Download

1 / 56
560 likes | 660 Views
Explore the innovative projects of the IRAM and ISTORE team, from intelligent PDAs to system-on-a-chip technology and advanced software updates. Stay informed about the future of technology and hardware advancements.

E N D
IRAM and ISTORE Projects Aaron Brown, James Beck, Rich Fromm, Joe Gebis, Paul Harvey, Adam Janin, Dave Judd, Kimberly Keeton, Christoforos Kozyrakis, David Martin, Rich Martin, Thinh Nguyen, David Oppenheimer, Steve Pope, Randi Thomas, Noah Treuhaft, Sam Williams, John Kubiatowicz, Kathy Yelick, and David Patterson http://iram.cs.berkeley.edu/[istore] Winter 2000 IRAM/ISTORE Retreat
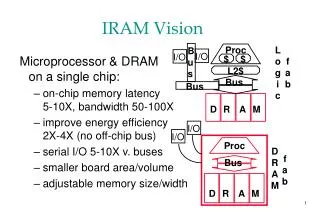
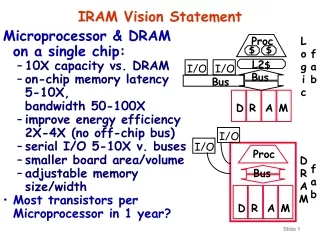
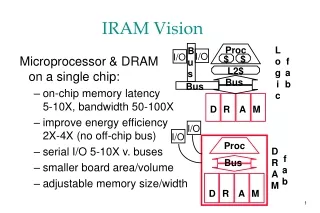
IRAM Vision: Intelligent PDA Pilot PDA + gameboy, cell phone, radio, timer, camera, TV remote, am/fm radio, garage door opener, ... + Wireless data (WWW) + Speech, vision, video + Voice output for conversations • Speech control +Vision to see, scan documents, read bar code, ...
ISTORE Hardware Vision • System-on-a-chip enables computer, memory, without significantly increasing size of disk • 5-7 year target: • MicroDrive:1.7” x 1.4” x 0.2” 2006: ? • 1999: 340 MB, 5400 RPM, 5 MB/s, 15 ms seek • 2006: 9 GB, 50 MB/s ? (1.6X/yr capacity,1.4X/yr BW) • Integrated IRAM processor • 2x height • Connected via crossbar switch • growing like Moore’s law • 10,000+ nodes in one rack!
C P U+$ 4 Vector Pipes/Lanes VIRAM: System on a Chip • Prototype scheduled for tape-out 1H 2000 • 0.18 um EDL process • 16 MB DRAM, 8 banks • MIPS Scalar core and caches @ 200 MHz • 4 64-bit vector unit pipelines @ 200 MHz • 4 100 MB parallel I/O lines • 17x17 mm, 2 Watts • 25.6 GB/s memory (6.4 GB/s per direction and per Xbar) • 1.6 Gflops (64-bit), 6.4 GOPs (16-bit) Memory(64 Mbits / 8 MBytes) Xbar I/O Memory(64 Mbits / 8 MBytes)
IRAM Architecture Update • ISA mostly frozen since 6/99 • better fixed-point model and instructions • gained some experience using them over past year • better exception model • better support for short vectors • auto-increment memory addressing • instructions for in-register reductions & butterfly-permutations • memory consistency model spec refined (poster) • Suite of simulators actively used and maintained • vsim-isa (functional), vsim-p (performance), vsim-db (debugger), vsim-sync (memory synchronization)
IRAM Software Update • Vectorizing Compiler for VIRAM • retargeting CRAY vectorizing compiler (talk) • Initial backend complete: scalar and vector instructions • Extensive testing for correct functionality • Instruction scheduling and performance tuning begun • Applications using compiler underway • Speech processing (talk) • Small benchmarks; suggestions welcome • Hand-coded fixed point applications • Video encoder application complete (poster) • FFT, floating point done, fixed point started (talk)
IRAM Chip Update • IBM to supply embedded DRAM/Logic (98%) • DRAM macro added to 0.18 micron logic process • DRAM specs under NDA; final agreement in UCB bureaucracy • MIPS to supply scalar core (99%) • MIPS processor, caches, TLB • MIT to supply FPU (100%) • single precision (32 bit) only • VIRAM-1 Tape-out scheduled for mid-2000 • Some updates of micro-architecture based on benchmarks (talk) • Layout of multiplier (poster), register file nearly complete • Test strategy developed (talk) • Demo system high level hardware design complete (talk) • Network interface design complete (talk)
2 arithmetic units both execute integer operations one executes FP operations 4 64-bit datapaths (lanes) per unit 2 flag processing units for conditional execution and speculation support 1 load-store unit optimized for strides 1,2,3, and 4 4 addresses/cycle for indexed and strided operations decoupled indexed and strided stores Memory system 8 DRAM banks 256-bit synchronous interface 1 sub-bank per bank 16 Mbytes total capacity Peak performance 3.2 GOPS64, 12.8 GOPS16 (w. madd) 1.6 GOPS64, 6.4 GOPS16 (wo. madd) 0.8 GFLOPS64, 3.2 GFLOPS32 (w. madd) 6.4 Gbyte/s memory bandwidth Microarchitecture configuration
Base-line system comparison • All numbers in cycles/pixel • MMX and VIS results assume all data in L1 cache
Scaling to 10K Processors • IRAM + micro-disk offer huge scaling opportunities • Still many hard system problems, SAM AME (talk) • Availability • 24 x7 databases without human intervention • Discrete vs. continuous model of machine being up • Maintainability • 42% of system failures are due to administrative errors • self-monitoring, tuning, and repair • Evolution • Dynamic scaling with plug-and-play components • Scalable performance, gracefully down as well as up • Machines become heterogeneous in performance at scale
Disk Half-height canister ISTORE-1: Hardware for AME Hardware: plug-and-play intelligent devices with self-monitoring, diagnostics, and fault injection hardware • intelligence used to collect and filter monitoring data • diagnostics and fault injection enhance robustness • networked to create a scalable shared-nothing cluster Intelligent Disk “Brick” Portable PC Processor: Pentium II+ DRAM Redundant NICs (4 100 Mb/s links) Diagnostic Processor • Intelligent Chassis • 80 nodes, 8 per tray • 2 levels of switches • 20 100 Mb/s • 2 1 Gb/s • Environment Monitoring: • UPS, redundant PS, • fans, heat and vibrartion sensors...
ISTORE Brick Block Diagram Mobile Pentium II Module SCSI North Bridge CPU Disk (18 GB) South Bridge Diagnostic Net DUAL UART DRAM 256 MB Super I/O Monitor & Control Diagnostic Processor BIOS Ethernets 4x100 Mb/s PCI • Sensors for heat and vibration • Control over power to individual nodes Flash RTC RAM
ISTORE Software Approach • Two-pronged approach to providing reliability: 1) reactive self-maintenance: dynamic reaction to exceptional system events • self-diagnosing, self-monitoring hardware • software monitoring and problem detection • automatic reaction to detected problems 2) proactive self-maintenance:continuous online self- testing and self-analysis • automatic characterization of system components • in situ fault injection, self-testing, and scrubbing to detect flaky hardware components and to exercise rarely-taken application code paths before they’re used
ISTORE Applications • Storage-intensive, reliable services for ISTORE-1 • infrastructure for “thin clients,” e.g., PDAs • web services, such as mail and storage • large-scale databases (talk) • information retrieval (search and on-the-fly indexing) • Scalable memory-intensive computations for ISTORE in 2006 • Performance estimates through IRAM simulation + model • not major emphasis • Large-scale defense and scientific applications enabled by high memory bw and arithmetic performance
Performance Availability • System performance limited by the weakest link • NOW Sort experience: performance heterogeneity is the norm • disks: inner vs. outer track (50%), fragmentation • processors: load (1.5-5x) and heat • Virtual Streams: dynamically off-load I/O work from slower disks to faster ones
ISTORE Update • High level hardware design by UCB complete (talk) • Design of ISTORE boards handed off to Anigma • First run complete; SCSI problem to be fixed • Testing of UCB design (DP), to start asap • 10 nodes by end of 1Q 2000, 80 by 2Q 2000 • Design of BIOS handed off to AMI • Most parts donated or discounted • Adaptec, Andataco, IBM, Intel, Micron, Motorola, Packet Engines • Proposal for Quantifying AME (talk) • Beginning work on short-term applications • Mail server • Web server will be used to • Large database drive principled • Decision support primitives system design
Conclusions • IRAM attractive for two Post-PC applications because of low power, small size, high memory bandwidth • Mobile consumer electronic devices • Scaleable infrastructure • IRAM benchmarking result: faster than DSPs • ISTORE: hardware/software architecture for large scale network services • Scaling systems requires • new continuous models of availability • performance not limited by the weakest link • self* systems to reduce human interaction
Introduction and Ground Rules • Who is here? • Mixed IRAM/ISTORE “experience” • Questions are welcome during talks • Schedule: lecture from Brewster Kahle during Thursday’s Open Mic Session. • Feedback is required (Fri am) • Be careful, we have been known to listen to you • Mixed experience: please ask • Time for skiing and talking tomorrow afternoon
2006 ISTORE • ISTORE node • Add 20% pad to MicroDrive size for packaging, connectors • Then double thickness to add IRAM • 2.0” x 1.7” x 0.5” (51 mm x 43 mm x 13 mm) • Crossbar switches growing by Moore’s Law • 2x/1.5 yrs 4X transistors/3yrs • Crossbars grow by N2 2X switch/3yrs • 16 x 16 in 1999 64 x 64 in 2005 • ISTORE rack (19” x 33” x 84”)1 tray (3” high) 16 x 32 512 ISTORE nodes / try • 20 trays+switches+UPS 10,240 ISTORE nodes / rack (!)
IRAM/VSUIF Decryption (IDEA) • IDEA Decryption operates on 16-bit ints • Compiled with IRAM/VSUIF • Note scalability of both #lanes and data width • Some hand-optimizations (unrolling) will be automated by Cray compiler # lanes Virtual processor width
1D FFT on IRAM FFT study on IRAM • bit-reversal time included; cost hidden using indexed store • Faster than DSPs on floating point (32-bit) FFTs • CRI Pathfinder does 24-bit fixed point, 1K points in 28 usec (2 Watts without SRAM)
3D FFT on ISTORE 2006 • Performance of large 3D FFT’s depend on 2 factors • speed of 1D FFT on a single node (next slide) • network bandwidth for “transposing” data • 1.3 Tflop FFT possible w/ 1K IRAM nodes, if network bisection bandwidth scales (!)
Brick shelf Brick shelf Brick shelf Brick shelf Brick shelf Brick shelf Brick shelf Brick shelf ISTORE-1 System Layout
I/O I/O 100MB each Memory Crossbar Switch M M M M M M M M M M … M M M M M M M M M M 4 x 64 4 x 64 4 x 64 4 x 64 4 x 64 I/O … … … … … … … … … … I/O M M M M M M M M M M V-IRAM1: 0.18 µm, Fast Logic, 200 MHz1.6 GFLOPS(64b)/6.4 GOPS(16b)/32MB + x 2-way Superscalar Vector 4 x 64 or 8 x 32 or 16 x 16 Instruction ÷ Processor Queue Load/Store 16K I cache 16K D cache Vector Registers 4 x 64 4 x 64
Fixed-point multiply-add model • Same basic model, different set of instructions • fixed-point: multiply & shift & round, shift right & round, shift left & saturate • integer saturated arithmetic: add or sub & saturate • added multiply-add instruction for improved performance and energy consumption Multiply half word & Shift & Round Add & Saturate z x n w + n/2 sat * n n Round y n n/2 a
Other ISA modifications • Auto-increment loads/stores • a vector load/store can post-increment its base address • added base (16), stride (8), and increment (8) registers • necessary for applications with short vectors or scaled-up implementations • Butterfly permutation instructions • perform step of a butterfly permutation within a vector register • used for FFT and reduction operations • Miscellaneous instructions added • min and max instructions (integer and FP) • FP reciprocal and reciprocal square root
Major architecture updates • Integer arithmetic units support multiply-add instructions • 1 load store unit • complexity Vs. benefit • Optimize for strides 2, 3, and 4 • useful for complex arithmetic and image processing functions • Decoupled strided and indexed stores • memory stalls due to bank conflicts do not stall the arithmetic pipelines • allows scheduling of independent arithmetic operations in parallel with stores that experience many stalls • implemented with address, not data, buffering • currently examining a similar optimization for loads
Micro-kernel results: simulated systems • Note : simulations performed with 2 load-store units and without decoupled stores or optimizations for strides 2, 3, and 4
Micro-kernels • Vectorization and scheduling performed manually
Scaled system results • Near linear speedup for all application apart from iDCT • iDCT bottlenecks • large number of bank conflicts • 4 addresses/cycle for strided accesses
iDCT scaling with sub-banks • Sub-banks reduce bank conflicts and increase performance • Alternative (but not as effective) ways to reduce conflicts: • different memory layout • different address interleaving schemes
Compiling for VIRAM • Long-term success of DIS technology depends on simple programming model, i.e., a compiler • Needs to handle significant class of applications • IRAM: multimedia, graphics, speech and image processing • ISTORE: databases, signal processing, other DIS benchmarks • Needs to utilize hardware features for performance • IRAM: vectorization • ISTORE: scalability of shared-nothing programming model
IRAM Compilers • IRAM/Cray vectorizing compiler [Judd] • Production compiler • Used on the T90, C90, as well as the T3D and T3E • Being ported (by SGI/Cray) to the SV2 architecture • Has C, C++, and Fortran front-ends (focus on C) • Extensive vectorization capability • outer loop vectorization, scatter/gather, short loops, … • VIRAM port is under way • IRAM/VSUIF vectorizing compiler [Krashinsky] • Based on VSUIF from Corinna Lee’s group at Toronto which is based on MachineSUIF from Mike Smith’s group at Harvard which is based on SUIF compiler from Monica Lam’s group at Stanford • This is a “research” compiler, not intended for compiling large complex applications • It has been working since 5/99.
Vectorizer Code Generators Frontends C PDGCS C90 C++ IRAM Fortran IRAM/Cray Compiler Status • MIPS backend developed in this year • Validated using a commercial test suite for code generation • Vector backend recently started • Testing with simulator under way • Leveraging from Cray • Automatic vectorization
VIRAM/VSUIF Matrix/Vector Multiply • VIRAM/VSUIF does reasonably well on long loops • 256x256 single matrix • Compare to 1600 Mflop/s (peak without multadd) • Note BLAS-2 (little reuse) • ~350 on Power3 and EV6 • Problems specific to VSUIF • hand strip-mining results in short loops • reductions • no multadd support mvm vmm
ISTORE API Provided byApplication Reaction mechanisms Coordinationof reaction Policies Provided by ISTORE Runtime System Problem detection SW monitoring Self-monitoringhardware Reactive Self-Maintenance • ISTORE defines a layered system model for monitoring and reaction: • ISTORE API defines interface between runtime system and app. reaction mechanisms • Policies define system’s monitoring, detection, and reaction behavior
Proactive Self-Maintenance • Continuous online self-testing of HW and SW • detects flaky, failing, or buggy components via: • fault injection: triggering hardware and software error handling paths to verify their integrity/existence • stress testing: pushing HW/SW components past normal operating parameters • scrubbing: periodic restoration of potentially “decaying” hardware or software state • automates preventive maintenance • Dynamic HW/SW component characterization • used to adapt to heterogeneous hardware and behavior of application software components
ISTORE-0 Prototype and Plans • ISTORE-0: testbed for early experimentation with ISTORE research ideas • Hardware: cluster of 6 PCs • intended to model ISTORE-1 using COTS components • nodes interconnected using ISTORE-1 network fabric • custom fault-injection hardware on subset of nodes • Initial research plans • runtime system software • fault injection • scalability, availability, maintainability benchmarking • applications: block storage server, database, FFT
Runtime System Software • Demonstrate simple policy-driven adaptation • within context of a single OS and application • software monitoring information collected and processed in realtime • e.g.,health & performance parameters of OS, application • problem detection and coordination of reaction • controlled by a stock set of configurable policies • application-level adaptation mechanisms • invoked to implement reaction • Use experience to inform ISTORE API design • Investigate reinforcement learning as technique to infer appropriate reactions from goals
Record-breaking performance is not the common case • NOW-Sort records demonstrate peak performance • But perturb just 1 of 8 nodes and...
Process Arbiter Virtual Streams Software Disk Virtual Streams:Dynamic load balancing for I/O • Replicas of data serve as second sources • Maintain a notion of each process’s progress • Arbitrate use of disks to ensure equal progress • The right behavior, but what mechanism?
Before Slowdown After Slowdown Client0 B Client1 B Client2 B Client3 B Client0 7B/8 Client1 7B/8 Client2 7B/8 Client3 7B/8 To Client0 To Client0 B/2 B/4 B/2 B/2 B/2 B/2 5B/8 3B/8 B/2 B/2 B/2 B/2 3B/8 B/4 B/2 B/2 B/2 5B/8 From Server3 From Server3 0 0 1 1 1 1 2 2 2 2 3 3 3 3 0 0 Server0 B Server1 B Server2 B Server3 B Server0 B Server1 B/2 Server2 B Server3 B Graduated Declustering:A Virtual Streams implementation • Clients send progress, servers schedule in response
Storage Priorities: Research v. Users Traditional Research Priorities 1) Performance 1’) Cost 3) Scalability 4) Availability 5) Maintainability ISTORE Priorities 1) Maintainability 2) Availability 3) Scalability 4) Performance 5) Cost } easy to measure } hard to measure
Intelligent Storage Project Goals • ISTORE: a hardware/software architecture for building scaleable, self-maintaining storage • An introspective system: it monitors itself and acts on its observations • Self-maintenance: does not rely on administrators to configure, monitor, or tune system
Self-maintenance • Failure management • devices must fail fast without interrupting service • predict failures and initiate replacement • failures immediate human intervention • System upgrades and scaling • new hardware automatically incorporated without interruption • new devices immediately improve performance or repair failures • Performance management • system must adapt to changes in workload or access patterns
ISTORE-I: 2H99 • Intelligent disk • Portable PC Hardware: Pentium II, DRAM • Low Profile SCSI Disk (9 to 18 GB) • 4 100-Mbit/s Ethernet links per node • Placed inside Half-height canister • Monitor Processor/path to power off components? • Intelligent Chassis • 64 nodes: 8 enclosures, 8 nodes/enclosure • 64 x 4 or 256 Ethernet ports • 2 levels of Ethernet switches: 14 small, 2 large • Small: 20 100-Mbit/s + 2 1-Gbit; Large: 25 1-Gbit • Just for prototype; crossbar chips for real system • Enclosure sensing, UPS, redundant PS, fans, ...