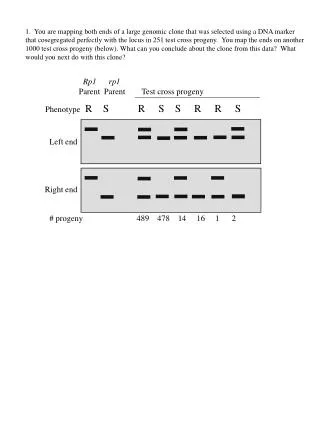
Download

1 / 18
180 likes | 292 Views
De Novo S hort R ead A ssembly. Li, Zhe 2011-06-20. Shotgun sequencing and assembly. Original DNA is broken into a collection of segments. The ends of each sequence are sequenced. The sequence reads are assembled together based on sequence similarity.

E N D
De Novo Short Read Assembly Li, Zhe 2011-06-20
Shotgun sequencing and assembly • Original DNA is broken into a collection of segments • The ends of each sequence are sequenced • The sequence reads are assembled together based on sequence similarity • Scaffolding through read pairing info • Two major issues • Algorithm for assembly • Statistics of coverage
Solve the puzzle Overlap Layout A bit more complicated consensus
Traditional approach (before NGS) • Overlap-layout-consensus method for assembly • Build an overlap graph where each node represents a read. An edge exists between two reads if they overlap. • The assembly problem thus becomes the problem of identifying a path through the graph that contains all the nodes - a Hamiltonian path.
But for NGS… • The sheer number of reads cannot build overlap graph • Short overlap ambiguous connections caused by repeats • High error rate • Sequencing process • Polymorphism Need new assembly algorithm.
New ideas (Pevzner 2001) • Don not overlap at all • Break puzzles to smaller pieces of regular shape • Convert Layout Problem to Eulerian Path Problem k-words (k-tuples) de Brujin Graph
de Bruijn graph • k = 4 Chinese Postman Problem Eulerian Path Problem High redundancy is handled by the graph without affecting the number of nodes. Making consensus the first step.
Eulerian path Euler 1736, Seven Bridges of Konigsberg problem: visit every bridge (edge) exactly once Easy-to-solve in comparison with Hamiltonian Path Problem
Velvet (Zerbino 2010) • Open source software developed by EBI • Implemented de Bruijn graph to assemble short reads • Construction • Simpilfy • Error removal • Resolution of repeats
Construction and simplification merged into single block
Error removal Considering topological features • Tips – errors at the edges of reads • length: shorter than 2k • “minority count” • Bulges – interal read errors, nearby tips connecting, erroneous connections • Tour Bas algorithm • Erroneous connections • Remove node basic coverage cutoff (set by user)
Resolution of repeats Breadcrumb algorithm • Assume the insert length distribution has a small variance • “long nodes” with length longer than practically all inserts • Using the read pairs • Discard connection with very few (<5) read pairs
Pebble and Rock Band (Zerbino 2009) Pebble exploits the knowledge of insert lengths to resolve more complex situations
Pebble and Rock Band (Zerbino 2009) Rock Band exploits sparse long read datasets within a short-read assembly to resolve repeats and extend contigs.
Choice of k • The result is very sensitive to k • Must be an odd number, <= MAXKMERHASH, inferior to read length • Test several alternatives in parallel and pick the best • k-mer coverage (Ck): expected number of times a unique k-mer is oberserved in a set of reads of length l with traditional coverage C Ck= C * (L - k + 1) / L Ck should be between 10 and 15
Practice Import data > ./velveth output_directory hash_length [[-file_format][-read_type] filename] File fromats: fasta (default), fastq, fasta.gz, fastq.gz, eland, gerald Read types: short (default), shortPaired, short2 (same as short, but for a separate insert-size library), shorPaired2 (dito), long (for Sanger, 454 or even reference sequences), longPaired
Practice Assemble – Single reads > ./velvetg output_directory/ Assemble – Pair-end reads Tow parameters: Expected (average) insertion length The expected short-read k-mercoverage > ./velvetg output_directory/ -ins_length 400 -exp_cov 21.3 (... other parameters ...) If you have reasons to believe that the coverage is reasonablyuniform over your sample, you can request that Velvet estimate it for you: > ./velvetg output_directory/ -exp_cov auto (... other parameters ...) This will set exp_cov to the length weighted median contig coverage, andcov_cutoff to half that value (unless you override it with a manual setting)