Download

1 / 39
390 likes | 578 Views
Struktura rezerv neživotního pojištění Helga Krafferová U NIQA pojišťovna, a.s. 16.11.2007. Téma. Odhad chyby v odhadech IBNR metodou CL Měření opatrnosti v odhadech IBNR Testování předpokladů metody CL Iterační odhad parametrů v metodě BF Výpočtové programy. Značení.

E N D
Struktura rezerv neživotního pojištění Helga Krafferová UNIQA pojišťovna, a.s. 16.11.2007
Téma • Odhad chyby v odhadech IBNR metodou CL • Měření opatrnosti v odhadech IBNR • Testování předpokladů metody CL • Iterační odhad parametrů v metodě BF • Výpočtové programy
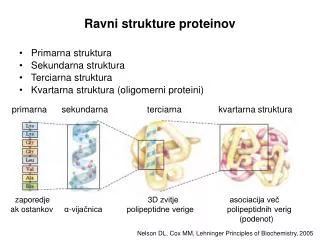
Značení Cik - kumulované škody nastalé v roce i tak jak jsou známy ve vývojovém roce k Qik - nekumulované škody Ri - rezerva roku i, Ri = CiI – Ci,I+1-i
Předpoklady • E(Ci,k+1| Ci,1, …, Ci,k)= fkCi,k, k = 1,…, I-1 • {Ci1, …, CiI}, {Cj1, …, CjI} pro nezávislé Odhady
Tvrzení D = {Ci,k|} E(Ci,I| D)=Ci,I+1-i fI+1-i . … . fI-1 Důkaz užitím 1) a 2) E(Ci,I| Ci,1,…, Ci,I+1-i)= E{E(Ci,I| Ci,1,…, Ci,I+1-i)| …} = E(Ci,I-1.fI-1| Ci,1,…, Ci,I+1-i) = = fI-1 E(Ci,I-1| Ci,1,…, Ci,I+1-i) = … má shodný tvar s E(Ci,I| D) , což je nejlepší odhad Ci,Izaložený na D
Tvrzení Odhady f jsou nestranné a nekorelované Nekorelovanost je překvapující vzhledem k závislosti na shodných datech.
Máme Tedy i je nestranný odhad E(Ci,I| D) a je nestranný odhad Ri
Střední kvadratická chyba (mean squared error) způsobená budoucí náhodou neuvažuje se nepodmíněná
obecně Zápis poukazuje na 2 složky – rozptyl n.v. CiI a chyba odhadu. Proto je třeba učinit předpoklad o rozptylu. jsou Cik– váženým průměrem individuálních vývojových faktorů Tedy uvažujeme proporcionální k Cik
Předpoklad 3) kde neznámý parametr Odhad je nestranným odhadem
odhad posledního parametru když jinak extrapolovat řadu jednoduše např. když
Tvrzení Za předpokladů 1), 2) a 3) lze odhadnout Pro existuje obdobná formule.
Nebyly učiněny předpoklady o rozděleníCiI, za předpokladu normálního rozdělení lze stanovit hodnoty pro tzv. 90/10 rezervu (resp. 75/25) Technická bezpečnostní přirážka
se skládá z rozptylu C a chyby odhadu neobsahuje chybu způsobenou chybným modelem nebo změnou chování v budoucnu Proto nutné testování předpokladů CL
E(Ci,k+1| Ci,1, …, Ci,k)= fkCi,k • Zde fk nezávisí na roku vzniku i • Může být konstanta tak, že E(Ci,k+1| Ci,1, …, Ci,k)= a + fkCi,k • Místo na Cik může být závislost na CiI 2){Ci1, …, CiI}, {Cj1, …, CjI} pro nezávislé • Narušení silným diagonálním efektem, např. rozpuštěny/navýšenyrezervy RBNS všech let • Inflace 3) • Nezávisí na roku vzniku i • Např. potom za je lepší vzít aritmetický průměr individuálních vývojových faktorů • Jestliže pak
1) Signifikantnost fk Pro testování vhodnější přírůstkový faktor • Testujeme rozdílnost od nuly. • Je-li možnost statistického programu - regresní analýzy s odhadem parametru získáme i odhad jeho směrodatné odchylky. • Lze formálně statisticky testovat normalitu rozložení vývojových faktorů. • Je-li faktor větší než dvojnásobek směrodatné odchylky, lze mít za to, že je signifikantně >0; stačí 1,65 násobek
2) Alternativní vzorce • S lineární konstantou závislou na vývojovém roce • S parametrem závislým na roku vzniku • S vlivem kalendářního roku Parametry odhadovány MNČ (někdy vyžaduje iter. postup) Pro testování vhodnosti modelu lze použít charakteristiku SSE (sum of sq. error) Třeba vzít v úvahu počet parametrů - není obecně přijímaná metoda jak
n počet pozorování p počet parametrů Akaike Information Criterion dovoluje přeparametrizaci Bayesian Information Criterion CL má 1 parametr pro 1 vývojový rok, což dává výhodu
a) Konstanta Často vhodné přidat pouze do prvního vývojového roku, kde může být významnější než vývojový faktor. Pro znormovaný trojúhelník expozicí (pojistko-roky), případně pojistným je často vhodnější metoda čistě konstanty než metoda čistě vývojového faktoru. Zde pro porovnání metod lze sledovat pouze významnost konstanty a faktorů, neboť CL pouze zvláštním případem.
b) Parametr závislý na roku vzniku V původní metodě Bornhuetter-Ferguson h(i) je odhad celkových škod na jiném základě než na datech z trojúhelníku. Modifikace BF – data trojúhelníku použita i pro odhad h(i). h(i) je pouze proporcionální k celkovým škodám roku i, tato proporcionalita opravena faktory Parametr pro každý rok vzniku i vývoje. Je-li m let,m + m – 1. Je-li h(i) přímo odhad , tak tedy 2m-2 parametrů. Nelze brát v úvahu statistickou významnost parametrů, ale
To, že Qi,k+1 nezávisí na Cik lze interpretovat tak, že Cik obsahují náhodnou složku, která neovlivní budoucí vývoj. Zatímco CL by aplikovaly vývojové faktory na tyto chyby a tím celkovou chybu zvyšovaly. Simulace škod
CL i BF nemá problém se změnou objemu z roku na rok, jestliže vývojový model zůstane stejný BF má nevýhodu velkého počtu parametrů, je dobré zkusit zredukovat, např. h(i) seskupit do skupin nebo zavést lineární trend h(i) = a + b.i
Speciální případ BF - Cape Cod h(i) ~ h oproti CL pouze tento parametr navíc, ale změníme-li h, lze tuto změnu vyrovnat změnou všech f, tedy stejný počet parametrů trojúhelník musí mít stabilní úroveň škodní kvóty i expozice v jednotlivých letech expozici a inflaci lze „opravit“
CC předpokládá, že roky, kde jsou dosud nízké nebo vysoké škody budou mít stejný budoucí vývoj Qik, takže dobrý a špatný rok se od sebe liší jen v některých vývojových letech a ve všech ostatních obdobích mají srovnatelný výskyt objemu škod CL a obecný BF naopak předpokládá, že špatný rok bude mít vyšší výskyt škod Qik ve valné většině období
3) Linearita modelu lineární aproximace křivky – rezidua kladná, záporná, kladná zda odchylky nevykazují podobný tvar
4) Stabilita vývojového faktoru uvažujeme individuální vývojové faktory
je-li patrný trend lze užít váženého průměru s vyšší váhou posledních let nebo vyrovnat pomocí klouzavých průměrů nestabilita trojúhelníku může být způsobena změnou ve vyřizování škod, např. mění-li se procento uzavřenosti škod v jednotlivých letech je-li pouze jednotlivá příčina (např. velká škoda, povodně, vichřice) lze vyloučit z dat
5) Nekorelované sloupce nekumulativního trojúhelníku mimo pozorování v rámci jednoho roku jsou Qik a Qjl nezávislé je-li vývojový rok s vysokou škodou zpravidla následován rokem s nízkou škodou, je třeba toto vzít v úvahu lze spočítat výběrový korelační koeficient r pro všechny dvojice sloupců v trojúhelníku individuálních faktorů
nyní zda je korelace významná (H0: r = 0) např. na 10% hladině pomocí veličiny mající t-rozdělení o n-2 stupních volnosti (Prof. Anděl Statistické metody) jestliže máme 1 korelaci na hladině 10% nemusí to ještě znamenat korelovaný trojúhelník
problém může znamenat více korelovaných sloupců, co znamená „více“? n počet všech dvojic sloupců v trojúhelníku počet signifikantních korelací ~ binomické rozdělení (n,10%) směrodatná odchylka pokud počet signifikantních korelací > je třeba uvažovat korelovaný trojúhelník opravit vývojové faktory pomocí vztahu
6) Ne zvlášť vysoké /nízkédiagonály zda počet vysokých/nízkých individuálních faktorů na diagonále není vysoký v trojúhelníku výplat se může na diagonále objevovat vlivinflace diagonální efekt může být multiplikativní, aditivní
Iterativní metoda odhadu parametrů BF je třeba minimalizovat třeba počáteční hodnota parametrů nebo h použijeme jakoukoli „rozumnou“ hodnotu, např. nebo začneme s těmito hodnotami a nalezneme MNČ hodnoty h
MNČ pro každé i jedna regrese, tím nalezeny nejlepší h(i) pro daná potom
takto se pokračuje dokud se neobjeví konvergence může nastat konvergence k lokálnímu minimu, proto je třeba vyzkoušet více počátečních hodnot cca 10 iterací pozor h(i) nejsou odhady přímo celkové škody roku i, ale odhadují ji společně s parametry
Výpočtové programy • MS Excel • 1 „profesionální“ od zajišťovny • 1 Axa Francie, 2 UNIQA Vídeň
Prameny Thomas Mack: Distribution-free Calculation of the Standard Error of Chain Ladder Reserve Estimates, 1993 Gary G. Venter: Testing the Assumption of Age-to-age Factors