Download
1 / 40
400 likes | 826 Views
Chapter 5. PROTEIN SYNTHESIS. 5.1 One Gene - One Polypeptide Hypothesis. Garrod studied families with alkaptonuria - a disease in which alkapton is found in high concentrations in the urine turning it black.

E N D
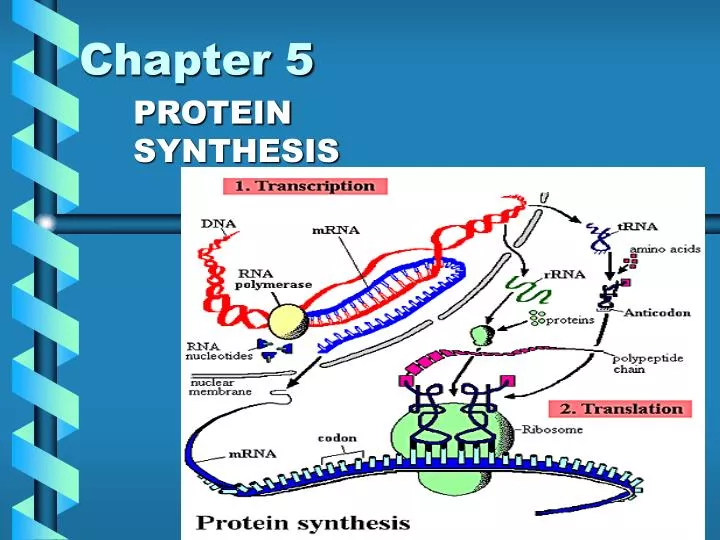
Chapter 5 PROTEIN SYNTHESIS
5.1 One Gene - One Polypeptide Hypothesis • Garrod studied families with alkaptonuria - a disease in which alkapton is found in high concentrations in the urine turning it black. • He proposed an "inborn error of metabolism" in which there was an error in the enzyme responsible for breaking down alkapton.
Beadle and Tatum - One Gene - One Enzyme Hypothesis • demonstrated the relationship between genes and enzymes using red bread mould
i.Neurospora (bread mold) - can survive with minimal nutrients, however some mutants were not able to survive why? • ii.Looked at metabolic pathway for the synthesis of arginine- they distinguished mutants by which substance needed to be added to the medium in order for the mold to grow • Precursor enzyme Aornithine enzyme B citrulline enzyme C arginine enzyme D arginine Succinate • Conclusion: each mutant lacked a different functional enzyme, thus blocked at different parts of the metabolic pathway
Genes not only code for enzymes, but code for proteins, such as hemoglobin, that are made up of more than one polypeptide. • Significance of Ingram's findings: he linked a human abnormality (sickle cell disease) to a single alteration in the amino acid sequence of the hemoglobin protein.
The Central Dogma • ·The central dogma of molecular biology deals with the detailed residue-by-residue transfer of sequential information. • ·It states that information cannot be transferred back from protein to either protein or nucleic acid. DNA RNA protein • DNA cannot leave the nucleus (keeps it from being damaged)
THE GENETIC CODE • There are 20 amino acids, but only four different nitrogenous bases. To code for all amino acids, a sequence of three nucleotides must be used for each amino acid. • Each triplet is called a codon • Because there are 64 different arrangements of the four possible bases in groups of codons, and there are only 20 amino acids, some amino acids have several different codes, resulting in some redundancy in the genetic code. • One codon serves as the start codon and others serve as the stop codons.
Stage 1: TRANSCRIPTIONDNA codes for RNA copy! • DNA is used to produce: • mRNA (messenger RNA) • tRNA (transfer RNA) • rRNA (ribosomal RNA)
Phase 1: Initiation • RNA polymerase binds to a region of the DNA (upstream) adjacent to the start of a gene known as the promoter region (recognition site). • Promoter region consists of adenine and thymine bases – TATA Box. • DNA is unwound separating the template strand and the coding strand.
Phase 2: Elongation • Using the template strand, RNA polymerase builds the complementary mRNA molecule in the 5’ – 3’ direction. • Each nucleotide is added by removing 2 phosphate groups from the nucleoside triphosphate and forming a phosphodiester linkage. (similar to DNA replication) • The coding strand is not used for this process and is identical to the mRNA except it contains uracil.
Phase 3: Termination • RNA polymerase recognizes the terminator sequence at the end of the gene. • The sequence differs between prokaryotes and eukaryotes. • Transcription ceases, mRNA dissociates from the DNA Template and RNA polymerase is free to transcribe another gene.
RNA Processing • Prior to leaving the nucleus of eukaryotic cells, RNA known as the primary transcript goes through a series of modifications. • Primary RNA must be processed before leaving the nucleus in order to be protected. • This is done through capping and tailing. • Spliceosomes also cut out introns and remaining exons are joined together to form the final mRNA.
Posttranscriptional Modifications 1. Capping • 5’ cap consisting of 7-methyl guanosine units is added. • Protects the mRNA from digestion from nucleases and phophatases. • Involved with the initiation of translation
2. Tailing • A poly-A tail is added to the 3’ end. • Consists of approximately 200 - 300 adenine ribonucleotides added by poly-A polymerase. • Protection from degradation, facilitates attachment to ribosomal complex, assists in export of nucleus) .
3. Removal of Non-Coding Regions • Exons – Coding regions are interrupted by… • Introns – Non-coding • Spliceosomes cut out the introns and rejoin the exons. RNA splicing • small nuclear ribonucleoproteins (SnRNPs) play a key role in RNA splicing
Why have introns? • ·Intron DNA sequences may control gene activity • ·The splicing process may help regulate the export of mRNA • ·Introns may allow a single genet to direct the synthesis of different proteins (i.e if the same RNA transcript is processed differently)
mRNA Transcript • After the primary transcript has been capped, tailed and spliced, it is now known as mRNA transcript.
Stage 2: Translation: mRNA ---> Polypeptide Protein Synthesis - Learning Activity
Phases of Translation • Initiation • Elongation • Termination
mRNA • Processed transcript with 5’cap, poly-A tail and introns (non-coding regions) removed.
tRNA • Each tRNA is specific for amino acids, therefore there are 64 types of tRNA since there are 64 possible codons. • It is proposed that tRNA can recognize more than one codon by unusual pairing. This is known as the wobble hypothesis. • tRNA with attached amino acid = aminoacyl-tRNA (charged)
Ribosomes • ·are made up of two subunits (60% rRNA and 40% protein) that hold the mRNA in place in order for translation to occur. • ·Each ribosome has three biding sites: • ·P site = holds tRNA carrying growing peptide • ·A site = holds tRNA carrying next amino acid • ·E site = where tRNA exits from
1.Translation = synthesis of a polypeptide, which occurs under the direction of mRNA • ·Linear sequence of bases in mRNA is translated into the linear sequence of amino acids • ·Translation occurs at protein-synthesizing machinery, which consists of ribosomes, ribosomal RNA (rRNA), and proteins that facilitate the addition of amino acids to form polypeptide
Phase 1 - Initiation • mRNA is sandwiched between the two ribosome subunits. • Ribosome reads downstream (5’ 3’) until it reaches the start codon-AUG • The corresponding tRNA carrying methionine binds to the P (peptide) site.
Phase 2 - Elongation • The next tRNA carrying the required amino acid enters the A site. • The amino acids are joined by peptide bonds. • tRNAs are released through the passive site and are recycled.
Phase 3 - Termination • Ribosome reaches a stop codon (UGA, UAG or UAA) • Release factor proteins release the polypeptide chain. • Ribosome spits into its subunits. • Ribosome and mRNA are recycled. • Polypeptide undergoes modification.
http://carbon.cudenver.edu/~bstith/transla.MOV Protein Synthesis






















