Download
1 / 1
10 likes | 77 Views
A recipe for phonetically conditioned sound change Bridget J. Smith (Ohio State University). Phonetically-conditioned sound change

E N D
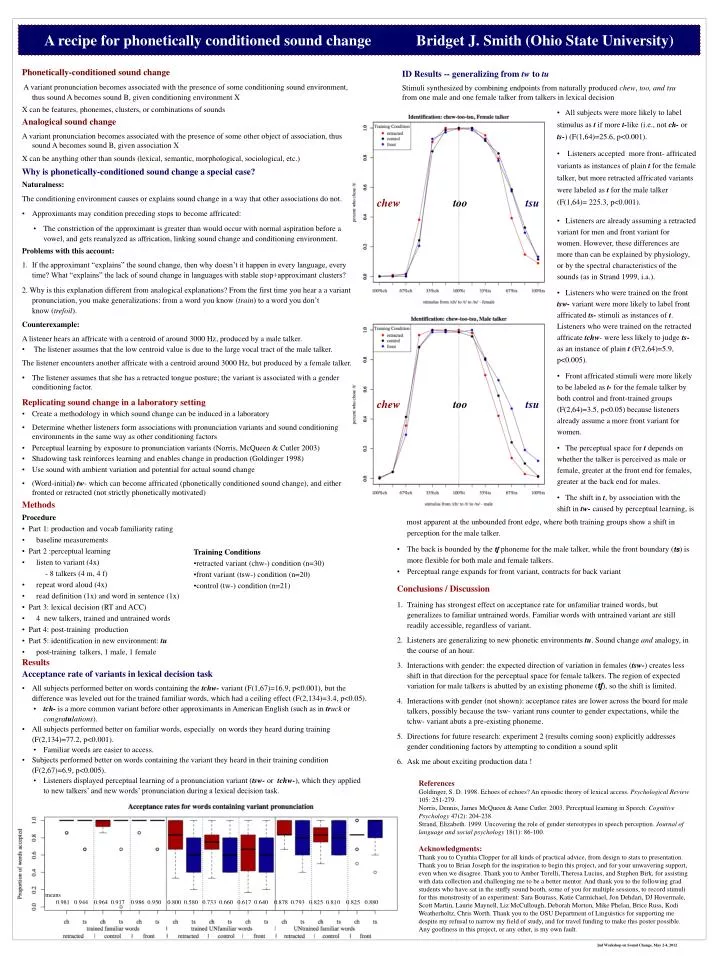
A recipe for phonetically conditioned sound change Bridget J. Smith (Ohio State University) • Phonetically-conditioned sound change • A variant pronunciation becomes associated with the presence of some conditioning sound environment, thus sound A becomes sound B, given conditioning environment X • X can be features, phonemes, clusters, or combinations of sounds • Analogical sound change • A variant pronunciation becomes associated with the presence of some other object of association, thus sound A becomes sound B, given association X • X can be anything other than sounds (lexical, semantic, morphological, sociological, etc.) • Why is phonetically-conditioned sound change a special case? • Naturalness: • The conditioning environment causes or explains sound change in a way that other associations do not. • Approximants may condition preceding stops to become affricated: • The constriction of the approximant is greater than would occur with normal aspiration before a vowel, and gets reanalyzed as affrication, linking sound change and conditioning environment. • Problems with this account: • If the approximant “explains” the sound change, then why doesn’t it happen in every language, every time? What “explains” the lack of sound change in languages with stable stop+approximant clusters? 2. Why is this explanation different from analogical explanations? From the first time you hear a a variant pronunciation, you make generalizations: from a word you know (train) to a word you don’t know (trefoil). Counterexample: A listener hears an affricate with a centroid of around 3000 Hz, produced by a male talker. • The listener assumes that the low centroid value is due to the large vocal tract of the male talker. The listener encounters another affricate with a centroid around 3000 Hz, but produced by a female talker. • The listener assumes that she has a retracted tongue posture; the variant is associated with a gender conditioning factor. • Replicating sound change in a laboratory setting • Create a methodology in which sound change can be induced in a laboratory • Determine whether listeners form associations with pronunciation variants and sound conditioning environments in the same way as other conditioning factors • Perceptual learning by exposure to pronunciation variants (Norris, McQueen & Cutler 2003) • Shadowing task reinforces learning and enables change in production (Goldinger 1998) • Use sound with ambient variation and potential for actual sound change • (Word-initial) tw- which can become affricated (phonetically conditioned sound change), and either fronted or retracted (not strictly phonetically motivated) • Methods • Results • Acceptance rate of variants in lexical decision task • All subjects performed better on words containing the tchw- variant (F(1,67)=16.9, p<0.001), but the difference was leveled out for the trained familiar words, which had a ceiling effect (F(2,134)=3.4, p<0.05). • tch- is a more common variant before other approximants in American English (such as in truck or congratulations). • All subjects performed better on familiar words, especially on words they heard during training (F(2,134)=77.2, p<0.001). • Familiar words are easier to access. • Subjects performed better on words containing the variant they heard in their training condition (F(2,67)=6.9, p<0.005). • Listeners displayed perceptual learning of a pronunciation variant (tsw- or tchw-), which they applied to new talkers’ and new words’ pronunciation during a lexical decision task. ID Results -- generalizing from tw to tu Stimuli synthesized by combining endpoints from naturally produced chew, too, and tsu from one male and one female talker from talkers in lexical decision • All subjects were more likely to label stimulus as t if more t-like (i.e., not ch- or ts-) (F(1,64)=25.6, p<0.001). • Listeners accepted more front- affricated variants as instances of plain t for the female talker, but more retracted affricated variants were labeled as t for the male talker (F(1,64)= 225.3, p<0.001). • Listeners are already assuming a retracted variant for men and front variant for women. However, these differences are more than can be explained by physiology, or by the spectral characteristics of the sounds (as in Strand 1999, i.a.). • Listeners who were trained on the front tsw- variant were more likely to label front affricated ts- stimuli as instances of t. Listeners who were trained on the retracted affricate tchw- were less likely to judge ts- as an instance of plain t (F(2,64)=5.9, p<0.005). • Front affricated stimuli were more likely to be labeled as t- for the female talker by both control and front-trained groups (F(2,64)=3.5, p<0.05) because listeners already assume a more front variant for women. • The perceptual space for t depends on whether the talker is perceived as male or female, greater at the front end for females, greater at the back end for males. • The shift in t, by association with the shift in tw- caused by perceptual learning, is chew too tsu chew too tsu • most apparent at the unbounded front edge, where both training groups show a shift in perception for the male talker. • The back is bounded by the tʃ phoneme for the male talker, while the front boundary (ts) is more flexible for both male and female talkers. • Perceptual range expands for front variant, contracts for back variant • Conclusions / Discussion • Training has strongest effect on acceptance rate for unfamiliar trained words, but generalizes to familiar untrained words. Familiar words with untrained variant are still readily accessible, regardless of variant. • Listeners are generalizing to new phonetic environments tu. Sound change and analogy, in the course of an hour. • Interactions with gender: the expected direction of variation in females (tsw-) creates less shift in that direction for the perceptual space for female talkers. The region of expected variation for male talkers is abutted by an existing phoneme (tʃ), so the shift is limited. • Interactions with gender (not shown): acceptance rates are lower across the board for male talkers, possibly because the tsw- variant runs counter to gender expectations, while the tchw- variant abuts a pre-existing phoneme. • Directions for future research: experiment 2 (results coming soon) explicitly addresses gender conditioning factors by attempting to condition a sound split • Ask me about exciting production data ! • References • Goldinger, S. D. 1998. Echoes of echoes? An episodic theory of lexical access. Psychological Review 105: 251-279. • Norris, Dennis, James McQueen & Anne Cutler. 2003. Perceptual learning in Speech. Cognitive Psychology 47(2): 204-238. • Strand, Elizabeth. 1999. Uncovering the role of gender stereotypes in speech perception. Journal of language and social psychology 18(1): 86-100. • Acknowledgments: • Thank you to Cynthia Clopper for all kinds of practical advice, from design to stats to presentation. Thank you to Brian Joseph for the inspiration to begin this project, and for your unwavering support, even when we disagree. Thank you to Amber Torelli, Theresa Lucius, and Stephen Birk, for assisting with data collection and challenging me to be a better mentor. And thank you to the following grad students who have sat in the stuffy sound booth, some of you for multiple sessions, to record stimuli for this monstrosity of an experiment: Sara Bourass, Katie Carmichael, Jon Dehdari, DJ Hovermale, Scott Martin, Laurie Maynell, Liz McCullough, Deborah Morton, Mike Phelan, Brice Russ, Kodi Weatherholtz, Chris Worth. Thank you to the OSU Department of Linguistics for supporting me despite my refusal to narrow my field of study, and for travel funding to make this poster possible. • Any goofiness in this project, or any other, is my own fault. • . means 0.981 0.944 0.964 0.917 0.986 0.950 0.800 0.580 0.733 0.660 0.617 0.640 0.878 0.793 0.825 0.810 0.825 0.880 2nd Workshop on Sound Change, May 2-4, 2012





















