Machine code Source code IR Front End Errors
The Front End Implementation Strategy IR Source code tokens Parser Scanner Errors
The Front End Why separate the scanner and the parser? Scanner classifies words Parser constructs grammatical derivations Parsing is harder and slower Separation simplifies the implementation Scanners are simple Scanner leads to a faster, smaller parser stream of characters stream of tokens IR + annotations Parser Scanner microsyntax syntax Errors token is a pair <partofspeech, lexeme> Scanner is only pass that touches every character of the input.
The Big Picture The front end deals with syntax Language syntax is specified with parts of speech, not words Syntax checking matches parts of speech against a grammar Simple expression grammar 1. goalexpr 2. exprexpr op term 3. | term 4. termnumber 5. | id 6. op+ 7. | – S = goal T = { number, id, +, - } N = { goal, expr, term, op} P = {1, 2, 3, 4, 5, 6, 7} parts of speech syntactic variables The scanner turns a stream of characters into a stream of words, and classifies them with their part of speech.
The Big Picture Why study automatic scanner construction? Avoid writing scanners by hand Harness theory Goals: To simplify specification & implementation of scanners To understand the underlying techniques and technologies compile time source code parts of speech & words Scanner Represent words as indices into a global table tables or code design time specifications Scanner Generator Specifications written as “regular expressions”
Regular Expressions We constrain programming languages so that the spelling of a word always implies its part of speech The rules that impose this mapping form a regular language Regular expressions (REs) describe regular languages Regular Expression (over alphabet ) is a RE denoting the set {} If a is in , then a is a RE denoting {a} If x and y are REs denoting L(x) and L(y) then x |y is an RE denoting L(x) L(y) xy is an RE denoting L(x)L(y) x* is an RE denoting L(x)* Precedence is closure, then concatenation, then alternation
Regular Expressions How do these operators help? Regular Expression (over alphabet ) is a RE denoting the set {} If a is in , then a is a RE denoting {a} the spelling of any specific word is an RE If x and y are REs denoting L(x) and L(y) then x |y is an RE denoting L(x) L(y) any finite list of words can be written as an RE (w0 | w1 | … | wn) xy is an RE denoting L(x)L(y) x* is an RE denoting L(x)* we can use concatenation & closure to write more concise patterns and to specify infinite sets that have finite descriptions
Examples of Regular Expressions Identifiers: Letter (a|b|c| … |z|A|B|C| … |Z) Digit (0|1|2| … |9) Identifier Letter ( Letter | Digit )* Numbers: Integer (+|-|) (0| (1|2|3| … |9)(Digit *) ) Decimal Integer . Digit * Real ( Integer | Decimal ) E (+|-|) Digit * Complex (Real,Real ) Numbers can get much more complicated! underlining indicates a letter in the input stream
Regular Expressions We use regular expressions to specify the mapping of words to parts of speech for the lexical analyzer Using results from automata theory and theory of algorithms, we can automate construction of recognizers from REs We study REs and associated theory to automate scanner construction ! Fortunately, the automatic techiques lead to fast scanners used in text editors, URL filtering software, …
Consider the problem of recognizing ILOC register names Register r (0|1|2| … | 9)(0|1|2| … | 9)* Allows registers of arbitrary number Requires at least one digit RE corresponds to a recognizer (or DFA) Transitions on other inputs go to an error state, se Example (0|1|2| … 9) (0|1|2| … 9) r S0 S1 S2 Recognizer for Register
DFA operation Start in state S0 & make transitions on each input character DFA accepts a word x iff x leaves it in a final state (S2 ) So, r17 takes it through s0, s1, s2and accepts r takes it through s0, s1 and fails a takes it straight to se Example (continued) (0|1|2| … 9) (0|1|2| … 9) r S0 S1 S2 Recognizer for Register
Example (continued) To be useful, the recognizer must be converted into code Char next character State s0 while (Char EOF) State (State,Char) Char next character if (State is a final state) then report success else report failure Skeleton recognizer Table encoding the RE O(1) cost per character (or per transition)
Example (continued) We can add “actions” to each transition Char next character State s0 while (Char EOF) Next (State,Char) Act (State,Char) perform action Act State Next Char next character if (State is a final state) then report success else report failure Skeleton recognizer Table encoding RE Typical action is to capture the lexeme
rDigit Digit* allows arbitrary numbers Accepts r00000 Accepts r99999 What if we want to limit it to r0 through r31 ? Write a tighter regular expression Register r ( (0|1|2) (Digit | ) | (4|5|6|7|8|9) | (3|30|31) ) Register r0|r1|r2| … |r31|r00|r01|r02| … |r09 Produces a more complex DFA DFA has more states DFA has same costper transition (or per character) DFA has same basic implementation What if we need a tighter specification? More states implies a larger table. The larger table might have mattered when computers had 128 KB or 640 KB of RAM. Today, when a cell phone has megabytes and a laptop has gigabytes, the concern seems outdated.
Tighter register specification (continued) The DFA for Register r ( (0|1|2) (Digit | ) | (4|5|6|7|8|9) | (3|30|31) ) Accepts a more constrained set of register names Same set of actions, more states (0|1|2| … 9) S2 S3 0,1,2 r 0,1 3 S0 S1 S5 S6 4,5,6,7,8,9 S4
Tighter register specification (continued) Table encoding RE for the tighter register specification
Tighter register specification (continued) (0|1|2| … 9) S2 S3 0,1,2 r 0,1 3 S0 S1 S5 S6 4,5,6,7,8,9 S4
0…9 r 0…9 s0 sf Table-Driven Scanners Common strategy is to simulate DFA execution • Table + Skeleton Scanner • So far, we have used a simplified skeleton • In practice, the skeleton is more complex • Character classification for table compression • Building the lexeme • Recognizing subexpressions • Practice is to combine all the REs into one DFA • Must recognize individual words without hitting EOF state s0 ; while (state exit) do char NextChar( ) // read next character state (state,char); // take the transition
Table-Driven Scanners Character Classification • Group together characters by their actions in the DFA • Combine identical columns in the transition table, • Indexing by class shrinks the table • Idea works well in ASCII (or EBCDIC) • compact, byte-oriented character sets • limited range of values • Not clear how it extends to larger character sets (unicode) state s0 ; while (state exit) do char NextChar( ) // read next character cat CharCat(char) // classify character state (state,cat) // take the transition
Table-Driven Scanners Building the Lexeme • Scanner produces syntactic category (part of speech) • Most applications want the lexeme (word), too • This problem is trivial • Save the characters state s0 lexeme empty string while (state exit) do char NextChar( ) // read next character lexeme lexeme + char // concatenate onto lexeme cat CharCat(char) // classify character state (state,cat) // take the transition
Table-Driven Scanners Choosing a Category from an Ambiguous RE • We want one DFA, so we combine all the REs into one • Some strings may fit RE for more than 1 syntactic category • Keywords versus general identifiers • Would like to encode them into the RE & recognize them • Scanner must choose a category for ambiguous final states • Classic answer: specify priority by order of REs (return 1st) Alternate Implementation Strategy (Quite popular) • Build hash table of keywords & fold keywords into identifiers • Preload keywords into hash table • Makes sense if • Scanner will enter all identifiers in the table • Scanner is hand coded • Othersise, let the DFA handle them (O(1) cost per character) Separate keyword table can make matters worse
Table-Driven Scanners Scanning a Stream of Words • Real scanners do not look for 1 word per input stream • Want scanner to find all the words in the input stream, in order • Want scanner to return one word at a time • Syntactic Solution: can insist on delimiters • Blank, tab, punctuation, … • Do you want to force blanks everywhere? in expressions? • Implementation solution • Run DFA to error or EOF, back up to accepting state • Need the scanner to return token, not boolean • Token is <Part of Speech,lexeme> pair • Use a map from DFA’s state to Part of Speech (PoS)
Table-Driven Scanners Handling a Stream of Words // recognize words state s0 lexeme empty string clear stack push (bad) while (state se) do char NextChar( ) lexeme lexeme + char if state ∈ SA then clear stack push (state) cat CharCat(char) state (state,cat) end; // clean up final state while (state ∉ SA and state ≠ bad) do state ← pop() truncate lexeme roll back the input one character end; // report the results if (state ∈ SA ) then return <PoS(state),lexeme> else return invalid Need a clever buffering scheme, such as double buffering to support roll back
Avoiding Excess Rollback • Some REs can produce quadratic rollback • Consider ab | (ab)* c and its DFA • Input “ababababc” • s0, s1, s3, s4, s3, s4, s3, s4, s5 • Input “abababab” • s0, s1, s3, s4, s3, s4, s3, s4, rollback 6 characters • s0, s1, s3, s4, s3, s4, rollback 4 characters • s0, s1, s3, s4, rollback 2 characters • s0, s1, s3 • This behavior is preventable • Have the scanner remember paths that fail on particular inputs • Simple modification creates the “maximal munch scanner” s0 DFA for ab | (ab)* c a c s1 b a s3 s2 a b c s4 s5 c Not too pretty
Maximal Munch Scanner // recognize words state s0 lexeme empty string clear stack push (bad,bad) while (state se) do char NextChar( ) InputPos InputPos + 1 lexeme lexeme + char if Failed[state,InputPos] then break; if state ∈ SA then clear stack push (state,InputPos) cat CharCat(char) state (state,cat) end // clean up final state while (state ∉ SA and state ≠ bad) do Failed[state,InputPos) true 〈state,InputPos〉← pop() truncate lexeme roll back the input one character end // report the results if (state ∈ SA ) then return <PoS(state),lexeme> else return invalid InitializeScanner() InputPos 0 for each state s in the DFA do for i 0 to |input| do Failed[s,i] false end; end;
Maximal Munch Scanner • Uses a bit array Failed to track dead-end paths • Initialize both InputPos & Failed in InitializeScanner() • Failed requires space ∝ |input stream| • Can reduce the space requirement with clever implementation • Avoids quadratic rollback • Produces an efficient scanner • Can your favorite language cause quadratic rollback? • If so, the solution is inexpensive • If not, you might encounter the problem in other applications of these technologies Thomas Reps, “`Maximal munch’ tokenization in linear time”, ACM TOPLAS, 20(2), March 1998, pp 259-273.
Code locality as opposed to random access in Table-Driven Versus Direct-Coded Scanners Table-driven scanners make heavy use of indexing • Read the next character • Classify it • Find the next state • Branch back to the top Alternative strategy: direct coding • Encode state in the program counter • Each state is a separate piece of code • Do transition tests locally and directly branch • Generate ugly, spaghetti-like code • More efficient than table driven strategy • Fewer memory operations, might have more branches state s0 ; while (state exit) do char NextChar( ) cat CharCat(char) state (state,cat); index index
Table-Driven Versus Direct-Coded Scanners Overhead of Table Lookup • Each lookup in CharCat or involves an address calculation and a memory operation • CharCat(char) becomes @CharCat0 + char x w w is sizeof(el’t of CharCat) • (state,cat) becomes @0 + (state x cols + cat) x w cols is # of columns in w is sizeof(el’t of ) • The references to CharCat and expand into multiple ops • Fair amount of overhead work per character • Avoid the table lookups and the scanner will run faster
Building Faster Scanners from the DFA A direct-coded recognizer for rDigit Digit start: accept se lexeme “” count 0 goto s0 s0: char NextChar lexeme lexeme + char count++ if (char = ‘r’) then goto s1 else goto sout s1: char NextChar lexeme lexeme + char count++ if (‘0’ char ‘9’) then goto s2 else goto sout s2: char NextChar lexeme lexeme + char count 0 accept s2 if (‘0’ char ‘9’) then goto s2 else goto sout sout: if (accept se) then begin for i 1 to count RollBack() report success end else report failure Fewer (complex) memory operations No character classifier Use multiple strategies for test & branch
Building Faster Scanners from the DFA A direct-coded recognizer for rDigit Digit start: accept se lexeme “” count 0 goto s0 s0: char NextChar lexeme lexeme + char count++ if (char = ‘r’) then goto s1 else goto sout s1: char NextChar lexeme lexeme + char count++ if (‘0’ char ‘9’) then goto s2 else goto sout s2: char NextChar lexeme lexeme + char count 1 accept s2 if (‘0’ char ‘9’) then goto s2 else goto sout sout: if (accept se) then begin for i 1 to count RollBack() report success end else report failure • If end of state test is complex (e.g., many cases), scanner generator should consider other schemes • Table lookup (with classification?) • Binary search Direct coding the maximal munch scanner is easy, too.
What About Hand-Coded Scanners? Many (most?) modern compilers use hand-coded scanners • Starting from a DFA simplifies design & understanding • Avoiding straight-jacket of a tool allows flexibility • Computing the value of an integer • In LEX or FLEX, many folks use sscanf() & touch chars many times • Can use old assembly trick and compute value as it appears • Combine similar states (serial or parallel) • Scanners are fun to write • Compact, comprehensible, easy to debug, … • Don’t get too cute (e.g., perfect hashing for keywords)
Building Scanners The point • All this technology lets us automate scanner construction • Implementer writes down the regular expressions • Scanner generator builds NFA, DFA, minimal DFA, and then writes out the (table-driven or direct-coded) code • This reliably produces fast, robust scanners For most modern language features, this works • You should think twice before introducing a feature that defeats a DFA-based scanner • The ones we’ve seen (e.g., insignificant blanks, non-reserved keywords) have not proven particularly useful or long lasting