Power and Sample Size Analysis
David Huang, Dr. PH. Integrated Substance Abuse Treatment Programs, University of California, Los Angeles November 18, 2011 . Power and Sample Size Analysis. Outline of This Presentation. I. Introduction to Sample Size Analysis


Power and Sample Size Analysis
E N D
Presentation Transcript
David Huang, Dr. PH. Integrated Substance Abuse Treatment Programs, University of California, Los Angeles November 18, 2011 Power and Sample Size Analysis
Outline of This Presentation • I. Introduction to Sample Size Analysis • Why estimation of required sample is important for a research proposal • Rationales • What is sample size analysis • General framework: Rules of Thumb • Components: (e.g., effect size, statistical power, correlations) • II. Strategies and Examples • Single group estimation • Two-group comparisons • Multivariate analysis • Nested (multi-level) sample • Repeated measured over time
How much data do we need • How many subjects should be included in the research. Without considering the expenses, the more data the better. • It is not feasible to collect data on the entire population of interest. • Consider the collected data as a random sample of the population of interest.
Rules of Thumb • Feasible in terms of budget and research time frame • Sufficient data to ensure results to be Accurate, Efficient, and Credible
What is Sample Size Analysis • Based upon the statistical test for the main research question, • Sample size analysis is intended to determine the minimal data (or sample size) required for detecting a significant research finding.
Example: An experimental Study • An experimental study will be conducted to evaluate the treatment effectiveness between the two treatment protocols (Suboxone vs Methadone). • Outcome measures will include urine test results, ASI score and satisfaction score at three months after discharged.
Questions Related to Sample size Calculation • How to measure treatment effectiveness? What measures or indicators will be employed ? • The accuracy of the measures or indicators ? • How large a difference will be expected ? What is the smallest effect size would be considered of importance? • Whether the new treatment is expected to better than the old treatment (1-side or 2-side test). • Reliability of research findings will be (power or Alpha-level). • Whether subjects are nested within treatment clinics? Whether there are follow-up data.
Components of Sample size Calculation • What test statistic will be employed ? Hypothesis Testing: The null hypothesis vs. The alternative hypothesis • Alpha Level (or desired accuracy; width of confidence interval) • Power • Effect size: expected differences and variation of outcome measures • Sample size
Types of Statistics • Means (e.g., ASI score) -- Compare 2 means (t-test) -- Compare 3 or more means (ANOVA) • Proportions (e.g., abstinent rate) -- Compare 2 proportions • Bivariate relationship – correlation (r) • Multiple regression – Multiple R2 • Cluster sampling/multi-level
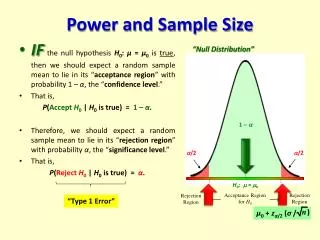
Hypothesis Testing • The null hypothesis: This hypothesis predicts that there is no effect on the variable of interest • The alternative hypothesis: This hypothesis predicts that there is an effect on the variable of interest (or a difference between groups). • Statistical tests look for evidence to reject the null hypothesis and conclude the alternative hypothesis (an effect is existing) • Sample size analysis: Determine the minimal amount of data required.
Alpha Level and Power • Alpha level: Probability of incorrectly concluding (from sample data) a significant effect when it does not really exist in the population (Type-I error). -- Alpha level is usually set as .05 • Power: Probability of correctly concluding (from sample data) a significant effect when it really exist in the population. -- Power is usually set as .80
Effect size • Effect size – Standardized measure of the magnitude of a difference or relationship. -- How big a difference or relationship (in a standardized metric) was detected in analysis -- Effect sizes (for the same type of statistics) are calculated on a common scale, which allows to compare the effectiveness of different programs • In calculating sample size: -- How big a difference or relationship do we want to detect? -- How big a difference is considered clinically important?
Computing Effect Size • Various formulas depend on type of statistic e.g., for difference in means (t-test) d= (mean1 – mean2) /standard deviation Various labels, • d for difference in two means • w (h) for difference in proportions • r for correlations • f for difference in many means (e.g., One-way ANOVA) • η2 for variance explained • R2 for multiple regression
Determining Effect Size • Based on substantive knowledge • Based on findings from prior research • Based on a pilot study • Use conventions -- e.g., small, medium and large effect size defined by Cohen
From by Cohen, 1988The bigger the effect size, the easier the detection. Magnitude of Effect size
Steps for Sample Size Determination • Decide types of outcome statistics (e.g., mean, proportion, correlations,…) • Specify 1- or 2-tailed tests • Specify desired alpha level and power • Specify the desired effect size (from literature, pilot study, or best guess)
General Rules: Required Sample Size • Detecting small effect sizes --> larger N • Smaller alpha or greater power --> larger N • 2-tailed test --> larger N than 1-tailed test • Addition of covariates (e.g., ANCOVA) reduce error variance, then increase effect size and decrease N • More parameters in model --> larger N
Effect Size vs. Number of Subjects per Group for two-tailed t-test with α=.05, power=.80
Functions of Power vs. Number of Subjects per Group for two-tailed t-test with α=.05
General Rules: Required Sample Size • Cluster sampling/multi-level data structure: -- Larger N as intra-class correlation increase • Follow-up with repeated measures: -- More repeated measures, smaller N per group
Power vs. Intra-class Correlation in the Cluster Sample given Effect Size of 0.3, α of.05, and 20 Clusters
Power vs. Number of Subjects for testing linear trend effect with repeated measures over time given effect size of 0.3 and α=.05
Limitations of Sample Size Analysis • The analyses do not generalize very well • Based on assumptions and educated guesses, the analyses give a “best case scenario” estimate of necessary sample size • It is a good strategy to compute the required sample sizes by different levels of effect size (or alpha, power), and then present the required sample sizes in a range, instead of a single number
Computational Software • Erdfelder, E., Paul, F., & Buchner, A. (1996). GPOWER: A general power analysis program. Behavior Research Methods, Instrument & Computers, 28,1-11. (Free) • http://www.psycho.uni-duesseldorf.de/abteilungen/aap/gpower3/ • Elashoff, J. (2008) nQuery Advisor.
Example 1: A Cross-sectional Evaluation • Proposition 36 was implemented in California. A study will be conducted to evaluate the system impact of P36 on treatment accessibility and outcomes among drug-abused offenders. A total of 450 clients from 15 treatment programs will be screened and recruited for the study. • Outcome measures will include urine test results during treatment, ASI score and satisfaction score at three months after discharged.
Example 1: Research Aims • Estimate proportion of negative urine test, and ASI score and satisfaction score at three months after discharged. • Examine difference in treatment outcomes by integrated and non-integrated programs. • Compare treatment retention by integrated, women-only, other types of treatment programs. • Correlation of length of treatment retention with ASI scores. • Examination of potential risk and protective factors associated with treatment outcomes (e.g., ASI score, negative urine test).
Example 1: Corresponding Sample size Analysis • Description of means and rates (%) • For an estimation of mean of a continuous measure (e.g., ASI score), the proposed sample of 450 will be sufficient to estimate ASI score within a range of ± 0.13 standard deviation. • The proposed sample of N=450 will be sufficient to estimate a rate (e.g., negative rate) of 10% within a range of ± 4%, a rate of 30% within a range of ± 6%, and a rate of 50% within a range of ± 7%.
Example 1: Corresponding Sample size Analysis • Comparisons on outcome measures by integrated and non-integrated programs. • Compare (means- independent t-test): The required sample for detecting a medium effect of 0.3 will be 176 per group. The proposed sample of 225 per group will allow detection of an effect size of 0.26. • Compare (%): Given the sample of N=225 per group, the detectable difference on rates will be 13%, 12%, and 9% when rates in the study population are 50%, 30%, and 10 %, respectively.
Example 1: Corresponding Sample size Analysis • Comparisons of means by three or more groups (e.g., ANOVA). • For comparison of means among three groups (e.g., integrated, women-only, and others), the required sample for detecting a medium effect of 0.25 (f) will be 159. The proposed sample of 450 (e.g., 150 per group) will allow detection of an effect size of 0.15.
Example 1: Corresponding Sample size Analysis • Correlation and Linear regression • In the simple regression (1 covariate), the detectable correlation of 0.2 requires a sample of 193. The sample of 450 will allow detection of small-to-medium correlation of 0.13 or larger. • In a multiple regression with p covariates, the required sample will increase, depending on the partial correlation of p-1 covariates. the sample of 450 will allow to detect medium effect of R2=.02 for predicting ASI score from 5-10 covariates.
Example 1: Corresponding Sample size Analysis • Logistic regression for categorical measures • The sample of size of 450 should allow detection of an odds ratio of 1.40 for a single covariate model, given the rate of outcome in the study population is 0.2. • The detectable effect size would increase within a multivariate model, depending the correlation of the main predictor with other covariates. The detectable odds ratio will range from 1.42 to 1.54 when partial R2 of other covariates is 0.1 to 0.4.
Example 2: An Experimental Study • Under the main scope of CTN project, an experimental study will be conducted to evaluate the treatment effectiveness between the two treatment protocols (Suboxone vs Methadone). Subjects will be randomized to one protocol. • Outcome measures will include treatment negative urine test, ASI score and satisfaction score at three months after discharged.
Example 2: An Experimental Study • In an experimental study, we need to think about “statistically significant” versus “clinically relevant” when considering effect size. • A small effect size may not be clinically meaningful. For example, a reduction of blood pressure by two points. • If an incorrect conclusion has potential adverse consequence on subjects, a lower level of alpha and a higher power should be selected.
Example 3: A Nested Study Design and A Longitudinal Study • When individual subjects are recruited from clusters (e.g., treatment programs, schools), the correlation among subjects within each cluster may need to be considered in sample size analysis. • A Longitudinal study repeatedly collects data across time. Each individual will have repeated measures over time. The repeated measures within each individual are correlated.
Example 3: Approaches and Software for Nested Data Structure • The specific statistical analysis for a nested (cluster) data is Multi-level (Hierarchical) Modeling or Generalized linear modeling. Software for computing sample size for Multi-level or Generalized linear models. • Spybrook, J., Raudenbush, S., Congdon, R., & Martinez, A. (2009) Optimal Design for Longitudinal and Multilevel Research: Documentation for the “Optimal Design” Software. Available at http://www.wtgrantfoundation.org/resources/overview/research_tools/research_tools
Example 3: Approaches to the Nested Data Structure • Efficiency of proposed sample size will decrease because of the intra-cluster correlation. The required sample size could be adjusted by an inflation factor: 1/[1+(m-1) ρ] Here, m indicates average size in a treatment program and ρ indicates intra-cluster correlation.
Random effect regression for repeated measures • The target sample size of 120 per group will allow the detection of small-to-medium effects of about d=.32 in detecting a difference in patterns over time between the maintenance group and each of the other two groups, with power=.80 and one-tailed alpha=.05 assuming a moderate correlation of .50 over time and approximately 15% attrition (Hedeker et al., 1999).
Software • Erdfelder, E., Paul, F., & Buchner, A. (1996). GPOWER: A general power analysis program. Behavior Research Methods, Instrument & Computers, 28,1-11. (Free) • http://www.psycho.uni-duesseldorf.de/abteilungen/aap/gpower3/ • Elashoff, J. (2008) nQuery Advisor. • Hedeker, D. RMASS2, Repeated Measures with Attrition: Sample Size for 2 Groups. (free) -- Old version available to download at http://tigger.uic.edu/%7Ehedeker/ml.html -- New on-line version available at http://www.uic.edu/labs/biostat/projects.html -- Software for computing sample size for general(ized) linear models with repeated measures.
Software • Spybrook, J., Raudenbush, S., Congdon, R., & Martinez, A. (2009) Optimal Design for Longitudinal and Multilevel Research: Documentation for the “Optimal Design” Software. Available at http://www.wtgrantfoundation.org/resources/overview/research_tools/research_tools • SamplePower. SPSS $$SPSS module for computing power/sample size. • Proc POWER and Proc GLMPOWER. SAS $$ SAS procedures for computing power/sample size.
Software • PS-power/sample size (free) Available to download at http://biostat.mc.vanderbilt.edu/twiki/bin/view/Main/PowerSampleSize • Dennis, M (1997) Power Analysis Worksheet. (free) Available at http://www.chestnut.org/LI/downloads/index.html [Click on "Power Analysis Worksheet part way down web page] Excel spreadsheet for calculating sample size for simple designs/analyses
References • Cohen, J. (1988) Statistical Power Analysis for the Behavioral Sciences. Hillsdale, NJ: Lawrence Erlbaum Assoc. Formulas and tables for computing power and sample size--very comprehensive and somewhat difficult--but very well-respected reference. • Fink, A. (2003) How to sample in surveys. Thousands Oaks, CA: Sage. Simple step-by-step guide to sampling issues and procedures—with table for looking up approximate sample size for proportions from 2-category responses. • Kraemer, H. C. & Thiemann, S. (1987) How Many Subjects? Newbury Park, CA: Sage. -- Formulas and tables for approximate sample size and some good descriptions of issues. • Lipsey, M. W. (1990) Design Sensitivity. Newbury Park, CA: Sage. Non-mathematical discussion of many design/sample size issues. • Rudy, E. & Kerr, M. (1991) Unraveling the mystique of power analysis. Heart & Lung, 20(5), 517-522. Description of power/sample size for researchers.