Download

1 / 31
340 likes | 861 Views
Protein-protein interactions. Ia. A combined algorithm for genome-wide prediction of protein function. Edward M. Marcotte, Matteo Pellegrini, Michael J. Thompson, Todd O. Yeates, David Eisenberg( 1999) Nature 402,83-86. Protein function in the post-genomic era.

E N D
Protein-protein interactions Ia. A combined algorithm for genome-wide prediction of protein function. Edward M. Marcotte, Matteo Pellegrini, Michael J. Thompson, Todd O. Yeates, David Eisenberg(1999) Nature 402,83-86. • Protein function in the post-genomic era. David Eisenberg, Edward M. Marcotte, Ioannis Xenarios & Todd O. Yeates(2000) Nature 405, 823-826
FUNCTIONAL RELATIONSHIPS AMONG PROTEINS: • GENOME-WIDE PREDICTION (FUNCTIONAL GENOMICS) • Does not rely on DIRECT SEQUENCE HOMOLOGY • 3 independent predictions methods & available experimental data.
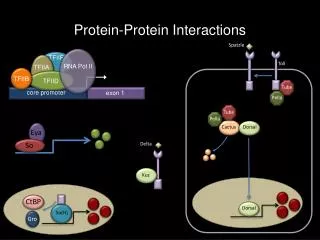
STRATEGIES USED TO “FUNCTIONALLY LINK” PROTEINS: 6217 yeast proteins • Correlated Evolution: Related Phylogenetic Profiles (pattern of presence or absence of a particular protein across a set of organisms whose genomes have been sequenced): proteins, which operate together in a common pathway or complex, are inherited together. • Correlated mRNA Expression Patterns: Correlated mRNA Expression Patterns under different growth conditions • Correlated Patterns Of Domain Fusion: Link 2 proteins whose homologs are fused into a single gene (Rosetta stone sequences) in another organism.
STRATEGIES USED TO “FUNCTIONALLY LINK” PROTEINS:(continued) • Gene Neighbour Method: if in several genomes, the genes that encode 2 proteins are neighbors on the chromosome, the proteins tend to be functionally linked • Experimental Evidence: Mass spectrometry, Coimmunoprecipitaion, Yeast 2-hybrid data (DIP, MIPS yeast genome db) • Metabolic pathway neighbours: Proteins, which participate in same metabolic pathway, common structural complex or biological process or closely related physiological function: BLAST homology searches and pairwise links were defined between yeast proteins whose E.Coli homologs catalyse sequential reactions in a metabolic pathway (EcoCyc db)
RESULTS: • Phylogenetic profiles: 20,749 links • mRNA expression patterns: 26,013 links • Domain fusion method: 45,502 links • 93,750 pairwise functional links among 76% (4,701) of yeast proteins • 4130: “HIGHEST CONFIDENCE” links (experimental proof, valid by 2 of 3 prediction methods) • 19,251: “HIGH CONFIDENCE”links: (predicted by phylogenetic profiles) • Remainder predicted by domain fusion or correlated mRNA expression patterns
VALIDATION: • Excellent reliability if 2 or more prediction methods agreed on a link. • These methods link many proteins that are already known to function together on the basis of experiments. (Ribosomal proteins, proteins from flagellar motor apparatus and metabolic pathways) • “Keyword recovery”: Prediction could be compared to the actual annotation: compare keyword annotation on SwissPDB, for both members of each pair of proteins, linked by one of the methods-possible when the members have known function. “Keyword recovery”: if keywords match. Average signal to noise ratio for “Keyword recovery”: • Phylogenetic profiles: 5 • mRNA expression patterns: 2 • When 2 prediction methods gave same linkage: 8 • Direct experimental data: 8
OUTCOME: • Functional links between proteins of unknown function: • General function assigned to more than half of 2557 previously uncharacterized yeast proteins: 15% from high and highest confidence links, 62% using all links. • Functional Links Between Non-Homologous Proteins: beyond traditional “sequence matching”: Sup35, MSH6 • Discovery of potential interactions within and across cellular processes and compartments. • Connections represent a “gold mine” for experimentally testing specific hypotheses about gene function. • Viewing protein-protein interactions globally as a network and not as binary data sets, increases the confidence levels for individual interactions: inspection of interaction web at different steps identifies “unexpected” links between previously unconnected cellular processes.
Ib. A network of protein-protein interactions in yeast. Schwikowski B, Uetz P, Fields S. (2000). Nat Biotechnol. 18, 1257-61
DATA SOURCE: • MIPS site • YPD • DIPS Yeast-2-hybrid studies Biochemical experimental data
Prediction of function: • Annotated functions of all neighbors of P are ordered in a list, from the most frequent to the least frequent. • Functions that occur the same number of times are ordered arbitrarily. • Everything after the third entry in the list is discarded, and the remaining three or fewer functions are declared as predictions for the function of P. • Evaluation of the quality of the links: For unknown protein, test predicted function
RESULTS: • Analyzed 2,709 published interactions involving 2,039 yeast proteins • Single large network containing 2,358 links among 1,548 individual proteins.Other networks had few proteins. • 65% of the interactions in the complete set of networks occur among proteins with at least one common functional assignment. • 78% of the 1,432 interactions between proteins of known localization, the proteins share one or more compartments. • Correctly predicted a functional category for 72% of 1393 characterised proteins, with at least one partner of known function. • Cross-talk between and within functional groups/subcellular compartments. • Local function vs Contextual/cellular function (extended web of interacting molecules) • Predicted functions of 364 uncharacterised proteins.
Reliability of the generated networks: • 1,393 of the 2,039 proteins were annotated with some function and had at least one neighbor annotated with a function. • In 1,005 of these 1,393 cases (72.1%), at least one annotated function was predicted correctly by the above method. • Performed the same prediction algorithm 100 times on the basis of randomly generated interactions. • Only 12.2% of the predictions yielded a prediction that agreed with the known annotation.
PROBLEMS… • Interactions of membrane proteins underrepresented: Y2H data • Y2H data: lots of false positives. • Only 15% agreement between this interaction data and Marcotte’s “high quality” prediction data. • Uncertainities remain that WILL require additional experimentation.
CHALLENGES: • Protein complexes are not static: change with metabolic state of cell, external stimuli etc. • Protein chip technology: used to study transient interactions: amenable to variety of assays like nucleotide-binding, enzymatic activity etc.
II. Mapping protein family interactions: intramolecular and intermolecular protein family interaction repertoires in the PDB and yeast. Park J, Lappe M, Teichmann SA. (2001). J Mol Biol. 307, 929-38.
Protein DOMAIN interactions: interactions between whole structural families of evolutionarily related domains as opposed to interactions between individual proteins. • Types of domain interactions: • 1) Domain-domain(intra-chain) interactions in multi-domain polypeptide chains • 2) Inter-chain protein interactions in multi-subunit protein complexes. 3) In transient complexes between proteins, which can also exist independently
METHODS: • Protein superfamilies from SCOP db • Interactions between families in the PDB: (domains of known 3D structure) coordinates of each domain were parsed to check whether there are 5 or more contacts with 5A to another domain • Interactions between families in the yeast genome: by homology: -Protein structures assigned to the yeast proteins using the domains from SCOP as queries in PSI-BLAST. -Yeast sequences also compared to the PDB-ISL with FASTA • Assumption: Within polypeptide chains, structural domains interact if there are less than 30 amino acids separating them. • If one family F has 2 domains, a and b, and each of these interacts with a domain from a different family, then the number of interaction families for F will be 2.
RESULTS: • 1st attempt at classifying interactions between all the known structural protein domains according to their families. • Could classify 8151 interactions between individual domains in the PDB and the yeast in terms of 664 types of interactions between pairs of protein families. • Scale free network: Most protein families only interact with 1 or 2 other families. A few families are extremely versatile in their interactions and are connected to many families (Hubs in the graph)-functional reasons. Eg: -Immunoglobulins, P-loop nucleotide triphosphate hydrolases • In 45% of all families in the PDB, domains interact with other domains from the same family: internal duplication and domain oligomerisation is favourable. • Pairs of families that interact both within and between polypeptide chains belong mostly to 2 types of domains: enzyme domains and domains from the same family.
PROBLEMS: • Multi-domain proteins: cannot resolve exactly which domains are interacting: not used • Members of 2 families can sometimes interact in different ways, using different types of interface (different modes of oligomerisation of nucleoside diphosphate kinases) • Does not take account of symmetric homooligomers, of which only one monomer is in the PDB entry and hence the number of homomultimeric family interactions may be underestimated.
FUTURE: • 51 new interactions between superfamilies: potential targets for structure elucidation and experimental investigation of these interacting polypeptides that do not have analogs in the PDB. • For interactions in which one partner does not have a structural assignment, possible structures can be picked up from the set of known family interactions • Database of domain-domain interfaces