Download

1 / 21
1.08k likes | 4.11k Views
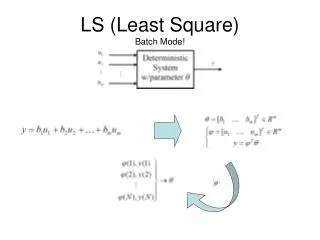
Recursive Least-Squares (RLS) Adaptive Filters. Definition. With the arrival of new data samples estimates are updated recursively. Introduce a weighting factor to the sum-of-error-squares definition. two time-indices n: outer, i: inner. Weighting factor. Forgetting factor.

E N D
Recursive Least-Squares (RLS)Adaptive Filters ELE 774 - Adaptive Signal Processing
Definition • With the arrival of new data samples estimates are updated recursively. • Introduce a weighting factor to the sum-of-error-squares definition two time-indices n: outer, i: inner Weighting factor Forgetting factor : real, positive, <1, →1 =1 → ordinary LS 1/(1- ): memory of the algorithm (ordinary LS has infinite memory) w(n) is kept fixed during the observation interval 1≤i ≤n for which the cost function (n) is defined. ELE 774 - Adaptive Signal Processing
Definition ELE 774 - Adaptive Signal Processing
Regularisation • LS cost function can be ill-posed • There is insufficient information in the input data to reconstruct the input-output mapping uniquely • Uncertainty in the mapping due to measurement noise. • To overcome the problem, take ‘prior information’ into account • Prewindowing is assumed! • (not the covariance method) Regularisation term Smooths and stabilises the solution : regularisation parameter ELE 774 - Adaptive Signal Processing
Normal Equations • From method of least-squares we know that then the time-average autocorrelation matrix of the input u(n) becomes • Similarly, the time-average cross-correlation vector between the tap inputs and the desired response is (unaffected from regularisation) • Hence, the optimum (in the LS sense) filter coefficients should satisfy autocorrelation matrix is always non-singular due to this term. (-1 always exists!) ELE 774 - Adaptive Signal Processing
Recursive Computation • Isolate the last term for i=n: • Similarly • We need to calculate -1 to find w→ direct calculation can be costly! • Use Matrix Inversion Lemma (MIL) ELE 774 - Adaptive Signal Processing
Recursive Least-Squares Algorithm • Let • Then, using MIL • Now, letting • We obtain inverse correlation matrix gain vector Riccati equation ELE 774 - Adaptive Signal Processing
Recursive Least-Squares Algorithm • Rearranging • How can w be calculated recursively? Let • After substituting the recursion for P(n) into the first term we obtain • But P(n)u(n)=k(n), hence ELE 774 - Adaptive Signal Processing
Recursive Least-Squares Algorithm • The term is called the a priori estimation error, • Whereas the term is called the a posteriori estimation error. (Why?) • Summary; the update eqn. • -1 is calculated recursively and with scalar division • Initialisation: (n=0) • If no a priori information exists gain vector a priori error regularisation parameter ELE 774 - Adaptive Signal Processing
Recursive Least-Squares Algorithm ELE 774 - Adaptive Signal Processing
Recursive Least-Squares Algorithm ELE 774 - Adaptive Signal Processing
Recursion for the Sum-of-Weighted-Error-Squares • From LS, we know that where • Then • Hence ELE 774 - Adaptive Signal Processing
Convergence Analysis • Assume stationary environment and =1 • To avoid transitions, consider times n>M • Assumption I: The desired response d(n) and the tap-input vector u(n) are related by the linear regression model where wo is the regression parameter vector and eo(n) is the measurement noise. The noise eo(n) is white with zero mean and variance so2 which makes it independent of the regressor u(n). ELE 774 - Adaptive Signal Processing
Convergence Analysis • Assumption II: The input vector u(n) is drawn from a stochastic process, which is ergodic in the autocorrelation function. • R: ensemble average, : time average autocorrelation matrices • Assumption III: The fluctuations in the weight-error vector (n) are slow compared with those of the input signal vector u(n). • Justification: (n) is an accumulation of the a priori error → hence, the input →Smoothing (low-pass filtering) effect. • Consequence: ELE 774 - Adaptive Signal Processing
Convergence in Mean Value =1 • Then, • Substituting into w(n) and taking the expectation, we get • Applying Assumptions I and II, above expression simplifies to • biased estimate due to the initialization, but bias →0 as n→∞. ELE 774 - Adaptive Signal Processing
Mean-Square Deviation • Weight-error correlation matrix and invoking Assumption I and simplifying we obtain • Then • But, mean-square-deviation is ELE 774 - Adaptive Signal Processing
Mean-Square Deviation • Observations: • Mean-Square Deviation D(n) • is proportional to the sum of reciprocal of eigenvalues of R • The sensitivity of the RLS algorithm to eigenvalue spread is determined by the reciprocal of the smallest eigenvalue. • ill-conditioned LS problems may lead to poor convergence behaviour. • decays almost linearly with the number of iterations • w(n) converges to the Wiener solutionwo as n grows. ^ ELE 774 - Adaptive Signal Processing
Ensemble-Average Learning Curve • There are two error terms • A priori error, • A posteriori error, • Learning curve considering (n) yields the same general shape as that for the LMS algorithm. • Both RLS and LMS learning curves can be compared with this choice. • The learning curve for RLS (a posteriori error) is • We know that ELE 774 - Adaptive Signal Processing
Ensemble-Average Learning Curve • Substitution yields • 1st term (Assumption I) • 2nd term (Assumption III) • 3 & 4th terms (Assumption I) ELE 774 - Adaptive Signal Processing
Ensemble-Average Learning Curve • Combining all terms • Observations • The ensemble-average learning curve of the RLS algorithm converges in about 2M iterations • Typically an order of magnitude faster than LMS • As the number of iterations n→∞ the MSE J’(n) approaches the final value σo2 which is the variance of the measur. error eo(n). • in theory RLS produces zero excess MSE!. • Convergence of the RLS algorithm in the mean square is independent of the eigenvalues of the ensemble-average correlation matrix R of the input vector u(n). ELE 774 - Adaptive Signal Processing
Ensemble-Average Learning Curve ELE 774 - Adaptive Signal Processing