Download
1 / 20
200 likes | 231 Views
Understand sample covariance, correlation coefficient, and confidence intervals for population parameters with given probability levels. Explore examples and formulas for calculating reliable estimates in statistical analysis.

E N D
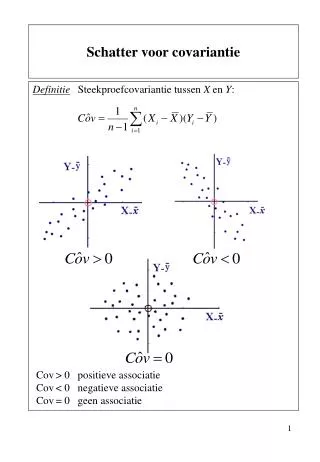
Schatter voor covariantie Definitie Steekproefcovariantie tussen X en Y: Cov> 0 positieve associatie Cov< 0 negatieve associatieCov= 0 geen associatie
Schatter voor , steekproefcorrelatiecoëfficiënt r DefinitieCorrelatiecoëfficiënt R beschrijft de mate van lineaire samenhang tussen twee paarsgewijs waargenomen continue stochastische variabelen X en Y. Bekijk ook: 'Guessing correlations’ en gok zelf correlaties.
Intervalschatters is een puntschatter voor . Maar wat is de betrouwbaarheid van die schatter? Dit drukken we uit met een betrouwbaarheidsinterval: Definitie Een betrouwbaarheidsinterval (confidence interval) voor een populatieparameter is een interval dat deze parameter bevat met een bepaalde waarschijnlijkheid. Voorbeeld Een 95% - betrouwbaarheidsinterval voor de gemiddelde lengte van een tweedejaars mannelijke student is het interval (1.78m , 1.82m) Let op! Dit betekent niet dat 95% van deze studenten een lengte heeft tussen de 1.78 en 1.82. Het betekent dat we 95% zeker zijn, op basis van de gegevens die we hebben, dat het populatiegemiddelde (dus het gemiddelde van alle 2e jaars mannelijke studenten) tussen 1.78 en 1.82 ligt.
Betrouwbaarheidsintervallen voor µ, Variantie bekend Een aantal situaties: • We hebben één steekproef X1, ..., Xn , veronderstelling: Xi ~ N(,2) • We hebben een gepaarde steekproef ((Y1, Z1), ..., (Yn , Zn)). Noem Xi = Yi- Zi en neem aan Xi ~ N(,2). • We hebben twee onafhankelijke steekproeven Y1, ..., Ym en Z1, ..., Zn. Verder Yi ~ N(1, 2) en Zi ~ N(2,2). Definieer = 1 - 2. Noem In alle gevallen zijn we geïnteresseerd in een b.i. voor . In alle gevallenis de puntschatter voor . We veronderstellen in eerste instantiedat de varianties bekend zijn. Het tweezijdige (1-)*100% b.i. voor heeft dan altijd precies dezelfde vorm: waarbij z/2het percentagepunt van de standaardnormale verdeling is zdd P(Z > z/2) = / 2.
Voorbeeld 1, gepaarde waarnemingen. Stel we hebben twee methoden om de dikte van een bloedvat te meten m.b.v. een scan: handmatig en automatisch. We willen het verschil tussen de twee methoden quantificeren en daarom passen we de methoden toe op 25 dezelfde bloedvaten. We krijgen zo dus 25 gepaarde waarnemingen. We gaan er vanuit dat we de variantie van het verschil tussen de twee methoden voor één bloedvat weten. Deze is gelijk aan 0.25. We berekenen de 25 verschillen (handmatig minus automatisch) en het gemiddelde van de 25 verschillen. We vinden -0.2. Hoe zit het 90% b.i. voor het populatiegemiddelde eruit? Invullen geeft waarbij z0.05 = 1.65. Nb: hier zit ‘0’ niet in!
Voorbeeld 2, verschil tussen twee groepen Stel we hebben twee groepen patiënten die we behandelen met twee verschillende cholesterol verlagende middelen. We gaan er vanuit dat de aanvangsnivo’s van het choles-terol hetzelfde zijn en we meten de verlaging in beide groepen. De variantie op de verlaging is bekend en gelijk aan 25 in beide groepen. Groep 1 bevat 100 mensen, groep 2 bevat er maar 25. We meten een gemiddelde verlaging van 40 in groep 1 en een gemiddelde verlaging van 20 in groep 2. Gevraagd: een 95% tweezijdig b.i. voor het verschil tussen de verlaging in groep 1 en groep 2. We schatten dat verschil simpelweg door Wat is de variantie van deze schatter? Nu is het een kwestie van invullen om het 95% b.i. te krijgen: waarbij z0.025 = 1.96.
Betrouwbaarheidsintervallen voor µ, Variantie onbekend Zelfde situaties, maar nu variantie onbekend: • We hebben één steekproef X1, ..., Xn , veronderstelling: Xi ~ N(,2) • We hebben een gepaarde steekproef ((Y1, Z1), ..., (Yn , Zn)). Noem Xi = Yi- Zi en neem aan Xi ~ N(,2). In beide gevallen zijn we geïnteresseerd in een b.i. voor . In beide gevallenis de puntschatter voor . Het tweezijdige (1-)*100% b.i. voor heeft dan altijd precies dezelfde vorm: waarbij t/2,n-1het (1- /2)*100% percentagepunt van de t-verdeling met n – 1 vrijheidsgraden (degrees of freedom, df ) is en is de steekproefschatter van de standaard-deviatie van het gemiddelde
Voorbeeld 3, vervolg voorbeeld 1. Stel we hebben twee methoden om de dikte van een bloedvat te meten m.b.v. een scan: handmatig en automatisch. We willen het verschil tussen de twee methoden quantificeren en daarom passen we de methoden toe op 10 dezelfde bloedvaten. We krijgen zo dus 10 gepaarde waarnemingen. Variantie is nu onbekend. Data zien er alsvolgt uit: Hoe zit het 90% b.i. voor het populatiegemiddelde eruit? Invullen geeft Nb: hier zit ‘0’ niet in!
Betrouwbaarheidsintervallen voor µ, Variantie onbekend, twee groepen Nu variantie onbekend: We hebben twee onafhankelijke steekproeven Y1, ..., Ym en Z1, ..., Zn. Verder Yi ~ N(1, 2) en Zi ~ N(2,2). Definieer = 1 - 2. Noem Twee gevallen: • veronderstel varianties gelijk: = • varianties ongelijk: We zijn geïnteresseerd in een b.i. voor . In beide gevallenis de puntschatter voor . Geval 1. Gepoolde variantie is schatter van 2en 2: Het tweezijdige (1-)*100% b.i. voor : waarbij t/2,n+m-2het (1 - /2)*100% percentagepunt van de t-verdeling met n+m – 2 vrijheidsgraden is.
Betrouwbaarheidsintervallen voor µ, Variantie onbekend, twee groepen Variantie onbekend: We hebben twee onafhankelijke steekproeven Y1, ..., Ym en Z1, ..., Zn. Verder Yi ~ N(1, 2) en Zi ~ N(2,2). Definieer = 1 - 2. Noem Geval 2 (varianties niet gelijk). Het tweezijdige (1-)*100% b.i. voor : waarbij t/2,het (1 - /2)*100% percentagepunt van de t-verdeling met vrijheidsgraden is.
Voorbeeld 4, vervolg van voorbeeld 3. We hebben dezelfde twee methoden om de dikte van een bloedvat te meten m.b.v. een scan: handmatig en automatisch. We willen het verschil tussen de twee methoden quantificeren en passen nu de methoden toe op 10 verschillende bloedvaten elk, dus 20 in totaal. Variantie is nu onbekend, maar wordt gelijk verondersteld. Data zien er alsvolgt uit: Dus het tweezijdig 90% b.i. voor (‘het verschil’)is: NB: ‘0’ zit hier wel in!
Eenzijdige betrouwbaarheidsgrens voor µ Alle voorgaande betrouwbaarheidsintervallen zijn tweezijdig. Voor een tweezijdig (1-)*100% interval (L,R) geldt dat µ met ‘kans’ /2 groter is dan r en met kans /2 kleiner is dan L. Een(1-)*100% rechtseenzijdige betrouwbaarheids-grens (upper confidence bound) R is die grens zodanig dat de populatieparameter met ‘kans’ 1- kleiner is dan die grens. Een(1-)*100% linkseenzijdige betrouwbaarheids-grens (lower confidence bound) L is die grens zodanig dat de populatieparameter met ‘kans’ 1- groter is dan die grens. Formules zijn exact hetzelfde als voor de grenzen van het tweezijdige interval, maar vervang /2 door !!! M.a.w. de linkergrens van een tweezijdig (1-2)*100% interval is gelijk aan de (1-)*100% linkseenzijdige betrouwbaarheidsgrens.
Eenzijdige betrouwbaarheidsgrens, Voorbeeld 5, vervolg voorbeeld 3 • Twee methoden om de dikte van een bloedvat te meten • Handmatig en automatisch. • Gepaarde waarnemingen. Variantie is onbekend. Stel we willen nu een 95% rechtseenzijdige betrouwbaar-heidsgrens voor µ: het verschil ‘handmatig – automatisch’, zodat we weten dat dit populatieverschil met 95% betrouwbaarheid kleiner is dan die grens. Het tweezijdige 90% betrouwbaarheidsinterval voor µ was (zie voorbeeld 3): (-0.21, -0.03). Hier geldt = 0.1 = 2*0.05, dus –0.03 is de gevraagde 95% rechtseenzijdige betrouwbaarheidsgrens. In het Statistisch Compendium staan alleen formules voor tweezijdige intervallen. Let dus goed op met de .
Interpretatie betrouwbaarheidsinterval Een betrouwbaarheidsinterval voor een populatie-parameter is een interval dat deze parameter bevat met een bepaalde waarschijnlijkheid. ‘Waarschijnlijkheid’ (of betrouwbaarheid) van bijv. 95% moet hierbij alsvolgt opgevat worden: als je het interval 100 keer op zou stellen, dus je doet 100 experimenten onder dezelfde omstandigheden, dan zal het interval 95 van de 100 keer de ware waarde van de populatieparameter (bijv. µ) bevatten. Dit wordt duidelijk m.b.v. de volgende applet: Construct confidence interval Je gebruikt de steekproeven ( ) om een interval te schatten voor de populatieparameter waarin je geïnteresseerd bent (meestal µ). Dus een betrouwbaar-heidsinterval voor is onzin, want dit zijn geen populatieparameters.
Breedte van een betrouwbaarheidsinterval voor µ Eigenschappen betrouwbaarheidsintervallen voor µ De breedte van een b.i. • neemt toe als betrouwbaarheid 1– toeneemt (dus onbetrouwbaarheid neemt af). ‘Betrouwbaarheid’ is de waarschijnlijkheid waarmee het interval de ware waarde van bevat. • neemt af bij toenemende steekproefomvangen (n,m). Immers in dat geval is de schatting voor steeds beter, spreiding van neemt af en dus zijn minder waardes van ‘waarschijnlijk’.
Samenvatting betrouwbaarheids-intervallen voor µ Belangrijkste vraag: welk interval heb ik nodig in welke situatie? Ga het volgende na: • Wordt er gevraag om een eenzijdige betrouwbaar-heidsgrens of een tweezijdig interval? Eenzijdig: links of rechts, gebruik i.p.v. /2 in formules. • Hebben we te maken met gepaarde waarnemingen (dus steeds twee waarnemingen op hetzelfde object/individu) of niet? • Zijn de varianties bekend en gegeven? Gebruik dan de z -waarden (percentagepunten) • Zijn de varianties onbekend, gebruik dan de t– waarden met het juiste aantal vrijheidsgraden. Worden de variantie gelijk verondersteld of niet?
Betrouwbaarheidsinterval voor 2 We hebben één steekproef X1, ..., Xn , veronderstelling: Xi ~ N(,2) Puntschatting voor 2: Tweezijdig (1-)*100% b.i. voor 2: waarbij het (1- /2)*100% percentagepunt van de 2verdeling met n – 1 vrijheidsgraden (degrees of freedom) is. Eenzijdig: gebruik linker- of rechtergrens met /2 vervangen door .
Voorbeeld 6, vervolg voorbeeld 3. We hadden de volgende gepaarde bloedvatdikte waarnemingen: Het tweezijdig 95% b.i. voor 2 is nu: De puntschatting voor 2 is (0.155)2 = 0.024, dus dit is geen symmetrisch interval.
Betrouwbaarheidsinterval voor succeskans p Stel we doen n onafhankelijke experimenten elk met onbekende succeskans p. We willen p schatten en er een betrouwbaarheidsinterval voor opstellen. X: aantal successen in n experimenten. We weten dat X binomiaal verdeeld is met parameters p en n. Logische schatter voor p: X isbij benadering normaal verdeeld is als np > 5en n(1 – p) > 5. Tweezijdig (1-)*100% b.i. voor p: waarbij z/2het percentagepunt van de standaard-normale verdeling is.
Voorbeeld 7 Van een bepaald casino vermoedt de kansspel-commissie dat ze de boel belazeren. Hun roulettetafel zou niet zuiver zijn en de kans op ‘0’ zou groter zijn dan 1/37, waardoor klanten meer kans hebben hun inzet te verliezen. Daarom wordt de tafel 2000 keer getest, waarvan 90 keer een ‘0’ valt. We willen nu weten of de ware ‘succeskans’(=kans op ‘0’) te groot is. Daarom zoeken we een 99% linkseenzijdig betrouwbaarheidsgrens voor p, want als deze grens voorbij 1/37 ligt, kunnen we met 99% zekerheid stellen dat p te groot is en dus het casino de boel belazert. Deze grens is gelijk aan Dus de kans op ‘0’ is voor 99% zeker groter of gelijk aan 0.038 en dat is groter dan 1/37 = 0.027. Dus we kunnen met grote zekerheid stellen dat dit casino fraudeert.





















