Download

1 / 15
150 likes | 327 Views
16 Mathematics of Normal Distributions. 16.1 Approximately Normal Distributions of Data 16.2 Normal Curves and Normal Distributions 16.3 Standardizing Normal Data 16.4 The 68-95-99.7 Rule 16.5 Normal Curves as Models of Real-Life Data Sets 16.6 Distribution of Random Events

E N D
16 Mathematics of Normal Distributions 16.1 Approximately Normal Distributions of Data 16.2 Normal Curves and Normal Distributions 16.3 Standardizing Normal Data 16.4 The 68-95-99.7 Rule 16.5 Normal Curves as Models of Real-Life Data Sets 16.6 Distribution of Random Events 16.7 Statistical Inference
Real-Life and The 68-95-99.7 Rule The reason we like to idealize a real-life, approximately normal data set by meansof a normal distribution is that we can use many of the properties we just learnedabout normal distributions to draw useful conclusions about our data. For example, the 68-95-99.7 rule for normal curves can be reinterpreted in the context ofan approximately normal data set as follows.
THE 68-95-99.7 RULE FOR APPROXIMATELY NORMAL DATA 1. In an approximately normal data set, about 68% of the data values fallwithin (plus or minus) one standard deviation of the mean. 2. In an approximately normal data set, about 95% of the data values fallwithin (plus or minus) two standard deviations of the mean.
THE 68-95-99.7 RULE FOR APPROXIMATELY NORMAL DATA 3. In an approximately normal data set, about 99.7%, or practically 100%, of thedata values fall within (plus or minus) three standard deviations of the mean.
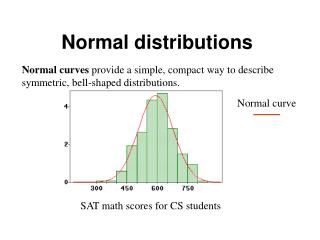
Example 16.7 2007 SAT Math Scores: Part 2 We are now going to use what welearned so far to analyze the 2007 SAT mathematics scores. As you may recall, therewere N = 1,494,531scores, distributed in a nice, approximately normal distribution. The two new pieces of information that we aregoing to use now are that the mean score was = 515 points and the standard deviation was = 114 points.
Example 16.7 2007 SAT Math Scores: Part 2 Just knowing the mean and the standard deviation (and that the distribution oftest scores is approximately normal) allows us to draw a lot of useful conclusions:
Example 16.7 2007 SAT Math Scores: Part 2 Median.In an approximately normal distribution, the mean and the medianshould be about the same. Given that the mean score was = 515, we canexpect the median score to be close to 515. Moreover, the median has to bean actual test score when N is odd (which it is in this example), and SATscores come in multiples of 10, so a reasonable guess for the median wouldbe either 510 or 520 points.
Example 16.7 2007 SAT Math Scores: Part 2 First Quartile.Recall that the first quartile is located 0.675 standard deviationbelow the mean. This means that in this example the first quartile should beclose to515 – 0.675 114 ≈ 438points. But again, the first quartile has tobe an actual test score (the only time this is not the case is when N is divisibleby 4), so a reasonable guess is that the first quartile of the test scores is either430 or 440 points.
Example 16.7 2007 SAT Math Scores: Part 2 Third Quartile.We know that the third quartile is located 0.675 standard deviationabove the mean. In this case this gives515 + 0.675 114 ≈ 592points. The most reasonable guess is that the third quartile of the test scores is either590 or 600 points.
Example 16.7 2007 SAT Math Scores: Part 2 In all three cases our guesses were very good–as reported by the CollegeBoard, the 2007 SAT math scores had median M = 510,first quartile Q1= 430,and third quartileQ3= 590. We are now going to go analyze the 2007 SAT scores in a little more depth–using the 68-95-99.7 rule.
Example 16.7 2007 SAT Math Scores: Part 2 The Middle 68. Approximately 68% of the scores should have fallen withinplus or minus one standard deviation from the mean. In this case, this rangeof scores goes from 515 – 114 = 401to 515 + 114 = 629 points. Since SATscores can only come in multiples of 10, we can estimate that a little over two-thirds of students had scores between 400 and 630 points.
Example 16.7 2007 SAT Math Scores: Part 2 The Middle 68. The remainingthird were equally divided between those scoring 630 points or more (about16% of test takers) and those scoring 400 points or less (the other 16%).
Example 16.7 2007 SAT Math Scores: Part 2 The Middle 95. Approximately 95% of the scores should have fallen withinplus or minus two standard deviations from the mean, that is, between515 – 228 = 287and 515 – 228 = 743 points. In practice this means SATscores between 290 and 740 points. The remaining 5% of the scores were 740points or above (about 2.5%) and 290 points or below (the other 2.5%).
Example 16.7 2007 SAT Math Scores: Part 2 Everyone. The 99.7 part of the 68-95-99.7 rule is not much help in this example. Essentially, it says that all test scores fell between515 – 342 = 173 points and 515 + 342 = 857 points.Duh! SAT mathematics scores are always between 200 and 800 points, so what else is new?