Download
1 / 8
80 likes | 205 Views
This article provides a comprehensive overview of instruction execution in superscalar processors, focusing on CPU memory control and data pathways. It contrasts in-order and out-of-order execution models, detailing their respective dependencies and performance implications. The discussion includes pipelining concepts, branching history, and cache architecture, specifically referencing the Alpha 21164 and P6 microarchitecture. Readers will gain insights into how modern processors achieve high efficiency through optimized instruction handling and parallel processing techniques.

E N D
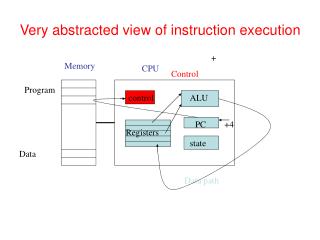
Very abstracted view of instruction execution + Memory CPU Control Program control ALU PC +4 Registers state Data Data path
Very abstracted view of instruction execution Sub $7,$8,$9 + 0x10093826 CPU Memory Control Program control ALU 000,,, 00110 001… 0001 PC +4 Registers state Data Data path (addi $4,$12,33) 0x21840021
Superscalar Processors • MIPS 3000 : scalar processor, i.e., one instruction at a time in pipeline • Newer processors expand the concept in: • Width: there are several pipelines from the EX stage on hence the name superscalar • Depth: Each pipeline has more stages • The pipeline consists of: • A front-end (IF + ID) that can fetch and decode several instructions concurrently • A back-end (EX + MEM) that consists of several pipelines • The WB stage must be such that the processor state is modified according to the original program order.
Two Types of Superscalar • In-order processors: • Instructions leave the front-end in strict program order • All dependencies are resolved at the last stage of the front-end • Good performance relies on optimized compilers • Out-of-order processors • Instructions can execute and complete their execution out-of-order • However, need to replace (extend) the WB stage by a Commit stage that ensures that results are stored in the process stat in-order • Good performance relies on extensive hardware logic
Branch history L1 I-cache ITB Fetch/ Decode Integer Unit F-p Unit IB IS Br.Pred Add/ Mult Add/ Branch Add Mult/ Div Int. Reg. F-p Reg. DTB MAF WB L1 D-cache L2 cache DEC Alpha 21164 (in-order)
S0 S1 S2 S3 S4 S5 S6 Integer S4 S5 S6 S7 S8 Floating-point IF and ID S4 S5 S6 S7 S8 S9 S10 S11 S12 Front-end L1 Cache access L2 cache access EX, Mem and WB Back-end Alpha 21164 Pipeline
L2 cache Bus interface L1 I-cache ITLB L1 D-cache DTLB Exec/Dispatch unit Fetch/Decode unit MOB Br. pred Agu MIS Decoder Fpu Iu RS MMX Reg. map (RAT) ROB RF Instr. Pool & retire unit Block Diagram of the P6 Microarchitecture




















