Download

1 / 103
1.15k likes | 2.26k Views
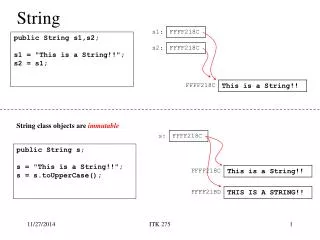
The STRING database. Michael Kuhn EMBL Heidelberg. protein interactions. example. Tryptophan synthase beta chain E. Coli K12. many sources. genomic context. curated knowledge. experimental evidence. T. literature. 373 genomes. (only completely sequenced genomes). 1.5 million genes.

E N D
The STRING database Michael Kuhn EMBL Heidelberg
example • Tryptophan synthase beta chain • E. Coli K12
373 genomes • (only completely sequenced genomes)
1.5 million genes • (not proteins)
Cell Cellulosomes Cellulose
gene fusion • score: sequence similarity
gene neighborhood • score: sum of intergenic distances
SVD • singular value decomposition • (removes redundancy)
not comparable • sequence similarity • sum of intergenic distances • Euclidean distance
benchmarking • calibrate against “gold standard” • (KEGG)
probabilistic scores • e.g. “70% chance for an assocation”
KEGG • Kyoto Encyclopedia of Genes
GO • Gene Ontology