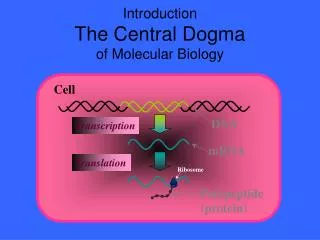
遗传信息的中心法则 Central Dogma
遗传信息的中心法则 Central Dogma. 第十五章 蛋白质生物合成 ( 翻译 ) S ynthesis of Protein (Translation). 广州中医药大学生化教研室. 翻译: 也称蛋白质的生物合成。 意思就是把核酸中由 A 、 C 、 G 、 T/U 四种符号组 成的遗传信息,破读为蛋 白质分子中的 20 种氨基酸. 排列顺序。. 内 容. 参与蛋白质生物合成的物质 蛋白质的生物合成过程 翻译后加工 蛋白质生物合成的干扰和抑制.
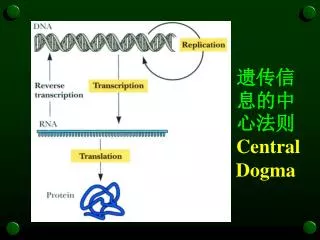

遗传信息的中心法则 Central Dogma
E N D
Presentation Transcript
第十五章 蛋白质生物合成(翻译) Synthesis of Protein (Translation) 广州中医药大学生化教研室
翻译:也称蛋白质的生物合成。 意思就是把核酸中由A、C、G、T/U四种符号组 成的遗传信息,破读为蛋 白质分子中的20种氨基酸 排列顺序。
内 容 • 参与蛋白质生物合成的物质 • 蛋白质的生物合成过程 • 翻译后加工 • 蛋白质生物合成的干扰和抑制
一、mRNA是翻译的直接模板 • 开放读码框(open reading frame,ORF): mRNA从5’至3’方向,若有AUG开始,可 以称为一个ORF。未鉴定读框(URF) • 编码序列(codon sequence,CDS): 一种蛋白质对应的mRNA序列,称为CDS。也就是位于起始密码子和终止密码子之间的核糖核酸序列。 • ORF和CDS的区别:
TCAAGGATGCGGATGTCATCATCGTCACTGCAGGGGTGCCTCGGAAGCCAGGTATGTCTCGAAGAAAAATCGGCCTCATCGGCGGCGGCAACATCGGCGCCACGCTTGCCCTTCTCTCCGCTGTCAAGGAACTCGGCGACGTCGTCATGTTCGACGTCGTCCAGGACCTCCCGCAAGGAAAATGCCTCGATCTGTACCAGTTGACTCCGATCTCTGGAGTTGACGTTCGCTTCGAGGGCTCGAACGACTACAGCGTCCTCAAGGATGCGGATGTCATCATCGTCACTGCAGGGGTGCCTCGGAAGCCAGGTATGTCTCGCGACGACCTGCTGGCGATTAACGCGAAAATCATGGGCCAAGTTGGAGAAGCCATCAAGCAGTACTGCCCCAACGCATTCGTCATTTGCATCACGAATCCACTCGATGTGATGGTCTACATCCTCCGCGAAAAATGCGGCTTGCCTCCCCACAAAGTTTGCGGCATGGCCGGCGTCCTCGACTCAGCTCGGCTTCGCACGTTTCTCTCGGAGCGTCTCAACGTCTCCGTCGATGACATCCACGCCCTCGTCATGGGTGGCCATGGAGACACCATGGTGCCCCTCCCTCGATTCACCACTGTGGGAGGCATCCCCCTGCCTGAGCTGGTGAAGATGGGTATGATTTCTCAACAAGAAGTCGACGATATCGTCCAACGCACTCGCAATGGAGGTGGAGAAATCGTCTCATTGCTGAAGACGGGCTCTGCTTTCTTCGCTCCCGCGGCTGCGGGCGTCTTGATGGCCGAGGCGTACCTGAAGGACCGCAAACGCGTGCTGCCTTGTGCCGCCTATTTGAACGGAGAGTACGGTGTCAAGGACATGTATGTGGGCGTGCCGTGCGTGATCGGCGCGGGCGGCGTCGAGAAGATTGTCGAATTGGACTTGACGCCTGAGGAGAAGAAGATGTTCGAGCGCTCGGTTGAAAGTGTGAAGACGCTTCTCGCCGCTGCTCCAAAGTCAGCCTGATCAAGGATGCGGATGTCATCATCGTCACTGCAGGGGTGCCTCGGAAGCCAGGTATGTCTCGAAGAAAAATCGGCCTCATCGGCGGCGGCAACATCGGCGCCACGCTTGCCCTTCTCTCCGCTGTCAAGGAACTCGGCGACGTCGTCATGTTCGACGTCGTCCAGGACCTCCCGCAAGGAAAATGCCTCGATCTGTACCAGTTGACTCCGATCTCTGGAGTTGACGTTCGCTTCGAGGGCTCGAACGACTACAGCGTCCTCAAGGATGCGGATGTCATCATCGTCACTGCAGGGGTGCCTCGGAAGCCAGGTATGTCTCGCGACGACCTGCTGGCGATTAACGCGAAAATCATGGGCCAAGTTGGAGAAGCCATCAAGCAGTACTGCCCCAACGCATTCGTCATTTGCATCACGAATCCACTCGATGTGATGGTCTACATCCTCCGCGAAAAATGCGGCTTGCCTCCCCACAAAGTTTGCGGCATGGCCGGCGTCCTCGACTCAGCTCGGCTTCGCACGTTTCTCTCGGAGCGTCTCAACGTCTCCGTCGATGACATCCACGCCCTCGTCATGGGTGGCCATGGAGACACCATGGTGCCCCTCCCTCGATTCACCACTGTGGGAGGCATCCCCCTGCCTGAGCTGGTGAAGATGGGTATGATTTCTCAACAAGAAGTCGACGATATCGTCCAACGCACTCGCAATGGAGGTGGAGAAATCGTCTCATTGCTGAAGACGGGCTCTGCTTTCTTCGCTCCCGCGGCTGCGGGCGTCTTGATGGCCGAGGCGTACCTGAAGGACCGCAAACGCGTGCTGCCTTGTGCCGCCTATTTGAACGGAGAGTACGGTGTCAAGGACATGTATGTGGGCGTGCCGTGCGTGATCGGCGCGGGCGGCGTCGAGAAGATTGTCGAATTGGACTTGACGCCTGAGGAGAAGAAGATGTTCGAGCGCTCGGTTGAAAGTGTGAAGACGCTTCTCGCCGCTGCTCCAAAGTCAGCCTGA
密码子codon : 针对CDS; mRNA上每3个相邻核苷酸组成一个三联体triplet,编码一种氨基酸,三联体即称之为密码子。 遗传密码(genetic codon):密码子的总和。
ATG TCT CGA AGA AAA ATC GGC CTC ATC GGC GGC GGC AAC ATC GGC GCC ACG CTT GCC CTT CTC TCC GCT GTC AAG GAA CTC GGC GAC GTC GTC ATG TTC GAC GTC GTC CAG GAC CTC CCG CAA GGA AAA TGC CTC GAT CTG TAC CAG TTG ACT CCG ATC TCT GGA GTT GAC TCG CTT CGA GGG CTC GAA CGA CTA CAG CGT CCT CAA GGA TGC GGA TGC CAG GAC CTC TGA
密码子codon : 理论值: 43=64 起始密码子start codon: AUG,编码甲硫氨酸(真核) 甲酰甲硫氨酸(原核) 终止密码子stop codon: UAA、UAG、UGA
遗传密码的基本特性: 通用性universal 方向性directional 连续性commaless 简并性degeneracy 摆动性wobble 密码子与反密码子配对,有时会出现不遵从碱基配对规律的情况,称为遗传密码的摆动现象。
二、核糖体是肽链合成的场所 • 核糖体ribosome的组成:
核糖体的组成: 原核核糖体为70S,有30S的小亚基和50S的大亚基组成。 真核核糖体为80S,有40S的小亚基和60S的大亚基组成。
核糖体的功能部位: 容纳mRNA的部位-小亚基上 结合氨基酰tRNA的部位(受位,A位) 结合肽酰tRNA的部位(给位,P位) 转肽酶存在的部位(核糖体大亚基)
三、tRNA是转接器 作为氨基酸受体的tRNA在结构上必须具备以下识别位点: • 氨基酸接受位点 • 氨基酰—tRNA合成酶识别位点 • 核糖体识别位点 • 反密码子
翻译精确性的保证: 密码子——反密码子——氨基酸
四、其他因子 • 起始因子——IF1、IF2、IF3 • 延长因子—— EFTu、EFTs、EFG • 释放因子(终止)—— RF1、RF2、RF3 • 氨酰—tRNA合成酶 • GTP、ATP、Mg2+参加
酶 催化反应 氨基酰tRNA合成酶 绝对专一性 1种氨基酸——对应 1种氨基酰tRNA合成酶 活化氨基酸---活化“-COOH” 消耗2个ATP 活化氨基酸+tRNA 氨基酰tRNA 一、氨基酸的活化与转运
消耗2ATP 第一步反应 第二步反应 3’-CCA-OH
Ser Met Thr His Ala Ala Tyr Asp His
二、翻译的起始 ★ 翻译起始 把带有甲酰甲硫氨酸 (formyl-N-Met,f-Met)的起始tRNA连同mRNA结合到核糖体上,生成翻译起始复合物 translational initiation complex。
2. mRNA在核糖体小亚基上就位 S-D序列:在翻译起始密码子AUG上游,相距约8- 13个核苷酸,往往有一段由4-6个核苷 酸组成的富含嘌呤的序列。这一序列以 AGGA为核心,因发现者是Shine- Dalgamo而得名为S-D序列。 16S-rRNA:近3’-末端处,有一段序列以UCCU为 核心,与S-D序列的AGGA互补。
起始密码 SD序列
3. f-Met-tRNA的结合 与第二步同时发生, f-Met-tRNA只能辨认和结合于mRNA的起始密码子AUG上。 意义:保证mRNA就位准确性,推 动mRNA前移
4. 核糖体大亚基结合 起始复合物的形成: mRNA; f-Met-tRNA;小亚基;大亚基 P位peptidyl site(给位donor site):f-Met-tRNA和 mRNA的AUG占据P位点。再次成肽 时,肽从P位置转给A位,所以将P位 也称为给位。 A位aminoacyl site(受位acceptor site):氨基酰位称 为A位。因每次成肽时,A位接受肽酰基 链,故又称受位。
三、肽链的延伸 翻译过程的肽链延长,也称为核糖体循环。 每次核糖体循环可分成三个步骤:进位或称注册、成肽、转位。循环一次,肽链延长一个氨基酸。
(一)进位entrance或注册registration • 概念:指氨基酰-tRNA根据遗传密码的指引, 进入核糖体的A位。 • 程序: EFT:包含EFTu和EFTs两个亚基。 EFT结合GTP,释放出Ts,Tu-GTP复合物结合氨基酰-tRNA。氨基酰-tRNA-Tu-GTP被送至核糖体与小亚基的mRNA结合,密码子与反密码子对应。GTP分解放出Pi。Tu-GDP与Ts重新结合成EFT,进行下次反应。
(二)成肽peptide bond formation 成肽由大亚基上的转肽酶催化。 P位上的f-Met-tRNAfmet的酰基与A位 上的AA-tRNA的氨基进行反应。反应在A位上进行,即P位上的甲硫氨酸退至A位。 成肽中甲硫氨酸退入A位成肽,P位留下一个无负载的tRNA。成肽结束前,tRNA从核糖体上脱落,P位留空。
(三)转位translocation 转位就是A位的二肽链连同mRNA从A位进入P位。 实际是整个核糖体的相对位置移动。 反应由转位酶催化。
四、肽链合成的终止 • 终止包括: 终止密码的辨认; 肽链从肽酰-tRNA水解释出; mRNA从核糖体中分离; 大小亚基的拆开。