Download
1 / 1
10 likes | 160 Views
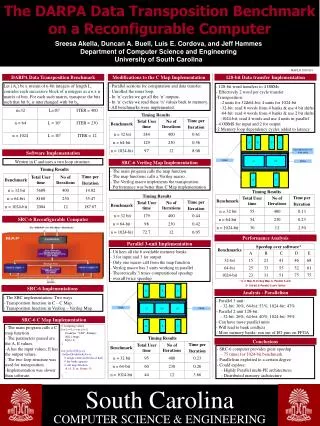
A. A. B. B. D. C. C. Each performs 2 or 4-bit shifts. U1. U1. U2. U2. U3. OBMs. OBMs. FPGA. FPGA. D. E. E. F. F. The DARPA Data Transposition Benchmark on a Reconfigurable Computer. Sreesa Akella, Duncan A. Buell, Luis E. Cordova, and Jeff Hammes

E N D
A A B B D C C Each performs 2 or 4-bit shifts U1 U1 U2 U2 U3 OBMs OBMs FPGA FPGA D E E F F The DARPA Data Transposition Benchmark on a Reconfigurable Computer Sreesa Akella, Duncan A. Buell, Luis E. Cordova, and Jeff Hammes Department of Computer Science and Engineering University of South Carolina MAPLD 2005/243 128-bit Data transfer Implementation DARPA Data Transposition Benchmark Modifications to the C Map Implementation Let {Ai} be a stream of n-bit integers of length L. consider each successive block of n integers as a n x n matrix of bits. For each such matrix, transpose the bits such that bit bji is interchanged with bit bji. - Parallel sections for computation and data transfer. - Unrolled the inner loop. - In ‘n’ cycles we get all the ‘n’ outputs. - In ‘n’ cycles we read these ‘n’ values back to memory. - All benchmarks were implemented. • - 128-bit word transfers to 4 OBMs • - Effectively 2 word per cycle transfer • Transposition: • 2 units for 32&64-bit; 4 units for 1024-bit • 32-bit: read 8 words from 4 banks & use 4 bit shifts • 64-bit: read 4 words from 4 banks & use 2 bit shifts • 1024-bit: read 4 words and use 4 units in parallel • 4 OBMS for input and 2 for output • 2 Memory loop dependency cycles added to latency Timing Results Software Implementation Written in C and uses a two loop structure. SRC-6 Verilog Map Implementation Timing Results - The main program calls the map function. - The map functions calls a Verilog macro. - The Verilog macro implements the transposition. - Performance was better than C Map implementation. Timing Results Timing Results SRC-6 Reconfigurable Computer Performance Analysis Parallel 3-unit Implementation - Utilizes all the 6 available memory banks - 3 for input and 3 for output - Only one macro call from the map function - Verilog macro has 3 units working in parallel - Theoretically 3 times computational speedup - overall twice speedup * A- C Map, B-Verilog Map, C- Parallel 3-unit, D- 128-bit, E-Parallel 2-unit 128-bit SRC-6 Implementations Analysis - Parallelism - The SRC implementation- Two ways. - Transposition function in C – C Map. - Transposition function in Verilog – Verilog Map. • Parallel 3 unit: • 32-bit: 30%, 64-bit: 53%, 1024-bit: 47% • Parallel 2 unit 128-bit: • 32-bit: 26%, 64-bit: 40%, 1024-bit: 59% • Can have more parallel units • Will lead to bank conflicts • More memory banks: run out of I/O pins on FPGA SRC-6 C Map Implementation • - The main program calls a C map function. • - The parameters passed are the A, E values. • A has the input values, E has the output values. • The two loop structure was used for transposition. • Implementation was slower than software. // Assigning values for (i = 0; i < m; i++){ fscanf(in, "%lld", &temp); A[i] = temp; E[i] = 0; } for (j=0;j<230;j++){ for(k=0;k<nblocks;k++) // assign values in blocks of half // the bank capacity // call map function dt (A, E, m, &time, 0); …. } Timing Results Conclusions • SRC-6 computer provides great speedup • 75 times for 1024-bit benchmark • Parallelism exploited to a certain degree • Could explore: • Highly Parallel multi-PE architectures • Distributed memory architecture South Carolina COMPUTER SCIENCE & ENGINEERING