Protein-protein interactions
Protein-protein interactions. Marcotte EM, Pellegrini M, Ng HL, Rice DW, Yeates TO, Eisenberg D. (1999). Detecting protein function and protein-protein interactions from genome sequences. Science 285, 751-3


Protein-protein interactions
E N D
Presentation Transcript
Protein-protein interactions • Marcotte EM, Pellegrini M, Ng HL, Rice DW, Yeates TO, Eisenberg D. (1999). Detecting protein function and protein-protein interactions from genome sequences. Science 285, 751-3 • Enright AJ, Iliopoulos I, Kyrpides NC, Ouzounis CA. (1999). Protein interaction maps for complete genomes based on gene fusion events. Nature 402, 86-90 • compare briefly with yeast-2-hybrid system (y2h)
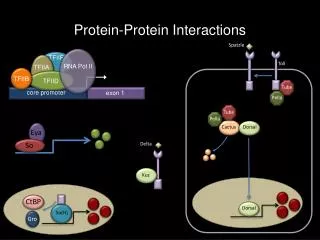
Rosetta stone sequences • protein A is homologous to subsequence from protein C • protein B is homologous to subsequence from protein C • subsequences from A and B are NOT homologous to each other
Rationale • Proteins A and B form a multisubunit complex which is fused into a single protein in sequence C • thermodynamics- pieces don’t need to find each other in cell • efficiency- cell needs to produce much less of each as a result • metabolic channeling- mentioned in Nature paper’s last paragraph • - enzymes in related biochemical pathway may form functional complexes • substrates could then pass from one enzyme to another directly, instead of diffusing into the cytosol at large • not clear if there is direct evidence showing metabolic channeling anywhere- (tryptophan synthase?)
Marcotte, et al (July 1999) • Method 1: use domain subsequences defined by Pro-Dom • all pairs of subsequence matches considered and searched for • two proteins which have one from each pair matched against • Method 2: sequence comparison • two non-overlapping local sequence alignments to a third protein • both use a minimal threshold for id’ing statistical significant scores
Marcotte, et al (July 1999) (2) • Trying to test accuracy of independent predictions… • Method 1: shared keywords in SWISS-PROT annotations • - golly gee… it’s better than random… • - 68% vs 15% in E. coli • - 32% vs 15% in S. cerevisiae (yeast) • Method 2: Database of interacting Proteins • 6.4% of applicable sequences are also in the database • Rosetta Stone is not comprehensive (more on this later) • Method 3: phylogenetic profiles (see last week’s papers) • wow it’s better than random too… • 5%, eight times as many as random
Enright, et al (NOV 1999) • use BLASTP to compare query genome against itself • formation of a binary matrix (1’s or 0’s in each entry) • - symmetrification with Smith-Waterman (local alignments • BLASTP to compare query vs reference genome • get a second binary matrix • all pairs of query proteins similar to a reference protein • Z-score to test for significance of alignments • - set an arbitrary Z-score cutoff to determine coverage/accuracy
And now for something completely different… • y2h => yeast-2-hybrid detection of protein-protein interactions • - Fields, S. and Song, O. Nature 1989, if you’re curious. • transcription factors composed of two separable domains • - DNA-binding and transcriptional-complex recruitment
High throughput y2h… • is only high-throughput if you are not a postdoc. • lots of transformations and assays • fortunately you only have to transform once. • has major problems with false negatives • integral membrane proteins don’t work (don’t fold properly) • post-translational modifications • require nuclear localization • misfolding or steric hindrances • transcription factors (?) • also has significant false positives also- not sure why… • - Uetz et al (2000) had 20% of interactions screen twice… • other validation methods • genetic techniques • biochemical (coIP, affinity chromatography, mass spec, etc)
A brief discussion on signal transduction • kinase cascades are ubiquitous in signaling pathways • MKKK => MKK => MAPK • kinase cascades are ubiquitous in signaling pathways • interesting when looking at given Rosetta Stone examples • will kinase cascades be detected? • SH2 and SH3 domains (Marcotte, et al) • SH2 bind phosphorylated tyrosine residues, SH3 bind proline-rich sequences • both are common motifs but have sequence-specific affinity • Kinase cascades/signaling pathways are sometimes Y2H targets