Download

1 / 42
430 likes | 728 Views
Genetic and Molecular Epidemiology. Lecture III: Molecular and Genetic Measures Jan 20, 2009 Joe Wiemels AC-34 (Parnassus) 514-0577 joe.wiemels@ucsf.edu. Lecture . Review of the structure of genes: genetic variation and mutation

E N D
Genetic and Molecular Epidemiology Lecture III: Molecular and Genetic Measures Jan 20, 2009 Joe Wiemels AC-34 (Parnassus) 514-0577 joe.wiemels@ucsf.edu
Lecture Review of the structure of genes: genetic variation and mutation PCR (polymerase chain reaction) and DNA amplification methods Detection of mutations and polymorphisms: low and high throughput techniques Other genetic markers: microsatellites Microarray techniques: SNPs, gene expression, etc.
Gene structure Each cell has two chromosomes, therefore there are two physical copies of each gene. The position of a gene is called a locus, and the exact form of the gene is called an allele. Each gene can exist in the form of two alleles 1378 genes on chromosome 7, 159,000,000 base pairs. TAS2R38 gene (PTC TASTE RECEPTOR) Chromosome 7
DNA EXONS INTRONS Transcription Start site PROMOTER Translation start site Stop codon RNA Anatomy of a Gene
Expression blots and arrays Exon splice variants microRNA Detection with antibodies, mass spec, proteomics Genotyping Mutations Chromosomes DNA RNA PROTEIN Translation Transcription Occurs in the nucleus Occurs in the cytoplasm
DNA variation Mutation A gene variant limited to less than 1% of the population, or in one family line only, or even in one cell (when talking about cancer) Single Nucleotide Polymorphism (SNP) A single position in the human genome where more than one type of nucleotide (a variant) is prevalent in the population (at least 1% or 5% prevalence dependent on your purposes). These average 1 in 1000 base pairs or 3+ million common SNPs per genome.
Where are mutations/polymorphisms likely to have an effect on gene function and disease? • Promoter region: affect expression levels • Coding region (exons): affect protein structure • Exon splice sites: affect protein structure • Mutations in genes that control the expression of other genes can have profound effects on expression.
Gene promoters are 500-2000 bp “upstream” from the coding region. Promoter of the human CDKN1B gene Transcription factors are proteins which bind within promoters and control gene expression.
Mutations in Exons can result in altered protein structure Example of a missense base pair change M P N S G N V ATGTTTAATAGCGGTAATGTT ATGTTTAATAGCAGTAATGTT M P N S S N V This is a G->A SNP which results in a missense mutation
Classes of SNPs in coding sequences (exons) Synonymous (silent) substitutions: Do not cause amino acid change (but still may be functional) Nonsense mutation: cause the formation of a stop codon (ie., TAA or TGA, and a truncated protein (completely disables a protein) Nonsynonymous (missense) mutations: cause change of amino acid, but may be “conservative” (like for like amino acid) or “nonconservative” (dissimilar amino acid)
Examples of diseases caused by…. Missense mutation/polymorphism: cause variable or loss of function sickle cell anemia (hemoglobin) HBB - GAG-GTG in 20th codon thrombosis, early miscarriage, heart disease, colon cancer MTHFR (30% carrier frequency) ALS – SOD1, breast cancer - BRCA1/2 Nonsense mutation/polymorphism: cause complete loss Duchene Muscular dystrophy dystrophin, DMD Cystic Fibrosis CFTR
Examples of diseases caused by…. Synonymous mutation/polymorphism: affects expression or protein folding infantile spinal muscular atrophy UBE1 (reduction in expression) hearing loss TECTA (exonic splice enhancer) Promoter/enhancer mutation/polymorphism: affects expression Drug and caffeine metabolism CYP3A4 thymidine and folate metabolism TK activation of compounds in bone marrow/granulocytes MPO
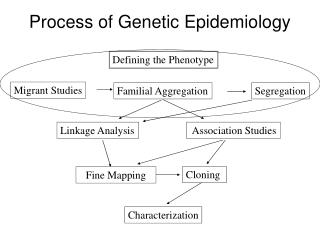
A disease has a genetic component, what do you do now? No idea of the gene: whole genome scan of genetic markers: SNPs or microsatellites Fair idea of the gene: candidate gene SNPs at “medium throughput” You know what the gene is, but no idea of the genetic alteration: DNA sequencing.
Genetic Markers Polymorphic variation scattered around genome used to help identify disease genes. Most genetic variation is non-functional, but may be physically linked to a functional genetic element. Genetic markers may “segregate” with a disease Microsatellites (a million per genome) Single Nucleotide Polymorphisms (3 million in genome)
A common genetic marker Microsatellite (aka STS, sequence tagged site): highly polymorphic DNA sequence feature (not functionally polymorphic). A simple repeat sequence that invites slippage-mispair during replication, and hence many polymorphic variations in size in the population. DNA sequence, showing alternating “ACACACAC”
Microsatellites are diagnosed by size Every individual has 2 alleles Individual people + nearly everyone is “heterozygous” Size of DNA fragment 3 separate microsatellite polymorphisms analyzed in “multiplex” -
Single Nucleotide Polymorphism For usefulness as a genetic marker, it should be common (>5% allele frequency) Only two variants, so much less information per test than a microsatellite Whole genome disease scan requires far more tests than microsatellite, but each test is far less expensive
How do we test for genetic variants?Many Genetic Analyses begin with PCR Polymerase Chain Reaction (PCR) – specific amplification of a single gene sequence 2 synthetic oligonucleotides can “find” their complementary DNA sequences among 3 billion nucleotide sequence. Able to faithfully amplify a specific sequence 1030 times.
Testing for functional SNsP (background) Alleles: different forms of a gene at the same locus. • TAS2R38: 3 polymorphisms: • C145G (G variant at position 145) P49A • C785T (T variant at position 785) V262A • G886A (A variant at position 886) V296I • “wild type” (C, C, and G at each position, respectively) WT 8 potential haplotype alleles based on 3 SNPs P49A V262A V296I
Genotyping in MGE – TICR Individuals • Get genomic DNA from subject (buccal cell demonstration in class) • Isolate DNA on Autogen 3000 • Lyses cells with detergent and digests protein with Proteinase K • Removes protein with Phenol • Concentrates DNA using ethanol precipitation, rehydrates DNA in buffered water.
Genotyping in MGE - TICR Individuals (continued) Purified genomic DNA will be amplified in the region of the polymorphisms, then a “readout” performed PCR amplification is a standard method, but there are many methods to “read” the polymorphism Cellular DNA is 3 X 10^9 base pairs, a gamish of sequence but only a few copies of the gene of interest Two PCR primers (oligonucleotides) will be able to make billions of copies of one small segment, crowding out the rest of the genomic DNA
PCR design for TAS2R38 polymorphism These probes are used to diagnose the SNP.
PCR protocol: 10 ng of DNA mixed with 10 pmoles each PCR primer 1 pmoles each probe 2.5 umoles each dNTP Reaction buffer (salts including MgCl2) Taq polymerase (thermostable DNA polymerase) The temperature of the mixture is cycled 35 times: 65 degrees 30 seconds 72 degrees 30 seconds 94 degrees 15 seconds
Detection of PCR products using Electrophoresis gel. - individuals PCR product + PCR products for a SNP are all the same size; this “gel” is not diagnostic for the SNPs
Taqman allelic discrimination genotyping (for taste receptor TASR32) There are four oligonucleotides in the reaction mix -- two PCR primers and two “probes” each labelled different color and each matching different SNP allele.
hets Taqman Genotyping - Real-time PCR homozygotes homozygotes
DNA sequencing: the method to obtain the genotype of a new mutation (for example, in a “cancer family”) Prior to sequencing, one first amplifies a sequence by PCR or cloning in a bacterial vector. Then, using ONE primer, adds fluorescent labeled dideoxy chain terminators and DNA polymerase. ddNTPs will “cap” the sequence.
mutation DNA sequencing The products of the sequencing reaction are separated on a gel mixture that can separate fragments by one base pair. Larger fragments Smaller fragments Useful when you suspect a gene, but don’t know the variant. This one is BRAF gene in leukemia
Many genotyping platforms available today Taqman genotyping: Low throughput Fluorescence Polarization (Pui Kwok): Low Luminex: medium Massive parallel genotyping: High throughput, useful for whole genome scans: Affymetrix Illumina “Ultradeep” or “next generation” sequencing: Illumina (Solexa), Applied Biosystems, 454 (Roche)
Illumina GoldenGate technologyfor 384-6000 SNPs at a time (medium, not whole genome) 96-well plate, each with bead array 45,000 beads
Illumina Infinium assay: up to 1 million SNPs (for whole genome study) Bead array on slide
Microarray basics Some Applications for Microarray: SNP genotyping (eg Affymetrix, Illumina) Gene expression patterns - comparing one tissue to another (Affymetrix, Superarray, etc) Gene deletion or amplification: arrayCGH (for cancer applications, Albertson and Pinkel, UCSF) microRNA (UCSF Gladstone, Ambion) Pathogen identification (DeRisi, UCSF)
Types of Microarrays • Spotted (early technology) • cDNA (for expression, 100s - 1000s bases) • oligonucleotide (less than 100 bp) • BAC clone (100-200,000 bases, for array-based comparative genomic hybridization) • Chemically synthesized oligonucleotides (Affymetrix, NimbleGen, Agilent) • expression • gene resequencing • SNP genotyping • array-based CGH
Spotted microarray for gene expression (oligos or cloned genes) The microrarray may have immobilized oligonucleotides (eg., virochip, UCSF) or cloned genes
Affymetrix arrays have 25 bp oligonucleotides, very short, but massive parallel probes for redundancy. One color array.
The virochip (UCSF) is a spotted microarray. Hybridization of a clinical RNA (cDNA) sample can identify specific viral expression
Gene Expression of Breast Cancer predicts disease-free outsome (Nature 2002 Friend et al) Figure 2 Supervised classification on prognosis signatures. a, Use of prognostic reporter genes to identify optimally two types of disease outcome from 78 sporadic breast tumours into a poor prognosis and good prognosis group (for patient data see Supplementary Information Table S1). b, Expression data matrix of 70 prognostic marker genes from tumours of 78 breast cancer patients (left panel). Each row represents a tumour and each column a gene, whose name is labelled between b and c. Genes are ordered according to their correlation coefficient with the two prognostic groups. Tumours are ordered by the correlation to the average profile of the good prognosis group (middle panel). Solid line, prognostic classifier with optimal accuracy; dashed line, with optimized sensitivity. Above the dashed line patients have a good prognosis signature, below the dashed line the prognosis signature is poor. The metastasis status for each patient is shown in the right panel: white indicates patients who developed distant metastases within 5 years after the primary diagnosis; black indicates patients who continued to be disease-free for at least 5 years. c, Same as for b, but the expression data matrix is for tumours of 19 additional breast cancer patients using the same 70 optimal prognostic marker genes. Thresholds in the classifier (solid and dashed line) are the same as b. (See Fig. 1 for colour scheme.) NOW A CLINICAL ASSAY!!: ONCOTYPE