LR Parsing Table Costruction
480 likes | 1.02k Views
LR Parsing Table Costruction. Lecture 6 Syntax Analysis. LR parsing example. Grammar: E -> E + T E -> T T -> T * F T -> F F -> ( E ) F -> id. LR parsing example. CONFIGURATIONS STACK INPUT ACTION 0 id * id + id $ shift 5.

LR Parsing Table Costruction
E N D
Presentation Transcript
LR Parsing Table Costruction Lecture 6 Syntax Analysis
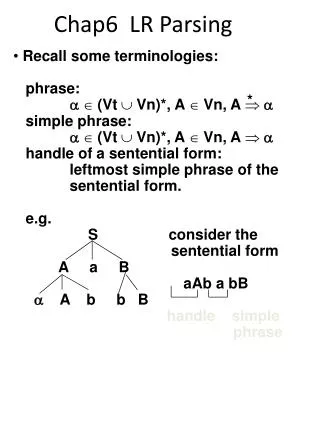
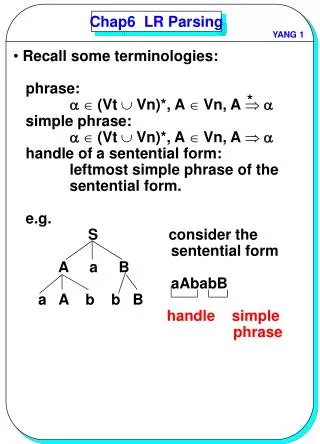
LR parsing example • Grammar: • E -> E + T • E -> T • T -> T * F • T -> F • F -> ( E ) • F -> id
LR parsing example • CONFIGURATIONS • STACK INPUT ACTION • 0 id * id + id $ shift 5
LR grammars • If it is possible to construct an LR parse table for G, wesay “G is an LR grammar”. • LR parsers DO NOT need to parse the entire stack todecide what to do (other shift-reduce parsers might). • Instead, the STATE symbol summarizes all the informationneeded to make the decision of what to do next. • The GOTO function corresponds to a DFA that knows howto find the HANDLE by reading the top of the stackdownwards. • In the example, we only looked at 1 input symbol at atime. This means the grammar is LR(1).
How to construct an LR parse table? • We will look at 3 methods: • Simple LR (SLR): simple but not very powerful • Canonical LR: very powerful but too many states • LALR: almost as powerful with many fewer states • yacc uses the LALR algorithm.
SLR parse tables • The SLR parse table is easy to construct, but the resulting parser isa little weak. • The table is based on LR(0) ITEMS, or just plain ITEMS. • A LR(0) item is a production G with a dot at some position on theRHS. • The production A -> XYZ could generate the following LR(0) items: • A -> .XYZ • A -> X.YZ • A -> XY.Z • A -> XYZ. • The production A -> ε only generates 1 LR(0) item: • A -> .
LR(0) items • An item indicates how far we are in parsing the RHS. • A -> .XYZ means we think we’re at the beginning of anA production, but haven’t seen an X yet. • A -> X.YZ means we think we’re in the middle of an Aproduction, have seen an X, and should see a Y soon.
Augmenting the grammar G • Before we can produce an SLR parse table, we have toAUGMENT the input grammar, G. • Given G, we produce G’, the AUGMENTED GRAMMARfor G: • Add a new symbol S’ • Add a new production S’ -> S (where S is the old start symbol) • Make S’ the new start symbol
Item set closure • We need a new concept: the CLOSURE of a set ofLR(0) items. • If I is a set of items for grammar G’, then the CLOSUREof I is defined recursively: • Initially, every item in I is added to closure(I) • If A -> α . B β is in closure(I) and B -> γ is a production, then add the item B -> . γ to I, if not already there.
Itemset closure example • E’ -> E Closure(I) = { E’ -> . E • E -> E + T | T E -> . E + T • T -> T * F | F E -> . T • F -> ( E ) | id T -> . T * F • T -> . F • Initial itemset I is { E’ -> .E } F -> . ( E ) • F -> . id }
The goto table • We also need the function goto(I,X) that takes anitemset I and a grammar symbol X, and returns theclosure of the set of all items [ A -> α X . β ] suchthat [ A -> α . X β ] is in I. • Example: I = { [E’ -> E.], [E -> E. + T] } goto(I,+) =
Fig. 4.36. Transition diagram of DFA D form viable prefixes.
Canonical LR(0) itemsets • The CANONICAL LR(0) ITEMSETS can be used to createthe states in the SLR parse table. • We begin with an initial set C = {closure({ [S’->.S] })}. • Then, foreach I in C and each grammar symbol X suchthat goto(I,X) is not empty and not in C already, do • Add goto(I,X) to C • Example: canonical LR(0) itemsets for the same grammar. • Each set in C corresponds to a state in a DFA.
How to build the SLR parse table • Take the augmented grammar G’ • Construct the canonical LR(0) itemsets C for G’ • Associate a state with each itemset Ii in C • Construct the parse table as follows: • If A -> α . a β is in Ii and goto(Ii,a) = Ij, then set action[i,a]to “shift j” (“a” here is a terminal) • If A -> α . is in Ii then set action[i,a] to “reduce A -> α” forall a in FOLLOW(A) • If S’ -> S . is in Ii then set action[i,$] to “accept” • If any of the actions in the table conflict, then G is NOT SLR.
Example SLR table construction • For the first LR(0) itemset in our favorite grammar: • I0: E’ -> .E • E -> .E + T • E -> .T • T -> .T * F • T -> .F • F -> .(E) This gives us action[0,(] = shift 4 • F -> .id This gives us action[0,id] = shift 5
What to do with ambiguity? • Sometimes it is convenient to leave ambiguity in G • For instance, G1: is simpler than G2: • E -> E + E E -> E + T | T • | E * E E -> T * F | F • | ( E ) F -> ( E ) | id • | id • But SLR(1), LR(1), and LALR(1) parsers will all have a • shift/reduce conflict for G1.
What to do with ambiguity? • Sometimes it is convenient to leave ambiguity in G • For instance, G1: is simpler than G2: • E -> E + E E -> E + T | T • | E * E E -> T * F | F • | ( E ) F -> ( E ) | id • | id • But SLR(1), LR(1), and LALR(1) parsers will all have a • shift/reduce conflict for G1.
Ambiguity leads to conflicts • G1 is ambiguous, so we are guaranteed to get conflicts. • For example, in I7: • We will add rules to “shift 4” on ‘+’ and “shift 5” on ‘*’. • For the item E -> E+E. we will add the rule “reduce E->E+E” to the parse table for each terminal in FOLLOW(E). • But! FOLLOW(E) contains + and * -- shift/reduce conflict. • LR(1) and LALR(1) tables will have the same problems.
Resolving the conflicts • Knowing about operator precedence and associativity, we can resolve the conflicts. • Example: for input “id + id * id”, we will be in state 7 after processing “id + id” • STACK INPUT • 0 E 1 + 4 E 7 * id $since * has higher precedence than +, we should really shift, not reduce. • With a + next in the input, we should reduce, to enforce left-associativity. • See Fig. 4.47 in text for a complete SLR(1) table.
If-else ambiguity • The ambiguity of the “dangling else” creates a shift-reduce conflict in parsers for most languages. • Since the else is normally associated with the nearest if, we resolve the conflict by shifting, instead of reducing, when we see “else” in the input. • See the LR(0) states and parse table on page 251. • This method is much simpler than writing an unambiguous grammar.
Non-SLR grammars • Consider the assignment grammar • S’ -> S generating, e.g. S =*> id = * id • S -> L = R • S -> R • L -> * R • L -> id • R -> L
Non-SLR grammars • Construct the initial canonical LR(0) itemset I0. • Compute I2 = goto(I0,L) and I6 = goto(I2,=). • Compute FOLLOW(L) • Compute parse table entries for I2: shift/reduce conflict! • This means in state I2, with ‘=’ in the input, we do notknow whether to shift and go to state I6 or reducewith R -> L, since ‘=’ is in FOLLOW(L). • To correct this, we need to know more about the contextof the L we just parsed. • “Canonical LR(1)” and “LALR(1)” are powerful enough.
More states means more memory • In SLR, we said in state i we should reduce by A -> α ifthe itemset contains the item [A -> α .] and a is inFOLLOW(A). • However, sometimes when state i is on top of the stack,and a is next in the input, what comes BEFORE α onthe stack might invalidate the reduction A -> α. • Example from previous grammar: sentential form “R = …” is impossible, but “* R =” is possible. • So actually, we really want to reduce by L -> * R whenwe see R on stack and “=” in the input.
LR(1) idea • Our parser needs to keep track of more state information.How can it? • Idea: use canonical LR(0) states, but split states asneeded by adding a terminal symbol to each item. • LR(1) ITEMS take the form [A-> α.β,a], where A-> αβ is a production in G and a is a terminal symbol or $. • The “1” refers to the length of a, the LOOKAHEAD foreach item. If length = k, we would have an LR(k) item. • In parsing, we will now only reduce αβ. to A if an item’slookahead symbol agrees with the next input.
LR(1) parse table construction • We need to redefine closure(I) for a set of LR(1) items: • for each • item [A-> α.B β,a] in I • production B -> γ in G’ • terminal b in FIRST(β a) • such that [B->. γ,b] is not already in I, do: • add [B->. γ,b] to I • repeat until no more items can be added to I • goto(I,X) is the same as for SLR(1).
Example LR(1) parser construction • Begin with augmented grammar G’: • S’ -> S • S -> C C [ what is L(G’)?? ] • C -> c C | d • The first itemset I0 = closure({S’->.S,$}) = { • S’ -> .S,$ • S -> .CC,$ [ from S’->.S,$ and S->CC, B=S, α=ε, β= ε ] • C -> .cC,c/d [ from S’->.CC,$ and C->cC, B=C, α= ε, β=C ] • C -> .d,c/d [ from S’->.CC,$ and C->d, B=C, α= ε, β=C ] • }
LR(1) parsers: the good news • LR(1) is quite similar to SLR(1), with one main difference: • We only add reduce rules to the parse table when the input matches the LOOKAHEAD for the item • SLR(1) adds reduce rules for any terminal in the FOLLOW set. • This means LR(1) will have fewer shift/reduce and reduce/reduce conflicts, because it tries to reduce in fewer situations.
LR(1) parsers: the bad news • LR(1) parsers are powerful, able to parse almost any unambiguous CFG used for real programming languages. • But there is a price: the number of states is huge. • For the very simple c*dc*d language with 4 productions, we already needed 10 LR(1) states. • For a typical PL like Pascal, the LR(1) table would contain a few THOUSAND states! • Is there a technique as powerful with fewer states?
LALR parse tables • LALR makes smaller parse tables than canonical LR, but still covers most common programming language constructs. • LALR has the same number of states as the SLR parser for the same grammar, but is more picky about when to reduce, so fewer conflicts come up. • yacc actually constructs a LALR(1) table, not a canonical LR(1) table.
LALR idea • Usually, in a LR parser, there will be many states that are identical, except for the lookahead symbol. • LALR takes these identical states and MERGES them, forming the UNION of the lookahead symbols for the merged items. • Algorithm: build the LR(1) itemsets, then merge itemsets with the same CORES.
LALR example Which LR(1) itemsets can be merged? • I0: S’ -> .S,$ I3: C -> c.C,c/d • S -> .CC,$ C -> .cC,c/d • C -> .cC,c/d C -> .d,c/d • C -> .d,c/d • I5: S -> CC.,$ • I1: S’ -> S.,$ • I6: C -> c.C,$ • I2: S -> C.C,$ C -> .cC,$ • C -> .cC,$ C -> .d,$ • C -> .d,$ • I7: C -> d.,$ • I4: C -> d.,c/d • I8: C -> cC.,c/d • I9: C -> cC.,$
Efficient Construction of LALR Parsing Tables • Example 4.46. Let us again consider the augmented grammar • S' S • S L = R | R • A * R | id • B L • The kernels of the sets of LR(0) items for this grammar are shown in Fig. 4.42. Fig. 4.42. Kernels of the sets of LR(0) items for grammar (4.20).
Efficient Construction of LALR Parsing Tables • Example 4.47. Let us construct the kernels of the LALR(1) items for the grammar in the previous example. The kernels of the LR(0) items were shown in Fig. 4.42. When we apply Algorithm 4.12 to the kernel of set of items I0, we compute closure ({[S'·S, #]}), which is • S'·S, # • S ·L = R, # • S ·R, # • L · * R, #/= • L ·id, #/= • R ·L, #
Next time • - Yacc 사용법은 조교가 설명 • - Semantic 처리 (Yacc에서 배운 것 구현 방법)