Download

1 / 67
680 likes | 974 Views
Zettabyte File System (File System Married to Volume Manager). Dusan Baljevic Sydney, Australia. Server Market Trends. Revenue Share Revenue Share Percent Vendor 2Q 2005 2Q 2005 2Q 2006 2Q 2006 Growth IBM $3,893 31.9% $3,808 31.2% -2.2%

E N D
Zettabyte File System (File System Married to Volume Manager) Dusan Baljevic Sydney, Australia
Server Market Trends Revenue Share Revenue Share Percent Vendor 2Q 2005 2Q 2005 2Q 2006 2Q 2006 Growth IBM $3,893 31.9% $3,808 31.2% -2.2% HP $3,480 28.5% $3,420 28.0% -1.7% Sun $1,372 11.2% $1,585 13.0% 15.5% Dell $1,286 10.5% $1,269 10.4% -1.3% Fujitsu $551 4.5% $554 4.5% 0.5% Others $1,638 13.4% $1,651 13.5% 0.8% All $12,219 $12,287 0.6% Note: Revenue in Billions of USD Source: IDC http://www.itjungle.com/tug/tug082406-story02.html Dusan Baljevic, 2007
ZFS Design Goals • A zettabyte (derived from the SI prefix zetta-) is a unit of information or computer storage equal to one sextillion (one long scale trilliard) bytes: Zetta Byte = 1021 Bytes ~ 270 Bytes • Officially introduced with Solaris 10 06/06 • Combines Volume Manager and File System (storage pool concept) • Based on a transactional object model • 128-bit file system (If Moore's Law holds, in 10 to 15 years humanity will need the 65th bit) • Data integrity Dusan Baljevic, 2007
ZFS Design Goals (continued) • Snapshot and compression support • Endian-neutral • Automated common administrative tasks and near-zero administration • Performance • Virtually unlimited scalability • Flexibility Dusan Baljevic, 2007
ZFS – Modern Approach F/S Creator Introduced O/S HFS Apple Computer 1985 MacOS VxFS VERITAS 1991 SVR4.0 AdvFS DEC pre-1993 Digital Unix UFS1 Kirk McKusick 1994 4.4BSD … ZFS Sun Microsystems 2004 Solaris Reiser4 Namesys 2004 Linux OCFS2 Oracle 2005 Linux NILFS NTT 2005 Linux GFS2 Red Hat 2006 Linux ext4 Andrew Morton 2006 Linux Dusan Baljevic, 2007
Traditional File Systems and ZFS (diagram courtesy of Sun Microsystems) Dusan Baljevic, 2007
ZFS Storage Pools • Logical collection of physical storage devices • Virtual storage pools make it easy to expand or contract file systems by adding physical devices • A storage pool is also the root of the ZFS file system hierarchy. The root of the pool can be accessed as a file system (for example, mount or unmount, snapshots, change properties) • ZFS storage pools are divided into datasets (file system, volume, or snapshot). Datasets are identified by unique paths: • /pool-name/dataset-name Dusan Baljevic, 2007
ZFS Administration Tools • Standard tools are zpool and zfs • Most tasks can be run through a web interface (ZFS Administration GUI and the SAM FS Manager use the same underlying web console packages): https://hostname:6789/zfs Prerequisite: #/usr/sbin/smcwebserver start #/usr/sbin/smcwebserver enable • zdb (ZFS debugger) command for support engineers Dusan Baljevic, 2007
ZFS Transactional Object Model • All operations are copy-on-write (COW). Live data is never overwritten • ZFS writes data to a new block before changing the data pointers and committing the write. Copy-on-write provides several benefits: * Always-valid on-disk state * Consistent, reliable backups * Data rollback to known point in time • Time-consuming recovery procedures like fsck are not required if the system is shut down in an unclean manner Dusan Baljevic, 2007
ZFS Snapshot versus Clone • Snapshot is a read-only copy of a file system (or volume) that initially consumes no additional space. It cannot be mounted as a file system. ZFS snapshots are immutable. This features is critical for supporting legal compliance requirements, such as Sarbanes-Oxley, where businesses have to demonstrate that the view of the data at a given point in time is correct • Clone is a write-enabled “snapshot”. It can only be created from a snapshot. A clone can be mounted • Snapshot properties are inherited at creation time and cannot be changed Dusan Baljevic, 2007
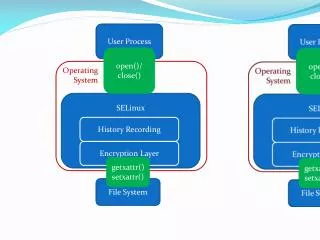
ZFS Data Integrity • Solaris 10 with ZFS is the only known operating system designed to provide end-to-end checksum capability for all data • All data is protected by 64-bit checksums • ZFS constantly reads and checks data to help ensure it is correct. If it detects an error in a mirrored pool, the technology can automatically repair the corrupt data Dusan Baljevic, 2007
ZFS Data Integrity (continued) • Checksums stored with indirect blocks • Self-validating, self-authenticating checksum tree • Detects phantom writes, misdirections, common administrative errors (for example, swap on active ZFS disk) Dusan Baljevic, 2007
ZFS Endianess • ZFS is supported on both SPARC and x86 platforms • One can easily move storage pools from a SPARC to an x86 server. Neither architecture pays a byte-swapping "tax" due to "adaptive endian-ness" technology (unique to ZFS) Dusan Baljevic, 2007
ZFS Scalability • Enables administrators to state the intent of their storage policies rather than all of the details needed to implement them • To resize ZFS is easy. To resize an UFS requires downtime and data restore from tapes or other disks • Maximum filename length = 255 Bytes • Allowable characters in directory entries = Any Unicode except NUL • Maximum pathname length = No limit defined • Maximum file size = 16 EB • Maximum volume size = 16 EB Dusan Baljevic, 2007
ZFS Scalability (continued) • 248 snapshots in any file system • 248 files in any individual file system • 16 EB files • 16 EB attributes • 3x1023 PB storage pools • 248 attributes for a file • 248 files in a directory • 264 devices in a storage pool • 264 storage pools per system • 264 file systems per storage pool Dusan Baljevic, 2007
ZFS Scalability (continued) Dusan Baljevic, 2007
ZFS Scalability (continued) Dusan Baljevic, 2007
ZFS Scalability (continued) Dusan Baljevic, 2007
ZFS Scalability (continued) Dusan Baljevic, 2007
ZFS Flexibility • When additional disks are added to an existing mirrored or RAID-Z pool, the ZFS is “rebuilt” to redistribute the data. This feature owes a lot to its conceptual predecessor, WAFL, the “Write Anywhere File Layout” file system developed by NetApp for their network file server applicances • Dynamic striping across all devices to maximize throughput • Copy-on-write design (most disk writes sequential) • Variable block sizes (up to 128 kilobytes), automatically selected to match workload Dusan Baljevic, 2007
ZFS Flexibility (continued) • Globally optimal I/O sorting and aggregation • Multiple independent prefetch streams with automatic length and stride detection • Unlimited, instantaneous read/write snapshots • Parallel, constant-time directory operations • Explicit I/O priority with deadline scheduling Dusan Baljevic, 2007
ZFS Simplifies NFS • To share file systems via NFS, no entries in /etc/dfs/dfstab are required • Automatically handled by ZFS if the property sharenfs=on is set • Commands zfs share and zfs unshare Dusan Baljevic, 2007
ZFS RAID Levels • ZFS file systems automatically stripe across all top-level disk devices • Mirrors and RAID-Z devices are considered to be top-level devices • It is not recommended to mix RAID types in a pool (zpool tries to prevent this, but it can be forced with the -f flag) Dusan Baljevic, 2007
ZFS RAID Levels (continued) The following RAID levels are supported: * RAID-0 (striping) * RAID-1 (mirroring) * RAID-Z (similar to RAID-5, but with variable- width stripes to avoid RAID-5 write hole) * RAID-Z2 (double-parity RAID-5) Dusan Baljevic, 2007
ZFS RAID Levels (continued) • A RAID-Z configuration with N disks of size X with P parity disks can hold approximately (N-P)*X bytes and can withstand one device failing • Start a single-parity RAID-Z configuration at 3 disks (2+1) • Start a double-parity RAID-Z2 configuration at 5 disks (3+2) • (N+P) with P = 1 (RAID-Z) or 2 (RAID-Z2) and N equals 2, 4, or 8 • The recommended number of disks per group is between 3 and 9 (use multiple groups if larger) Dusan Baljevic, 2007
ZFS Copy-On-Write (courtesy of Jeff Bonwick) Dusan Baljevic, 2007
ZFS and Disk Arrays with Own Cache • ZFS does not “trust” that anything it writes to the ZFS Intent Log (ZIL) made it to your storage, until it flushes the storage cache • After every write to the ZIL, ZFS executes an fsync() call to instruct the storage to flush its write cache to the disk. ZFS will not consider a write operation done until the ZIL write and flush have completed • Problem might occur when trying to layer ZFS over an intelligent storage array with a battery-backed cache (due to arrays ability to use cache and override ZFS activities) Dusan Baljevic, 2007
ZFS and Disk Arrays with Own Cache (continued) • Initial tests show that HP EVAs and Hitachi/HP XP SAN are not affected and work well with ZFS • Lab test will provide more comprehensive data for HP EVA and XP SAN Dusan Baljevic, 2007
ZFS and Disk Arrays with Own Cache (continued) Two possible solutions for SAN that are affected: • Disable the ZIL. The ZIL is the way ZFS maintains consistency until it can get the blocks written to their final place on the disk. BAD OPTION! • Configure the disk array to ignore ZFS flush commands. Quite safe and beneficial Dusan Baljevic, 2007
Configure Disk Array to Ignore ZFS flush For Engenio arrays (Sun StorageTek FlexLine 200/300 series, Sun StorEdge 6130, Sun StorageTek 6140/6540, IBM DS4x00, many SGI InfiniteStorage arrays): • Shut down the server or, at minimum, export ZFS pools before running this • Cut and paste the following into the script editor of the "Enterprise Management Window" of the SANtricity management GUI: Dusan Baljevic, 2007
Configure Disk Array to Ignore ZFS flush – Script Example //Show Solaris ICS option show controller[a] HostNVSRAMbyte[0x2, 0x21]; show controller[b] HostNVSRAMbyte[0x2, 0x21]; //Enable ICS set controller[a] HostNVSRAMbyte[0x2, 0x21]=0x01; set controller[b] HostNVSRAMbyte[0x2, 0x21]=0x01; //Make changes - rebooting controllers show "Rebooting A controller."; reset controller[a]; show "Rebooting B controller."; reset controller[b]; Dusan Baljevic, 2007
Why ZFS Now? • ZFS is positioned to support more file systems, snapshots, and files in a file system than can possibly be created in the foreseeable future • Complicated storage administration concepts are automated and consolidated into straightforward language, reducing administrative overhead by up to 80 percent • Unlike traditional file systems that require a separate volume manager, ZFS integrates volume management functions. It breaks out of “one-to-one mapping between the file system and its associated volumes” limitation with the storage pool model. When capacity is no longer required by one file system in the pool, it becomes available to others Dusan Baljevic, 2007
Dusan’s own experience • Numerous tests on a limited number of Sun SPARCand Intel platforms consistently showed that ZFS outperformed Solaris Volume Manager (SVM) on same physical volumes by at least 25% • Ease of maintenance made ZFS a very attractive option • Ease of adding new physical volumes to pools and automated resilvering was impressive Dusan Baljevic, 2007
Typical ZFS on SPARC Platform Unless specifically requested, this type of configuration is very common: • 73 GB internal disks are used • Internal disks are c0t0d0s2 and c1t0d0s2 • SVM is used for mirroring • Physical memory is 8GB Dusan Baljevic, 2007
Typical Swap Consideration • Primary swap is calculated by using the following… • If no additional storage available (only two internal disks used): 2 x RAM, if RAM <= 8GB 1 x RAM, if RAM > 8GB • If additional storage available, make primary swap relatively small (4GB) and add additional swaps on other disks as necessary Dusan Baljevic, 2007
Typical ZFS on SPARC Platform (no Sun Cluster) Slice Filesystem Size Type Mirror Description s0 / 11GB UFS Yes Root s1 Swap 8GB Yes Swap s2 All 73GB s3 /var 5GB UFS Yes /var s4 / 11GB UFS Yes Alternate Root s5 /var 5GB UFS Yes Alternate /var s6 30GB ZFS Yes Application SW s7 SDB replica 64MB SVM mgmt Dusan Baljevic, 2007
Typical ZFS on SPARC Platform (up to Sun Cluster 3.1 – ZFS not supported) Slice Filesystem Size Type Mirror Description s0 / 30GB UFS Yes Root s1 Swap 8GB Yes Swap s2 All 73GB s3 /global 512MB UFS Yes Sun Cluster (SC) s4 / 30GB UFS Yes Alternate Root s5 /global 512MB UFS Yes Alternate SC s6 Not used s7 SDB replica 64MB SVM mgmt Dusan Baljevic, 2007
Support for ZFS in Sun Cluster 3.2 • ZFS is supported as a highly available local file system in the Sun Cluster 3.2 release • ZFS with Sun Cluster offers a file system solution combining high availability, data integrity, performance, and scalability, covering the needs of the most demanding environments Dusan Baljevic, 2007
ZFS Best Practices • Run ZFS on servers that run 64-bit kernel • One GB or more of RAM is recommended • Because ZFS caches data in kernel addressable memory, the kernel will possibly be larger than with other file systems. Use the size of physical memory as an upper bound to the extra amount of swap space that might be required • Do not use slices on the same disk for both swap space and ZFS file systems. Keep the swap areas separate from the ZFS file systems • Set up one storage pool using whole disks per system Dusan Baljevic, 2007
ZFS Best Practices (continued) • Set up a replicated pool (raidz, raidz2, or raid1 configuration) for all production environments • Do not use disk slices for storage pools intended for production use • Set up hot spares to speed up healing in the face of hardware failures • For replicated pools, use multiple controllers to reduce hardware failures and improve performance Dusan Baljevic, 2007
ZFS Best Practices (continued) • Run zpool scrub on a regular basis to identify data integrity problems. For consumer-quality drives, set up weekly scrubbing schedule. For datacenter-quality drives, set up monthly scrubbing schedule • If workloads have predictable performance characteristics, separate loads into different pools • For better performance, use individual disks or at least LUNs made up of just a few disks • Pool performance can degrade when it is very full and file systems are updated frequently (busy mail or web proxy server). Keep pool space under 80% utilization to maintain pool performance Dusan Baljevic, 2007
ZFS Backups • Currently, ZFS does not provide a comprehensive backup or restore utility like ufsdump and ufsrestore • Use the zfs send and zfs receive commands to capture ZFS data streams • You can use the ufsrestore command to restore UFS data into a ZFS file system • Use ZFS snapshots as a quick and easy way to backup file systems • Create an incremental snapshot stream (zfs send -i) Dusan Baljevic, 2007
ZFS Backups (continued) • zfs send and zfs receive commands are not enterprise-backup solutions • Sun StorEdge Enterprise Backup Software (Legato Networker 7.3.2 and above) can fully backup and restore ZFS files including ACLs • Veritas NetBackup product can be used to back up ZFS files, and this configuration is supported. However, it does not currently support backing up or restoring NFSv4-style ACL information from ZFS files. Traditional permission bits and other file attributes are correctly backed up and restored Dusan Baljevic, 2007
ZFS Backups (continued) • IBM Tivoli Storage Manager backs up and restores ZFS file systems with the CLI tools, but the GUI seems to exclude ZFS file systems. Non-trivial ZFS ACLs are not preserved • Computer Associates' BrightStor ARCserve product backs up and restores ZFS file systems. ZFS ACLs are not preserved Dusan Baljevic, 2007
ZFS and Data Protector • According to “HP Openview Storage Data Protector Planned Enhancements to Platforms, Integrations, Clusters and Zero Downtime Backups version 4.2”, dated 12th of January 2007: Back Agent (Disk Agent) support for Solaris 10 ZFS will be released in Data Protector 6 in March 2007 http://storage.corp.hp.com/Application/View/ProdCenter.asp?OID=326828&rdoType=filter&inpCriteria1=QuickLink&inpCriteria2=nothing&inpCriteriaChild1=3#QuickLink Dusan Baljevic, 2007
ZFS by Example • To create a simple ZFS RAID-1 pool: zpool create custpool mirror c0t0d0 c1t0d0 zpool create p2m mirror c0t0d0 c0t1d0 mirror c0t2d0 c0t3d0 • When only one file system in a storage pool, the zpool create command does everything: *Writes an EFI label on the disk *Creates a pool of the specified name including structures for data protection * Creates a file system of same name, creates directory and mounts file system on /custpool * Mount point preserved across reboots Dusan Baljevic, 2007
ZFS by Example (continued) • To create a simple ZFS RAID-1 pool by using more powerfull zfs command: zfs create custpool mirror c0t0d0 c1t0d0 • To create three file systems that share the same pool, and one of the file systems is limited to, say, 525 MB: zfs create custpool/apps zfs create custpool/home zfs create custpool/web zfs set quota=525m custpool/web Dusan Baljevic, 2007
ZFS by Example (continued) • Mount file system via /etc/vfstab zfs set mountpoint=legacy custpool/db • Check status of pools: zpool status • Umount / Mount all ZFS file systems zfs umount –a zfs mount –a • Upgrade ZFS pool version (from RAID-Z to RAID-Z2, for example) zpool upgrade custpool Dusan Baljevic, 2007
ZFS by Example (continued) • Clear pool's error count zpool clear custpool • Delete a file system zfs destroy custpool/web • Data integrity can be checked by running manual scrubbing zpool scrub custpool zpool status -v custpool • Check if any problem pools exist zpool status -x Dusan Baljevic, 2007
ZFS by Example (continued) • To offline a failing disk drive zpool offline custpool c0t1d0 • Once the drive has been physically replaced, run the replace command against the device zpool replace custpool c0t1d0 • After an offlined drive has been replaced, it can be brought back online zpool online custpool c0t1d0 • Show installed ZFS version (V2 on Solaris 10u2, and V3 on Solaris 10u3) zpool upgrade Dusan Baljevic, 2007