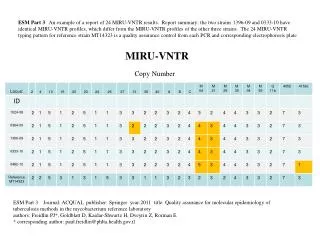
Detecting copy number variations using paired-end sequence data
200 likes | 366 Views
Detecting copy number variations using paired-end sequence data. CS224 May 29, 2009. Nick Furlotte. SNPs are old news. SNPs have been the main way of quantifying genetic variation Attention is now switching to other harder to detect variations

Detecting copy number variations using paired-end sequence data
E N D
Presentation Transcript
Detecting copy number variations using paired-end sequence data CS224 May 29, 2009 Nick Furlotte
SNPs are old news • SNPs have been the main way of quantifying genetic variation • Attention is now switching to other harder to detect variations • Structural variations possibly account for a large portion of genetic variance • Structural variations include • Insertions • Deletions • Inversions • Translocations • Copy number variations (CNVs)
What does a CNV look like? Copy Number Variation: Reference Donor
How do we find CNVs? • De novo sequence assembly is hard • Resequencing is now an option with low-cost next gen sequencing • This project aims to find CNVs using next gen sequencing reads.
Paired-end sequencing Illumina website
Paired-end sequencing Output: • Read lengths are a known size • Insert length has a distribution
The Computational Problem • Given: A set of paired-end reads The mapping positions in the reference Read and Mapping Quality • Output: A set of CNVs An estimation of the boundaries of each CNV For each CNV an associated probability for the number of copies
Proposed Method Use discordant read pairs as CNV signal Cluster discordant read pairs that explain the same CNV Estimate CNV boundaries based on clustered reads For each cluster calculate the probability of the number of copies = 1,2,3…
Discordant read pair Donor Reference Concordant
Discordant read pair Donor Reference Discordant
Clustering Discordant Read Pairs • Use a greedy approach • Pick any discordant read • Compare with all other discordant reads and group any that are within a given distance • Do this until no reads can be clustered together • This sounds problematic but with the right assumptions it works • Assume to know the maximum insert length • Assume that the reverse read maps into the second copy and the forward read maps into the first copy • Assume that CNVs are far apart
Read Pair Cluster Distance R+MI xmin N N = Xmin + R + MI
if otherwise Read Pair Cluster Distance R N xmax N = Xmin+ R+ MI N = Xmax + R Xmax - Xmin = MI
Estimating Boundaries • Have a set of clusters now • Simple Boundary estimation: Right bounary = Left bounary =
Estimating the number of copies • Utilize coverage - • Position Coverage ~ Poisson(coverage) • For each cluster: • Perform a goodness of fit test for each coverage level • (ie. Number of copies = 2 => coverage’ = 2*coverage) • The coverage level that gives the best fit is the most • likely Sadly this did not work :( So I resorted to estimating by looking at the ratio of the mean Coverage to the expected.
Simulation • Wrote simulator tool in C • Simulates FASTQ paired-end reads • Reads and writes MAQ files • Computes Coverage • Generated 10MB random genome using mouse chr 19 • Inserted 5 CNVs spread across the genome • Generated reads at 40x Coverage • Mapped to fake reference using MAQ • Applied the previously mentioned method
Results • Found all of the CNVs • No False Positives • Worked exactly as predicted, because reads were perfect.
Results • Applied method to real mouse sequence data • 40x coverage on chromosome 17 for CAST mouse strain • Found 1456 possible CNVs • Most of them were crazy looking • Zeroed in on 5 that look interesting Obviously the method needs some work
Future Work • Table from Lee, et al. shows that the number of perfectly mapped reads that are discordant is very small • Their method considers all possible mapping positions for each pair • My method needs to consider this and toss MAQ
Future Work • Replace the ad-hociness with a more formal probabilistic framework • Consider all high-quality mapping positions (take into account low quality mappings) • Consider the problem of repeated sequences