Download

1 / 23
230 likes | 249 Views
Introduction to a fully pipelined Floating Point Unit (FPU) for OR1200 that performs diverse operations, aiming for high precision and low power consumption. The project goals include reducing clock cycles.

E N D
Fully Pipelined FPU for OR1200 Eric Zhang Electrical & Computer Engineering
Introduction & Motivation • Floating Point Unit: • Performs floating point operations such as: • add/sub, multiplication, division, sine, cosine, FMA • Wide dynamic range and high precision • Required by many algorithms and applications • Eg. Hotspot, SRAD, etc. • High performance and Low power consumption
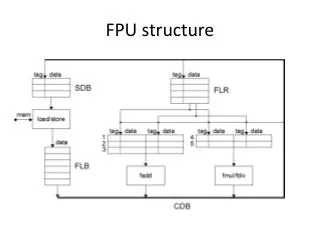
FPU in OR1200 • Arithmetic, Conversion, Comparison
FPU in OR1200 • Serial implementation with long stalls 10 cycles total 38 cycles total 37 cycles total
Goals and Objectives • Pipeline the current version of floating point multiplication and division • Reduce number of clock cycles • Eliminate the stalls due to serial implementation • Synthesize and obtain the physical layout of the pipelined FPU using Synopsys Top-Down design flow
Methodology • Analyze existing floating point implementation • Identify serial implementation that possible for pipelining • Pipeline the FPU multiplier and divider using Synopsys Register Retiming design flow • DC for synthesis, VCS for functional simulation and verification, IC compiler for physical layout, and power and are measurement
Register Retiming 1. Library setup 2. Constraint setup 3. 4. Compile 5. New constraint 6. Retiming
VCS Functional Simulation 1.6 * 4.0 = 6.4
VCS Functional Simulation 1.6 / 4.0 = 0.0625
DesignWare IP • Technology-independent • Microarchitecture-level library • Synthesizable for ASIC, SoC, and FPGA design • IPs include: • Arithmetic Components: Multiplier, divider,adder, etc • DW01_add, DW02_mult, DW_fp_mult • DSP, AMBA Bus, Memory Controller • DW_fir • etc
DesignWare IP • To use DesignWare IP: • set synthetic_librarydw_foundation.sldb • set link_library$target_library $synthetic_library • License: DesignWare • Instantiation In Verilog file: • DW01_mult #(8, 8) U1 (A, B, TC, PRODUCT); • Synthesize using normal flow
DesignWare IP • Benefits of using DesignWare IP • Increased productivity: parameterized, pre-verified • Better quality of results (QoR): optimized by Synopsys • Design reusability
Improved Scripts for design flow • Automatic setup all necessary folders and scripts • Automatic setup scratch storage for synthesis results • Scripts common to different projects are created as symbolic links • Eg. setup.tcl
Improved Scripts for design flow Top level folder without any projects: Create a project called “test”:
Improved Scripts for design flow Top level folder after creating “test”: Folder layout of project “test” : Other useful scripts : timing_closure.sh : binary search for minimum delay project_init.tcl: Project specific information: top-level design name, language, etc