Semantic Information Resource Description Framework
750 likes | 881 Views
This framework represents knowledge about resources in a machine-readable way, using URIs and triples to denote facts. Learn about RDF, SPARQL, ontologies, and semantic data growth with examples from DBpedia and more.

Semantic Information Resource Description Framework
E N D
Presentation Transcript
Shady Elbassuoni, Luis Galarraga, Peter Haase, Katja Hose, Hassan Issa, Steffen Metzger, Maya Ramanath, Michael Schmidt, Andreas Schwarte, Michael Stoll, Marcin Sydow, Gerhard Weikum
Semantic Information Resource Description Framework: • Represent knowledge about resources (things) in a machine-readable way. • Resources and their relations identified by URIs • Statements (triples) with prefixes represent facts <http://xmlns.com/foaf/0.1/name> <http://www.mpii.de/yago/resource/John_Doe> PREFIX yago: <http://www.mpii.de/yago/resource/> PREFIX foaf: <http://xmlns.com/foaf/0.1/> yago:John_Doe foaf:name “John Doe” Subject Predicate Object Ralf Schenkel
RDF & SPARQL RDF data can be seen as data graph yago:John_Doe foaf:name foaf:knows “John Doe” yago:Max_Mustermann foaf:name “Max Mustermann” SPARQL: Query language for RDF from the W3C for graph pattern queries on the knowledge base Ralf Schenkel
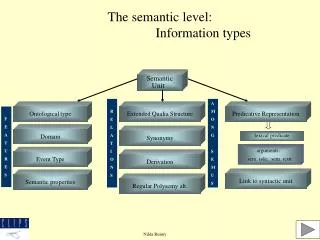
Ontologies for Representing Knowledge “Barack Obama” label “44th president” label resource subclassOf subclassOf classes person location subclassOf domain range subclassOf subclassOf bornIn scientists politician city isA relations isA Single fact: Triple (subject, predicate, object) Example: (Barack_Obama, bornIn, Honolulu) bornIn instances/entities (URIs) Honolulu bornOn 04-08-1961 Ralf Schenkel
SPARQL – Example scientist isA isA actor vegetarian physicist chemist isA isA isA isA isA isA Mike_Myers Jim_Carrey Albert_Einstein Otto_Hahn bornIn bornIn bornIn bornIn Scarborough Newmarket Ulm Frankfurt locatedIn locatedIn locatedIn locatedIn Ontario Germany locatedIn locatedIn Europe Canada Example query:Find all actors from Ontario (that are in the knowledge base) Ralf Schenkel
SPARQL – Example actor constants isA ?person variables bornIn ?loc locatedIn Ontario Example query:Find all actors from Ontario (that are in the knowledge base) SELECT?personWHERE?person isA actor. ?person bornIn ?loc.?loc locatedIn Ontario. scientist Find subgraphs of this form: isA isA actor vegetarian physicist chemist isA isA isA isA isA isA Mike_Myers Jim_Carrey Albert_Einstein Otto_Hahn bornIn bornIn bornIn bornIn Scarborough Newmarket Ulm Frankfurt locatedIn locatedIn locatedIn locatedIn Ontario Germany locatedIn locatedIn Europe Canada Ralf Schenkel
Examples for Semantic Data • General Knowledge Bases: DBPedia, Freebase, YAGO • Domain-specific knowledge: Biology, Geo, Government, Publications, Movies, Songs, … • Linked Open Data as large integrated knowledge base Ralf Schenkel
Semantic Data Grows Rapidly Biggest reported application (telecommunication data): >1 trillion triples More than 31 billion triples in the LOD cloud DBPedia: 3.6 million entities, 1.2 billion triples Ralf Schenkel
Queries can be complex, too SELECT DISTINCT ?a ?b ?lat ?long WHERE { ?a dbpedia:spouse ?b. ?a dbpedia:wikilink dbpediares:actor. ?b dbpedia:wikilink dbpediares:actor. ?a dbpedia:placeOfBirth ?c. ?b dbpedia:placeOfBirth ?c. ?c owl:sameAs ?c2. ?c2 pos:lat ?lat. ?c2 pos:long ?long. } Find actors that are married to each other and were born In the same place, together with coordinates of that place Q7 on BTC2008 in [Neumann & Weikum, 2009] Ralf Schenkel
Outline of the Talk • Introduction • Querying Federations of Knowledge Bases • Building and Querying Distributed RDF Stores • Information Extraction and SPARQL extensions • Cooperative Knowledge Services Ralf Schenkel
Motivation: Federated Execution • Linked Open Data • includes cross-collection links • supports cross-collection querieson large virtual collection • stored in different servers • Naive query execution: • Copy all data to central server • Execute query at central server Many problems: volume of data (>31 billion triples), changes of base data,sources may not provide RDF dump (only SPARQL access) Better: purely virtual integration by federation of sources Ralf Schenkel
Federated Query Processing Federation layer at central server • Computes (distributed) execution plan • Fetches subresults from local sources (SPARQL) • Combines subresults query • Advantages: • Access to live data • No local storage and maintenance • On-demand access to sources Federation • But: • Sources provide only limited level of cooperation • Only limited information about data in each source • User must select sources to include in federation SPARQLEndpoint SPARQLEndpoint SPARQLEndpoint DataSource DataSource DataSource Ralf Schenkel
Naive Federated Processing • Iteratively evaluate triple patterns at all sources • For each resulting binding, fill value in next triple pattern and submit to all sources (nested loop join) • Continue until all patterns are evaluated Example: 3 triple patterns, 4 sources • Evaluate this at all sources: • 200 results from source1: (?Country,?Capital) bindings • no results from other sources • overall 4 requests • For each of the 200 ?Country bind.: • replace ?Country by value (e.g., „Austria ns:population ?CP“) • submit to all sources • overall 200*4 requests, 100 res. (the same from sources 2 and 3) • For each of the 100 ?Capital bind.with matching ?Country bind.: • replace ?Capital by value (e.g., „Wien ns:population ?CP“) • submit to all sources • overall 100*4 requests, 100 res. ?Country ns:capital ?Capital. ?Country ns:population ?CountryPop. ?Capital ns:population ?CapitalPop. Many unnecessary requests: Sources do not have results or overlap in results; inefficient NL join Our approach: Apply techniques from logical, physical, and cost-based query optimization Ralf Schenkel
Query Optimization in FedX Specific optimization techniques in FedX: • Source Selection • Exclusive Groups • Join Order • Bound Joins A.Schwarte, P. Haase, K. Hose, R. Schenkel, M. Schmidt:ESWC 2011 (demo), ISWC 2011 Ralf Schenkel
Technique 1: Source Selection TRUE FALSE FALSE Which sources contribute results for a pattern? • One SPARQL ASK request per source • Local cache to reduce remote communication(with time-based invalidation) save on subsequent queries with this pattern • Annotate triple patterns with relevant sources(for constructing the query) Example: Federation (DBpedia, NYTimes, LinkedMDB) ?Country ns:capital ?Capital. DBPedia: ASK ?Country WHERE {?Country ns:capital ?Capital.} NYTimes: ASK ?Country WHERE {?Country ns:capital ?Capital.} LinkedMDB: ASK ?Country WHERE {?Country ns:capital ?Capital.} only DBpedia relevant for this triple pattern Ralf Schenkel
Technique 2: Exclusive Groups Group joining triple patterns with the same single relevant source • Needs only a single request • Evaluate join at the source, no communication needed Example: Federation (DBpedia, NYTimes, LinkedMDB) SELECT ?President ?Party ?Title WHERE { ?President rdf:type dbpedia:President . ?President dbpedia:Party ?Party . ?President dc:title ?Title . } Source Selection @ DBpedia @ DBpedia @ DBpedia, NYTimes Exclusive Group Execute multiple triple patterns in a single request Ralf Schenkel
Technique 3: Join Order Determine optimal execution order of • triple patterns • Joins in order to minimize intermediate results Example: Federation (DBpedia, LinkedMDB), 100 results SELECT ?actor WHERE { ?actor rdf:type imdb:actor . ?actor bornIn Salzburg . } >1 million results in LinkedMDB 1000 results in DBPedia Execute second triple pattern first Need for selectivity and join statistics at federated level Ralf Schenkel
Technique 4: Bound Joins Perform joins in a block nested loop fashion • Connect bound triple patterns with SPARQL UNIONS • Apply local post-processing to retain correctness • Rename variables to represent original bindings Example: Process join for patterns (?S type U) and (?S p ?O), where results for left argument (?S type U) are already computed Block Input ?S=s1 ?S=s2 ?S=s3 ?S=s4 ?S=s5 Before (NLJ) SELECT ?O WHERE { s1 p ?O } SELECT ?O WHERE { s2 p ?O } SELECT ?O WHERE { s3 p ?O } SELECT ?O WHERE { s4 p ?O } SELECT ?O WHERE { s5 p ?O } Now (bound joins) SELECT ?O_1 ?O_2 .. ?O_5 WHERE { { s1 p ?O_1 } UNION { s2 p ?O_2 } UNION … { s5 p ?O_5 } } Execute in a single remote request Ralf Schenkel
Evaluation Benchmarks using FedBench: SPARQL Federation Often large improvements over state-of-the-art systems Ralf Schenkel
Revisiting the Source Selection Problem SPARQL example (simplified – no prefixes etc.): SELECT ?a WHERE { ?a dc:authorOf ?p. ?p dc:publishedAt SIGMOD2012 .} Source selection problem:Which of the 325 sources to query? Many sources contain the same facts Many duplicate results Many unnecessary requests Obvious problem: overlapping sources Ralf Schenkel
Example for Overlapping Sources • 6 results overall • 2 sources enough to retrieve all results • Source 1 alone is „optimal“ if • only one access possible • or 5 results are enough Source 1 Source 2 Source 3 Our contribution: Determine „optimal“set of sources without seeing the results [SWIM@SIGMOD 2012] Ralf Schenkel
Problem Definition Given SPARQL query with triple patterns P and possible sources S, compute query plan qpPS (which pattern is executed at which source) such that • all results are retrieved with a minimal number of requests to sources (minimal exact plan) • as many results as possible are retrieved with |qp|≤max (maximize recall) • as little requests as possible are performed to retrieve at least r results (minimal approximate plan) Ralf Schenkel
BBQ: High-Level Solution Overview • Extend ASK operation to provide concise yet expressive summary of result bindings of each variable (instead of boolean yes/no) • Estimate source overlap with summaries • Select sources incrementally based on benefit Functional properties of summaries for sets: • Size of set (number of distinct elements) • Size of union of two sets • Size of intersection of two sets • Summary smaller than the data • Data not be reproducible from the summary Examples: Bloom Filters, kmv synopsis, … Significant reduction of query cost compared to standard solutions Ralf Schenkel
Source Selection for Single Triple Pattern • Benefit of a source: number of new results it can contribute • Incremental selection algorithm: • Maintain summary for union of results from sources already selected • Estimate source benefit from summary • Select source with highest benefit • Stop when target (# results or # requests) reached • Finally: Evaluate triple pattern at all selected sources; select more sources if too few results Ralf Schenkel
Example (Single Triple Pattern) 6: 0: 5: 2: 2: 5: 5: 3: 5: 3: 0 1 1 1 0 1 0 1 1 1 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 1 1 1 1 0 0 1 0 0 1 1 1 1 0 0 1 1 0 1 1 1 0 0 0 0 1 1 0 0 1 1 1 1 1 0 Source 1 Source 2 Source 3 1. ASK each source 2. Select source with highest number of results 3. Stop if stopping condition is met (recall or number of results) 4. Compute benefit for each remaining source Source 2: 2 - = 1 Source 3: 3 - = 1 5. Select source with highest benefit 6. Continue with step 3 current result summary Ralf Schenkel
Star-Shaped Queries Multiple triple patterns with a single identical variable • Not enough to consider each triple pattern separately • Need to focus on the intersection of the result sets • Extended incremental algorithm: • Init: Pick one source for each triple pattern with most results • Benefit of evaluating a triple pattern at a source: number of new results in the intersection • Estimated by intersection of per-pattern summaries (union of summaries from each selected source) ?x imdb:gender „female“.?x imdb:bornIn dbpedia:Germany.?x imdb:actedIn imdb:Titanic. Ralf Schenkel
Complex Queries Queries with >1 variable and >1 triple patterns • Summaries not applicable for whole query: • no connection of summaries for variables ?m and ?p • Do new bindings for ?p join with existing bindings for ?m ? • But: separate source selection for each pattern possible • Plus: exclude join candidates at execution time reduces effort for nested-loop joins run full query at sources if no cross-joins possible imdb:Tom_Cruise imdb:actedIn ?m.?m imdb:producedBy ?p. best: 3 local joins naive:3x3 joins improved:6 joins Ralf Schenkel
Experimental Evaluation: Setup • RDF Dataset from first 100,000 IMDB moviesand their actors and directors • Generate overlapping partitions • For movies based on genre (28 partitions) • For persons based on birthplace and birthdate (22 p.) • Queries: • 20 single triple patterns • 20 star-shaped queries • Consider minimal exact plan • Bloom filters of different sizes, kmv synopsis Ralf Schenkel
Triple Pattern Queries Much fewer requests while retrieving (almost) all results Ralf Schenkel
Extensions of Federated Processing • Increase sources‘ level of cooperation: • Export extensive selectivity and join statistics(improves federated join order) • Interfaces beyond SPARQL (enables more efficient joins) • Caching of data at federated level(reduces latency and risk of unavailable sources) • Best-effort execution for given cost budget(time, messages, money), considering • overlap of sources • fraction of results retrieved • quality of a source (correctness, trust, recency) Ralf Schenkel
Outline of the Talk • Introduction • Querying Federations of Knowledge Bases • Building and Querying Distributed RDF Stores • Information Extraction and SPARQL extensions • Cooperative Knowledge Services Ralf Schenkel
Motivation: Distributed RDF Improve storing and querying of RDF in one system bydistributing it over multiplemachines • Improve storage capacity(rule of thumb: 50GB per 1 billion triples) • Improve query processing performance by • Keeping data in memory • Exploiting parallelism • General approach: • Build small fragments of the data • Allocate fragments to nodes • Rewrite SPARQL queries to consider distributed data Ralf Schenkel
Partout: High-Level Architecture Ralf Schenkel
Partout: Workload-Based Fragmentation • Consider “typical” query workload • Use triple patterns in queries for fragmentation SELECT ?s, ?o WHERE { ?s foaf:name ?o. } • For two triple patterns P1, P2: • Consider all combinations of Pi and their negation:P1 P2, P1 P2, P1 P2, P1 P2 • Each combination defines a fragment • Number of fragments exponential in number of triplepatterns, but usually ok (many must be empty) Ralf Schenkel
Fragment Allocation and Querying • Allocate fragments to hosts such that • Execution of each workload query is cheapby allocating its fragments at same host • Hosts receive balanced load and limited number of triples • Formulate as Integer Linear Program Use greedy heuristics for large optimization problem Ralf Schenkel
Details for Fragment Allocation balancedload localqueries number of queries where fragments m and m‘ appear together size of fragment frequency of fragment aggregated load of all fragments allocated to host h Ralf Schenkel
Querying Processing • Query processing similar to federated case, but • Full information about triple location • Full information about local statistics • More complex operations (semi joins etc.) • Two-stage query optimization: • Start with RDF-3X query plan using aggregated statistics from complete dataset • Transform + optimize for distributed setup • Extension of RDF-3X cost model to consider communication costs. Ralf Schenkel
Example: Query optimization Initial RDF-3X query plan Step 1: Source identification PREFIX db: <http://dbpedia.org/resource/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> SELECT ?name WHERE{ ?z db:name ?name . ?z rdf:type db:city . ?z db:located db:USA . } Ralf Schenkel
Example: Query optimization Initial RDF-3X query plan Step 2: Merge-Union Operators PREFIX db: <http://dbpedia.org/resource/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> SELECT ?name WHERE{ ?z db:name ?name . ?z rdf:type db:city . ?z db:located db:USA . } Ralf Schenkel
Example: Query optimization Initial RDF-3X query plan Step 3: optimizations and host allocation for inner operators Ralf Schenkel
Evaluation: Billion Triple Challenge 2008 • 500 million triples, 3 hosts • opponents: • centralized RDF3X • property-based distribution • graph partitioning (HAR+, VLDB 2011) Significant advantage for Partout in response time (and throughput) Ralf Schenkel
Outline of the Talk • Introduction • Querying Federations of Knowledge Bases • Building and Querying Distributed RDF Stores • Information Extraction and SPARQL extensions • Cooperative Knowledge Services Ralf Schenkel
Question Answering with the Web Ralf Schenkel
Limits in Entities and Facts Ralf Schenkel
List Questions on the Web Ralf Schenkel
Limits in Query Complexity Ralf Schenkel
Use case „Goethe tour“ • Problem:Build interesting tour that combinesplaces Goethe visited at least once • Combines (historic and encyclopedic)text from libraries and TextGrid,information about historic names,(routable) maps, hotel portals, … • Workflow: • Search texts about Goethe • Extract locations • Map to current locations • Assess interestingness … Ralf Schenkel
Searching is difficult • How is Goethe mentioned in the text?„Johann Wolfgang von Goethe“, „Goethe“, „Goete“,„the author of Faust“ • Difficult to restrict results to Goethe‘s travels • Extend query by „travel“, „trip“, „stay“? • Could miss important results! • Documents need to be read completely to extract important knowledge • Places that Goethe visited • Additional information on these places, e.g., • Is the place in Germany? • Are there any interesting sights there? Named Entity Recognition Automated Fact Extraction Structured Queries Background Knowledge Ralf Schenkel
Step 1: Named Entity Recognition • Goal: Map entity occurrences in texts to • predefined categories (persons, locations, …) • predefined lists of entities (Goethe, Schiller, …) • Input: Background knowledge base (YAGO, …) • Entities with their textual representations(Goethe: „Goethe“, „Goete“, „Herr Geheimer Rath“, …) • Mapping of entities to categories(Goethe is an author, is a person, …) • Relationships to other entities(Goethe was born in Frankfurt, died in Weimar, …) This talk Ralf Schenkel
Example: Named Entity Recognition Goethe was born in Frankfurt in August 1749. Identify the „correct“ Frankfurt basedon context in the document Goal: coherent map of all entity occurrences Goethe label „Goethe“ KnowledgeBase Frankfurt(Main) label „Frankfurt“ Frankfurt(Oder) label „Frankfurt“ Ralf Schenkel