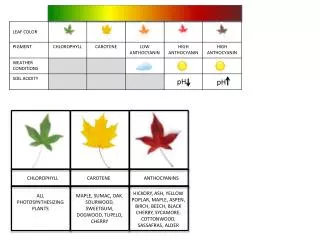
Download

1 / 25
250 likes | 276 Views
This paper discusses the quantification of errors in chlorophyll algorithms using a common data set and performance criteria. It covers error definitions, log-log regression errors, the relationship between log errors and relative errors, empirical error statistics, the lognormal assumption, and more. The importance of adjusting for the distribution of chlorophyll is also highlighted.

E N D
Quantifying the Performance of a Chlorophyll Algorithm Janet W. Campbell University of New Hampshire Durham, New Hampshire September 27, 2005 Ocean Color Bio-optical Algorithm Mini Workshop (OCBAM) “Algorithms will be evaluated using a common data set (a subset of NOMAD) and common performance criteria.”
OUTLINE • Definitions of “error” • Errors associated with log-log regressions • Relationship between log errors and relative errors • Empirical error statistics • The lognormal assumption • Predicted vs. measured chlorophyll • Mistakes not to make • Adjusting for the distribution of chlorophyll
Error Definitions The zero-th order definition of error is the log-error: d = The OC4/OC3M polynomials minimize the mean square d:
Error Definitions Log error: d = = Relative error: relerr = = or percentage error = relerr * 100% is often desired. The log error and relative error are directly related: d =
For every point in NOMAD, you can calculate di and relerri (i = 1,…,N). di
Characterize the distribution of log errors in terms of their mean, standard deviation, and root-mean-square. The histogram of di … is symmetric and ~ normally distributed.
The log errors are difficult to interpret because they are in log units (decades). The histogram can easily be converted to a more meaningful one by labeling the axis in terms of the ratio . Note that the scale hasn’t changed – only the labels. Since log( ) is normally distributed, then is lognormally distributed.
In the same manner that you derived statistics of di, you can also derive the statistics of relerri. Or, if the di errors are normally distributed, you can derive the statistics of the relative error from the log error statistics (see text).
OUTLINE • Definitions of “error” • Errors associated with log-log regressions • Relationship between log errors and relative errors • Empirical error statistics • The lognormal assumption • Predicted vs. measured chlorophyll • Mistakes not to make • Adjusting for the distribution of chlorophyll • Other performance criteria √ √ √
In this plot, the measured and predicted (algorithm) chlorophylls are both represented on the vertical axis and plotted against the variable X = log (max Rrs/Rrs555). In this case, the R2 statistic is a measure of the performance of the algorithm.
In the case where the predicted chlorophyll is plotted against the measured chlorophyll, the R2 statistic is not a measure of the performance of the algorithm. Such plots are useful to reveal systematic errors in the algorithm, but the R2 statistic is misleading. Conditions for good agreement are a slope of 1 and an intercept of 0. n: 2189 int: -0.330 slope: 0.614 R2: 0.808 rms: 0.395 bias: -0.235
Here is an example of a better performing algorithm, even though the R2 statistic is lower (0.795) compared with the one shown on the previous slide (0.808).
OUTLINE • Definitions of “error” • Errors associated with log-log regressions • Relationship between log errors and relative errors • Empirical error statistics • The lognormal assumption • Predicted vs. measured chlorophyll • Mistakes not to make • Adjusting for the distribution of chlorophyll • Other performance criteria √ √ √ √
Mistakes not to Make • In a regression of predicted vs. measured, the R2 is not a measure of the performance of your algorithm. • 100% (1- R2) is not the relative error in chlorophyll. • 100% di is not the relative error in chlorophyll.
Mistakes not to Make • In a regression of predicted vs. measured, the R2 is not a measure of the performance of your algorithm. • 100% (1- R2) is not the relative error in chlorophyll. • 100% di is not the relative error in chlorophyll. • Don’t plot relative (or percentage) errors on linear scales unless the errors are small. Negative errors cannot be < 100% (if > 0), but positive errors can be arbitrarily large. This gives false impression that the errors are highly skewed whereas a plot of the log errors is often symmetric.
OUTLINE • Definitions of “error” • Errors associated with log-log regressions • Relationship between log errors and relative errors • Empirical error statistics • The lognormal assumption • Predicted vs. measured chlorophyll • Mistakes not to make • Adjusting for the distribution of chlorophyll • Other performance criteria √ √ √ √ √
The performance measures derived from NOMAD or any database are influenced by the distribution of the stations in the database. Often there’s an over abundance of high chlorophyll stations.
Distribution of chlorophyll in the SeaWiFS climatology (1997-2005) (red) compared with that in NOMAD (blue). Chlorophyll, mg m-3
Log errors (di) for OC4.v4 vs. measured chlorophyll. The red curve is the SeaWiFS distribution shown on the previous slide.
0.2 Blue and green: cumulative RMSEs for all stations having chlorophyll < “In situ Chl” Brown: cumulative distribution of the SeaWiFS chlorophyll climatology (1997-2005).
One way to adjust for differences in the distributions of the data (vs. real world) is to bin the data and characterize errors within bins. Then weight the statistics according to the frequency of the global real-world distribution.
OUTLINE • Definitions of “error” • Errors associated with log-log regressions • Relationship between log errors and relative errors • Empirical error statistics • The lognormal assumption • Predicted vs. measured chlorophyll • Mistakes not to make • Adjusting for the distribution of chlorophyll • Other performance criteria √ √ √ √ √ √
Other performance criteria • How quick is the algorithm when applied to a satellite image? • How often does the algorithm fail to converge to a solution? • How sensitive is the algorithm to errors in the water-leaving radiance (atmospheric correction)? • Others?
Conclusions / Comments • The operational chlorophyll algorithms used by SeaWiFS (OC4) and MODIS (OC3M) are not “accurate to within 35%.” (This is a myth) • The log error = is the basic measure of performance. Its statistics can easily be converted to relative error statistics. • The OC4 and OC3M algorithms have a 60-70% uncertainty. • Given that chlorophyll varies by 4 orders of magnitude (10000%) globally, that ain’t bad!