Download

1 / 36
360 likes | 478 Views
2.6 Parte di controllo (control path). ha il compito di generare i segnali di comando sincronizzando le varie unità che compongono la parte operativa (data path)

E N D
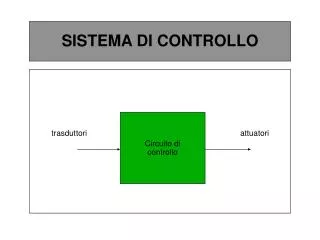
2.6 Parte di controllo (control path) • ha il compito di generare i segnali di comando sincronizzando le varie unità che compongono la parte operativa (data path) • è un enorme automa sequenziale che ha come ingressi l’istruzione in corso e lo stato attuale della CPU, e come uscite i comandi alla parte operativa e lo stato successivo Architettura degli elaboratori 1 - A. Memo
2.6 Parte di controlloi comandi del datapath piccola sezione di datapath con evidenziati i comandi di sincronizzazione Architettura degli elaboratori 1 - A. Memo
2.6 Parte di controllodiagramma degli stati • emettere IP nell’Address Bus: • demux IPOUT emette dati in uscita A • in attesa del dato dalla memoria: • demux IPOUT emette dati in uscita B • impostare inc/dec a incremento • memorizzare il risultato in T1 • aggiorna IP: • mux IPIN legge dati da ingresso B • memorizza il dato in registro IP Architettura degli elaboratori 1 - A. Memo
2.6 Parte di controllohardwired implementazione tradizionale partendo dall’automa a stati finiti Architettura degli elaboratori 1 - A. Memo
2.6 Parte di controllomicroprogrammazione 1 La tendenza è quella di avere istruzioni sempre più complesse, il che comporta: • semplificare la programmazione • diminuire il numero di istruzioni per programma • ridurre lo spazio in memoria • complicare enormemente la logica di controllo La soluzione è adottare la microprogrammazione Architettura degli elaboratori 1 - A. Memo
2.6 Parte di controllomicroprogrammazione 2 Individuare per ogni istruzione (macro instruction) i comandi (micro code) da emettere, raggrupparli in blocchi eseguibili in parallelo (micro instruction), e implementarli in una struttura interna alla CPU simile ad un piccolo elaboratore, con la sua memoria programmi (microprogrammed ROM) Architettura degli elaboratori 1 - A. Memo
2.6 Parte di controllomicroprogrammazione 3 ogni macro instruction punta ad una sequenza di micro instruction Architettura degli elaboratori 1 - A. Memo
2.6 Parte di controllomicroprogrammazione 4 La microprogrammazione ... • è facile da progettare ed implementare • è flessibile negli sviluppi futuri • rende poco influente l’architettura interna • permette ottimizzazioni distinte • è più lenta dell’implementazione hardwired Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioni Il set di istruzioni di una CPU specifica • quali sono le istruzioni previste • quali operandi sono ammessi • il formato con cui vengono codificate • la loro durata in cicli di clock Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioniclassificazioni • in base alla localizzazione interna degli operandi • stack • accumulatore • registro (reg/mem) • registro (reg/reg) • ad accesso diretto (mem/mem) • in base alle tecniche di indirizzamento • in base alla complessità delle istruzioni Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzionia stack • gli operandi sono posti nella parte alta dello stack • istruzioni molto corte • codice poco efficiente • valutatori delle espressioni semplificati (notazione polacca inversa) • lo stack diventa un collo di bottiglia stack PUSH X PUSH Y ADD POP Z Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioniad accumulatore • l’ALU utilizza l’accumulatore come registro predefinito • istruzioni corte • semplifica il control path ed il data path • frequenti spostamenti da/per altri registri • poco efficente accumulatore LOAD X ADD Y STORE Z Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzionia registro (reg/mem) • in presenza di due operandi, almeno uno è un registro • istruzioni lunghe • buona efficienza di programmazione • riduzione degli accessi alla memoria • scarso bilanciamento delle istruzioni registro (r/m) LOAD R1,X ADD R1,Y STORE Z, R1 Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzionia registro (reg/reg) • gli operandi delle operazioni sono solo registri e quindi gli accessi alla memoria devono avvenire precedentemente tramite un registro (qualsiasi) • codifica a lunghezza fissa • istruzioni a durata bilanciata registro (reg/reg) LOAD R1,X LOAD R2,Y ADD R3,R1,R2 STORE Z, R3 Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioniad accessi diretti (mem/mem) • uso delle locazioni di memoria come operandi • massima semplicità di programmazione • lunghezza delle istruzioni molto variabile • alto sbilanciamento delle istruzioni • l’accesso alla memoria diventa un collo di bottiglia memoria/memoria ADD Z,X,Y Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzionievoluzione commerciale Accumulatore singolo (EDVAC) [1950] Accumulatore + registri indice (Mark 1, IBM 700) [1953] registri General Purpose CISC (VAX, Intel) Load/Store (CDC 6600, Cray 1) RISC (Mips, Spark, IBM) Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioniaccesso alla memoria 1 • la memoria viene vista (quasi) sempre dal programmatore in L.M. come un vettore lineare di elementi ad 8 bit • ad ogni accesso alla memoria, alla CPU arriva un multiplo di byte (dimensione DB) • memoria allineata • memoria non allineata Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioniaccesso alla memoria 2 Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioniaccesso alla memoria 3 Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioniaccesso alla memoria 4 • memoria non allineata (Intel x86) • accessi ottimizzati • hardware più complesso • memoria allineata (Motorola 68000) • lettura più lenta dei dati disallineati • con l’uso di compilatori adeguati i dati possono essere memorizzati opportunamente Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzionitecniche di indirizzamento 1 modalità esempio significato registro MOV AL,BL AL Ü AL+1 immediato MOV AL,10 AL Ü 10 diretto MOV AL,[0123] AL Ü Mem[0123] indicizzato MOV AL,[SI] AL Ü Mem[SI] con base MOV AL,[BX+30] AL Ü Mem[BX+30] index+base MOV AL,[SI+BX] AL Ü Mem[SI+BX] Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzionitecniche di indirizzamento 2 modalità esempio significato indiretto MOV AL,@RX AL Ü Mem[Mem[RX]] fatt. scala MOV AL,[BX +SI*d] AL Ü Mem[BX+SI*d] auto inc. MOV RX,[RY]+ AL Ü Mem[RY] RY = RY + d auto dec. MOV RX,-[RY] RY = RY - d AL Ü Mem[RY] Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioni indirizzamenti Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzionitecniche di indirizzamento 4 • più indirizzamenti ci sono e più semplice è la programmazione diretta • più indirizzamenti ci sono e più complicati e difficilmente ottimizzati sono i compilatori • più indirizzamenti ci sono e più complessa risulta la parte di controllo • statisticamente sono pochi gli indirizzamen-ti utilizzati Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzionitipi di operazioni Le istruzioni si possono dividere in • trasferimento dati (*) • aritmetiche e logiche (*) • salto, ripetizione e controllo (*) • gestione stack • per dati specifici (FP, stringa) • I/O Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzionitrasferimento dati • da registro a registro MOV AL,BL • da memoria a registro MOV AL,[0123] • da registro a memoria MOV [0123],AL • distinto tra lettura e scrittura • LOAD R1,0123 • STORE 0123,R1 Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioniaritmetiche e logiche • somma/sottrazione ADD AL,BL SUB CX,AX • confronto CMP AL,33 TEST AH,CH • moltiplic./divis. MUL BL DIV AX • logiche OR AL,AH NEG AL • spostamento bit ROL AH,2 SHR AL,1 • sui bit di flag CLC STI Architettura degli elaboratori 1 - A. Memo
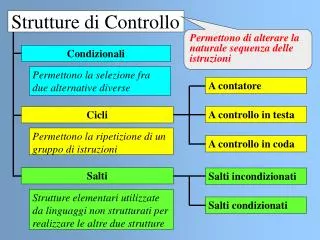
2.7 Set di istruzionisalto, ripetizione e controllo • salto incondizionato JMP 0456 • salto condizionato JZ 0100JNC 2211 JNA 1234JG 0101 • ciclo di ripetizione LOOP 0345 • salto a/da procedure CALL 0123RET • interruzione INT 21 IRET • sistema HLT NOP Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzionigestione stack 1 • lo stack è una coda LIFO che permette di salvare e recuperare dati senza curarsi del loro indirizzo • è una tecnica a lettura distruttiva • viene usato per • salvataggio contesto durante le interruzioni o le chiamate a procedure • passaggio parametri Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzionigestione stack 2 MOV AX,1234 PUSH AX • PUSH AX • DEC SP • MOV [SP],AXhigh • DEC SP • MOV [SP], AXlow prima dopo Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzionigestione stack 3 POP AX • POP AX • MOV AXlow,[SP] • INC SP • MOV AXhigh,[SP] • INC SP prima dopo Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioniper dati specifici • per stringa LODSB CMPSW (implicito AL, sorgente DS:SI, destinazione ES:DI) • ripetizione di stringa REPZ CMPSW • Floating Point FADD ST, ST[2] • BCD Packed DAA Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioniI/O • ingresso dati IN AL,DX • emissione dati OUT DX,AL Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioniformato delle istruzioni 1 • è il codice con cui vengono rappresentate le varie istruzioni • dipende dal set di istruzioni e dall’architet-tura interna adottata • può essere a lunghezza fissa o variabile (Intel da 1 a 12 byte) • compatibilità verso il basso Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioniformato delle istruzioni 2 codice operativo (1 byte) TTTTTTTT codice operativo (eventuale secondo byte) TTTTTTTT modalità di indirizzamento (ed altri b.c.o.) mod TTT r/m fattore di scala, reg. indice e reg. base (1) ss_index spiazzamento, 0, 1, 2 o 4 byte displacemen dato immediato, 0, 1, 2 o 4 byte immediate Architettura degli elaboratori 1 - A. Memo
2.7 Set di istruzioniformato delle istruzioni 3 Ad esempio ADD AL, BL codifica: 00 D8 formato reg1 to reg2 = 00TTT00w 11 reg1 reg2 oper. TTT ADD 000 ADC 010 AND 100 OR 001 SUB 101 SBB 011 XOR 110 reg cod AL 000 CL 001 DL 010 BL 011 AH 100 CH 101 DH 110 BH 111 dimensione operandi 8 bit w=0 16/32 bit w=1 TTT = 000 (ADD) w = 0 (8 bit) reg1 = 011 (BL) reg2 = 000 (AL) codifica = 00000000 11011000 Architettura degli elaboratori 1 - A. Memo