Download

1 / 20
200 likes | 315 Views
This research focuses on predicting outer membrane proteins (OMPs) in Gram-negative bacteria, which are significant due to their roles as drug targets in disease-causing pathogens. We utilize a frequent subsequence mining approach to identify unique sequence patterns in OMPs, leveraging discriminative sequence information. Two classification techniques, rule-based classification and support vector machines (SVM), are implemented to enhance prediction precision and recall. Empirical results indicate that SVM outperforms traditional methods, providing valuable insights for biological applications and the development of new diagnostics and therapies.

E N D
Frequent-Subsequence-Based Prediction of Outer Membrane Proteins R. She, F. Chen, K. Wang, M. Ester, School of Computing Science J. L. Gardy, F. S. L. Brinkman Dept. of Mol. Biology & Biochemistry Simon Fraser University, BC Canada
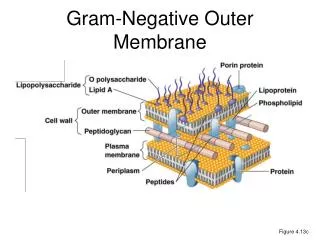
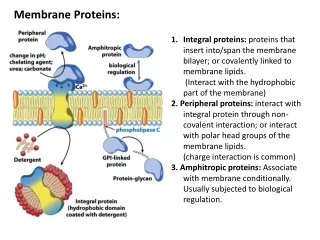
1. Problem Introduction • Gram-negative bacteria • Medically important disease-causing bacteria • 5 sub-cellular localizations (2 layers of membranes) 1. Cytoplasmic 5. Extra-cellular 2. Inner Membrane 4. Outer Membrane 3. Periplasmic
Outer Membrane Proteins • Predicting outer membrane proteins (OMPs) of Gram-negative bacteria • attached to the “outer membrane” of Gram-negative bacterial cell • Particularly useful as drug target
Outer loop Inner turn -strand Outer Membrane Protein (Cont.) • structure: • -strands, form central barrel shape • Inner turns, shorter stretches • Outer loops, longer stretches Extracellular side Outer membrane Periplasmic side
Challenges • Identifying OMPs from sequence information alone • Discriminative sequence patterns of OMPs would be helpful
Challenges (Cont.) • favor precision over recall • lengthy time and laborious effort to study targeted drug in lab Confusion Matrix • Overall accuracy = (TP+TN) / E • Precision = TP / A • Recall = TP / C
2. Dataset • OMP sequence dataset • Excellent quality (http://www.psort.org/dataset) • Protein sequences (strings over alphabet of 20 letters) e.g. MNQIHK… • Two classes with imbalanced distributions
Evaluation • Majority of data is non-OMP, overall accuracy is determined mainly by non-OMP prediction; • Precision is our main concern (90%); • Recall should be maintained at reasonable level (50%).
3. Related Work • Existing sub-cellular localization predictors • Inner membrane proteins have -helix structures – prediction is highly accurate • Prediction of cytoplasmic, periplasmic and extracellular proteins • neural networks, covariant discriminate algorithm, Markov chain models, support vector machines (highest accuracy: 91%) • Do not apply to OMPs
Existing work on OMP prediction • Neural networks, Hydrophobicity analysis, Combination of methods (homology analysis, amino acid abundance) • Current state-of-the-art • Hidden Markov Models by Martelli et al. [1] • Use HMM to model OMPs according to their 3D structures • Training set is small (12 proteins with known 3D structures) • Overall accuracy: 89%; Recall: 84%; Precision: 46%.
4. Algorithms • Motivations • Frequent subsequence mining is helpful • frequent subsequence: consecutive amino acids that occur frequently in OMPs • OMP characteristics • Common structure in OMPs • Different regions have different characteristic sequence residues • Model local similarities by frequent subsequences and highly variable regions by wild cards (*X*X*…) => Association-Rule-based classification
Algorithm 1: Rule-Based Classification • Mine frequent subsequences X (consecutive amino acids) only from OMP class (support(X) MinSup). • Remove trivial similarities by restricting minimum length (MinLgh) of frequent subsequences • Find frequent patterns (*X*X*…) • Build classifier using frequent pattern rules (*X*X*… OMP).
Algorithm 1: Refined • The previous classifier performs good in precision, but poor in recall • A second level of classifier is built on top of the existing classifier • New training data: cases covered by the default rule in the first classifier • Apply same pattern-mining and classifier-building process • Future case is first matched against the 1st classifier; if it is classified as OMP, we accept it; otherwise the 2nd classifier is used.
Algorithm 2: SVM-based Classification • Support Vector Machines (SVM) [5] • Excellent performer in previous biological sequence classification • Data needs to be transformed for SVM to be used (sequences => vectors) • Frequent subsequences of OMPs are used as features. • Protein sequences are mapped into binary vectors.
5. Empirical Studies • 5 Classification methods • Single-level Rule-Based Classification (SRB) • Refined Rule-Based Classification (RRB) • SVM-based Classification (SVM-light [6]) • Martelli’s HMM • See5 (latest version of C4.5) • 5-fold cross validation (same folding for all algorithms)
Summary of Classifier Comparison • SVM outperforms all methods • RRB is the 2nd best performer • Both SVM and RRB outperform HMM • Improvement from SRB to RRB shows that refinement works
Other Biological Benefits (Rule-Based Classifiers) • Sequential rules (obtained by SRB/RRB) lead to biological insights • Mapped to both β-strands and periplasmic turn regions • Assist in developing 3D models for proteins • Identification of primary drug target regions • conserved sequences in the surface-exposed regions are ideal targets for new diagnostics and drugs
6. Conclusions and Future Work • Contributions • Provide excellent predictors for OMP prediction; • Obtained interpretable sequential patterns for further biological benefits; • Proposed the use of frequent subsequences for SVM feature extraction; • Demonstrated the usefulness of data mining techniques in biological sequence analysis.
Future Work • Include more features of sequences, e.g., secondary structure, additional properties of proteins, barrel and turn sizes, polarity of amino acides, etc. • Explore ways to extract symbolic information from SVMs
References • Martelli P., Fariselli P., Krogh A. and Casadio R., A sequence-profile-based HMM for predicting and discrimating barrel membrane proteins, Bioinformatics, 18(1) 2002, S46-S53, 2002. • Wang J., Chirn G., Marr T., Shapiro B., Shasha D. and Zhang K., Combinatorial Pattern Discovery for Scientific Data: Some Preliminary Results, SIGMOD-94, Minnesota, USA, 1994. • Wang K., Zhou S. and He Y., Growing Decision Tree on Support-less Association Rules, KDD’00, Boston, MA, USA, 2000. • Quinlan J., C4.5: programs for machine learning, Morgan Kaufmann Publishers, 1993. • Vapnik V., The Nature of Statistical Learning Theory, Springer-Verlag, New York, 1995. • Joachims T., Learning to Classify Text Using Support Vector Machines. Dissertation, Kluwer, 2002. software downloadable at http://svmlight.joachims.org/ • Rulequest Research, Information on See5/C5.0, at http://www.rulequest.com/see5-info.html