Download

1 / 46
460 likes | 556 Views
Self-Organization of Speech Sound Inventories in the framework of Complex Networks. Animesh Mukherjee (Roll No.: 05CS9405) Department of Computer Science & Engg. Indian Institute of Technology, Kharagpur. Overview of the Presentation. Basics of Speech Sound Inventories

E N D
Self-Organization of Speech Sound Inventories in the framework of Complex Networks Animesh Mukherjee (Roll No.: 05CS9405) Department of Computer Science & Engg. Indian Institute of Technology, Kharagpur
Overview of the Presentation • Basics of Speech Sound Inventories • Motivation & Objective • Occurrence Network of Consonants • Co-occurrence Network of Consonants • Co-occurrence Patterns in Consonant Inventories • Network Methods applied to Vowel Inventories • Conclusions and Future Directions
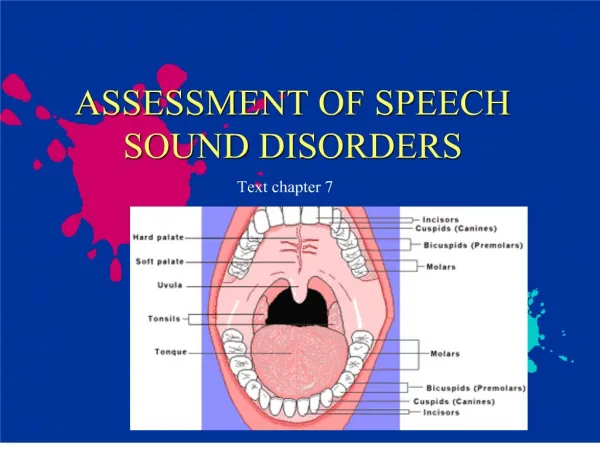
Sound Inventories • A repertoire of unique sounds (aka phonemes) that the speakers of a language use for communication /p/ /b/ /s/ /z/ /r/ …………… English Consonants pit As in bit send zip rat /p/ /b/ /r/ /ɖʱ/ …………… /ɖ/ Bangla Consonants As in pAn bAn ɖAl ɖhol rAtri
Mermelstein’s Model Representation of Phonemes • Articulatory feature based representation • Place of Articulation (labial, velar, alveolar, dental etc.) • Manner of Articulation (plosive, fricative, affricate, nasal etc.) • Phonation (voiced, voiceless)
Choice of Phonemes • Given a set of phonemes how likely is it that the set corresponds to real language inventory? • Does any random subset of phonemes qualify as a real inventory? • Certainly Not! • What are the forces governing the structure of an inventory?
/a/ /a/ Speaker Listener / Learner Forces Governing the Structure A Linguistic System – How does it look? Desires “perceptual contrast” / “ease of learnability” Desires “ease of articulation” Forces shaping the structure are opposing – There has to be a non-trivial solution
Motivation – Choice of the Problem • Vowel inventories • Linguistic arguments (Wang 1971) • Numerical simulations (Liljencrants & Lindblom 1972, Lindblom 1986, Schwartz et al. 1997) • Genetic algorithms (Ke et al. 2003) • Multi-agent simulations (Boer 2000) • Organized based on the principle of maximal perceptual contrast (mainly smaller inventories) • For instance if a language has three vowels then in more than 95% of the cases they are /a/,/i/, and /u/.
Motivation – Choice of the Problem • Consonant Inventories • Linguistic arguments (Clements 2003, Clements 2008, Boersma 1998, Hockett 1974, Lindblom & Maddieson 1988) • Studies limited to certain specific properties • They are much larger in size with many more articulatory/acoustic features • No single force is sufficient to explain their organization • A complex interplay of forces collectively shape their structure.
Motivation – Modeling Methodology • We adopt a complex network approach to capture the self-organization of the consonant inventories • A versatile modeling methodology view & solve the problem from an alternative perspective • Enormous success in explaining various dynamical properties of language (Adilson 2002, Ferrer-i-Cancho & Sole 2001, Gruenenfelder & Pisoni 2005, Kapatsinski 2006, Sigman & Cecchi 2002) • Easy applicability in modeling this particular problem pertaining to sound inventories
Objective • Representation of the Inventories • How can the structure of the consonant inventories be accurately represented within the framework of complex networks? • Analysis of the Inventory Structure • How to conduct the analysis of the network(s) constructed in order to extract meaningful results • Analysis of the Inventory Structure • Explain the emergence of the different statistical properties (obtained from the analysis) by means of generative mechanisms usually based on models of network growth
/θ/ L1 /ŋ/ L2 /m/ Languages Consonants /d/ L3 /s/ L4 /p/ Occurrence Network of Consonants • Phoneme-Language Network (PlaNet) • Bipartite • VL (set of nodes in the language partition) • VC (set of nodes in the consonant partition) • There is an edge eЄ E between vlЄ VL and vcЄ VC iff the consonant c occurs in the language l • PlaNet constructed from the UCLA Phonological Segment Inventory Database (UPSID) 317 languages with 541 unique consonants appearing across them PlaNet
.08 pk = beta(k) with α = 7.06, and β= 47.64 .06 Γ(54.7) k6.06(1-k)46.64 .04 pk pk = Γ(7.06) Γ(47.64) .02 kmin= 5, kmax= 173, kavg= 21 1 50 100 200 0 150 Degree (k) .1 Pk = k -0.71 .01 Pk Exponential Cut-off .001 10 1000 100 1 Degree (k) Degree Distribution (DD) DD of the language nodes follows a β-distribution DD of the consonant nodes follows a power-law with an exponential cut-off pk Fraction of nodes with degree = k Pk Fraction of nodes with degree >= k
Languages Phonemes Growth of PlaNet Rules of the game: • A new language is born Coling-ACL, 2006
Languages Phonemes Growth of PlaNet Rules of the game: • A new language is born • Chooses μ distinct phonemes from the set of existing phonemes preferentially based on the degree γ k +1 (γk + 1) all phonemes not already chosen Coling-ACL, 2006
Analytical Solution for the Growth Model Notations t – #nodes in VL N – #nodes in VC (fixed and finite) pk,t – pk after adding t nodes Markov Chain Formulation (μ=1) where Europhysics Letters, 2007
The Hard Part of the Analysis • Average degree of the VC partition, i.e., (μt)/N diverges as t∞ • Methods based on steady-state and continuous time assumptions fail (pk,t ≠ pk,t+1as t∞) Closed-form solution using linear algebra tricks where η=N/γ Europhysics Letters, 2007
Simulation Data Real Data Theory Fitted Degree Distribution t=317, N=541, μ=21. Best fit for γ=14 Coling-ACL, 2006
/s/ 1 1 1 /k/ /n/ 2 1 2 1 1 1 2 /t/ /d/ 1 2 1 /p/ PhoNet Co-occurrence Network of Consonants • Phoneme-Phoneme Network (PhoNet) • One-mode projection of PlaNet onto the consonant nodes (VC) • Two nodes in this n/w are connected by an edge if they co-occur in the inventory of at least one language. The number of languages they co-occur in defines the weight of the edge.
Degree of the nodes in One-mode • Easy to calculate if each node v in growing partition enters with exactly (> 1) edges • Consider a node u in the non-growing partition having degree k • u is connected to k nodes in the growing partition and each of these k nodes are in turn connected to -1 other nodes in the non-growing partition • Hence degree q=k(-1) Submitted to Europhysics Letters
Degree Distribution • The degree distribution pu(q) of the nodes in the one-mode should be Not a good match at all!!
What if is not fixed?? • Relax the assumption that the size of the consonant inventories is a constant () • Assume these sizes to be random variables being sampled from a distribution fd • It is easy to show that, while the one-mode degree (q) for a node u is dependent on fd, its bipartite n/w degree (k) is not (the kernel of attachment roughly remains the same)
Analysis of Degree Distribution • If fd varies as a Normal Distribution N(μ, σ2) • If fd varies as a Delta function δ(d, μ) • If fd varies as an Exponential function E(λ=1/μ) • If fd varies as Power-law function (power = –λ) Submitted to Europhysics Letters
Results of the Analysis Bipartite Networks One-Mode Networks N = 1000, t = 1000, γ= 2, μ=22
Degree Distribution of PhoNet fd = consonant inventory size distribution Real PhoNet fd = constant Submitted to Europhysics Letters
Clustering Coefficient of PhoNet • The Clustering Coefficient (CC) for a node i is the proportion of links between the nodes that are the neighbors of i divided by the number of links that could possibly exist between them. • CC of PhoNet is 0.89 • CC of the synthesized n/w obtained from our model is 0.35 • The model needs to be refined to increase the number of triangles in the emergent network to match CC
Improving CC – Triad Model L5 L4 L1 L2 L3 IF L4 L5 L6 L1 L2 L3 Then (triad step – pt) L1 L2 L3 L4 L5 L6
Results • The triad model produces CC = 0.85 (within 3.5% of the real network) [0.8<= pt <=0.9] The degree distribution also remains unaffected Journal of Quantitative Linguistics, 2009
plosive voiceless voiced bilabial /b/ /p/ /d/ /t/ dental Patterns of Co-occurrence • Consonants tend to co-occur in groups or communities • These groups tend to be organized around a few distinctive features (based on: manner of articulation, place of articulation & phonation) – Principle of feature economy If a language has in its inventory then it will also tend to have
wuv S = • √Σi ЄVc-{u,v}(wui –wvi)2 • if √Σi ЄVc-{u,v}(wui –wvi)2>0 else S = ∞ Automatic Identification of Co-occurrence Patterns • Community structure analysis of PhoNet • Employ modified Radicchi et al. algorithm • Look for triangles, where the weights on the edges are comparable. If comparable, then the group of consonants co-occur highly else it is not so. • Calculate strength S of each edge • Remove edges with S less than a threshold η International Journal of Modern Physics C, 2007
Consonant Communities η=0.35 η=0.60 η=0.72 η=1.25
pf qf pf pf pf qf qf N N N N N N N Feature Economy: The Binding Force • pf – number of consonants in a community (C) in which feature f is present • qf –number of consonants in C in which feature f is absent • The probability that a consonant chosen at random form C has f is and that is does not have f is (1- ) • If F denote the set of all features, FE= –∑fєF log2 + log2 • FE Total discriminative capacity of the features in an inventory
Comparison between PhoNet and PhoNetrand PhoNetrand PhoNet International Journal of Modern Physics C, 2007
Network Methods forthe Vowel Inventories • Construct two networks • VlaNet (Vowel-Language Network): Bipartite network with one partition of languages (VL) and the other of vowels (VV); an edge signifies the a particular vowel occurs in a particular language; 317 languages and 151 vowels • VoNet (Vowel-Vowel Network): One-mode projection of VlaNet where to vowel nodes are connected as many times as they co-occur across different languages
Degree Distribution (VlaNet) β-distribution as in the case of consonants Theory Real Data Simulation
Degree Distribution (VoNet) fd = consonant inventory size distribution Real Data fd = constant
Clustering Coefficient (VoNet) • CC for VoNet is 0.86 • Using triad model on can achieve a CC of 0.83 (within 3.5%) of the real data The degree distribution also not much affected
Community Analysis of VoNet Two forces acting together Feature Economy Perceptual Contrast
VoNethub, VoNetrest and VoNetrest' • VoNethub • All vowel nodes having frequency of occurrence < 120 removed from VoNet along with all edges A network of hub nodes. • VoNetrest • All vowel nodes in VoNet are retained. Only edges between hub & non-hub nodes removed. • VoNetrest' • All vowel nodes in VoNet are retained. Only edges that connect a hub with a non-hub where the non-hub occurs more than 95% of times with the hub are retained Advances in Complex Systems, 2008
Vowel Communities • VoNethub • VoNetrest • VoNetrest' Advances in Complex Systems, 2008
Feature Economy VoNetrest Feature Economy VoNetrest' Comparison with Randomly Generated Inventories Perceptual Contrast VoNethub Advances in Complex Systems, 2008
Consonant Vs. Vowel Inventories • Topological properties are qualitatively similar preferential attachment plays the key role in the emergence of the structure • Community and redundancy ratio analysis however shows differences • Consonants Feature economy is the key driving force • Vowels Smaller inventories are driven by perceptual contrast while the larger ones are driven by feature economy
Conclusions and Future Directions • Complex Network based modeling allowed us to excavate various interesting universal properties of sound inventories • We do not claim that all the inferences that we draw are sacrosanct; rather they are indicative • Trends are more important than exact values • Results should help propelling future research in self-organizing phonology.
Conclusions and Future Directions • Quite a few theoretical problems that might attract statistical physicists • Network methods highly instrumental in doing computational linguistics • Unsupervised NLP (Distributional Similarity N/ws for learning syntactic and semantic categories) • IR (Blog and Query-log analysis)
Publications from the Thesis [1] M. Choudhury, A. Mukherjee, A. Basu, and N. Ganguly. Analysis and synthesis of the distribution of consonants over languages: A complex network approach. In Proceedings of COLING–ACL, 128–135, 2006. [2] F. Peruani, M. Choudhury, A. Mukherjee, and N. Ganguly. Emergence of a nonscaling degree distribution in bipartite networks: A numerical and analytical study. Euro. Phys. Lett., 79(2):28001, 2007. [3] A. Mukherjee, M. Choudhury, A. Basu, and N. Ganguly. Modeling the cooccurrence principles of the consonant inventories: A complex network approach. Int. Jour. of Mod. Phy. C, 18(2):281–295, 2007. [4] A. Mukherjee, M. Choudhury, A. Basu, and N. Ganguly. Redundancy ratio: An invariant property of the consonant inventories of the world’s languages. In Proceedings of ACL, 104–111, 2007. [5] A. Mukherjee, M. Choudhury, A. Basu, and N. Ganguly. Emergence of community structures in vowel inventories: An analysis based on complex networks. In Proceedings of ACL SIGMORPHON9, 101–108, 2007. [6] A. Mukherjee, M. Choudhury, S. Roy Chowdhury, A. Basu, and N. Ganguly. Rediscovering the co-occurrence principles of the vowel inventories: A complex network approach. Advances in Complex Systems, 11(3):371–392, 2008.
Publications from the Thesis [8] M. Choudhury, A. Mukherjee, A. Garg, V. Jalan, A. Basu, and N. Ganguly. Language diversity across the consonant inventories: A study in the framework of complex networks. In EACL workshop on Cogn. Aspects of Comp. Lang. Acquisition, 51–58, 2009. [9] A. Mukherjee, M. Choudhury, A. Basu, and N. Ganguly. Self-organization of sound inventories: Analysis and synthesis of the occurrence and co-occurrence network of consonants. Journal of Quantitative Linguistics, 16(2):157–184, 2009. [10] A. Mukherjee, M. Choudhury, and N. Ganguly. Analyzing the degree distribution of the one-mode projection of alphabetic bipartite networks (α − BiNs). preprint: arXiv.org:0902.0702.