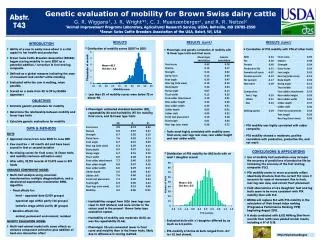
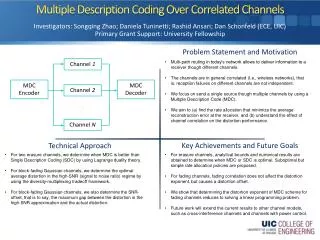
Download

1 / 24
240 likes | 280 Views
This research introduces an attribute-efficient algorithm for learning sparse monomials over highly correlated variables, offering both sample and runtime efficiency. The approach addresses the challenges of high correlation between features and the nonlinearity of monomials, achieving exact recovery using log-transformed data and a novel analysis based on restricted eigenvalue conditions. The algorithm’s efficacy is demonstrated through theoretical analysis and practical implications for sparse polynomial learning in correlated settings.

E N D
Attribute-Efficient Learning of Monomials over Highly-Correlated Variables Alexandr Andoni, Rishabh Dudeja, Daniel Hsu, Kiran Vodrahalli Columbia University Algorithmic Learning Theory 2019
Learning Sparse Monomials A Simple Nonlinear Function Class 3 dimensions In dimensions Ex: andsparse
The Learning Problem Given: , drawn i.i.d. Assumption 1: is a -sparse monomial function Assumption 2: Goal: Recover exactly
Attribute-Efficient Learning • Sample efficiency: • Runtime efficiency: ops • Goal: achieve both!
Motivation • Monomials Parity functions • No attribute-efficient algs![Helmbold+ ‘92, Blum’98, Klivans&Servedio’06, Kalai+’09, Kocaoglu+’14…] • Sparse linear regression[Candes+’04, Donoho+’04, Bickel+’09…] • Sparse sums of monomials[Andoni+’14] For uncorrelated features:
Motivation • Sparse linear regression[Candes+’04, Donoho+’04, Bickel+’09…] • Sparse polynomials[Andoni+’14] For uncorrelated features: Question: What if ? Monomials Parity functions No attribute-efficient algs![Helmbold+ ‘92, Blum’98, Klivans&Servedio’06, Kalai+’09, Kocaoglu+’14…]
Potential Degeneracy of Ex: Singular matrix canbelow-rank!
Rest of the Talk • Algorithm • Intuition • Analysis • Conclusion
The Algorithm Ex: Step Log-transformed Data Gaussian Data Step Sparse Regression: (Ex: Basis Pursuit) feature
Why is our Algorithm Attribute-Efficient? • Runtime: basis pursuit is efficient • Sample complexity? • Sparse linear regression? E.g., • But: sparse recovery properties may not hold…
Degenerate High Correlation Recall the example: -eigenvectors can be -sparse Sparse recovery conditions false! 3-sparse
Summary of Challenges • Highly correlated features • Nonlinearity of • Need a recovery condition…
Log-Transform affects Data Covariance “inflating the balloon” Spectral View: Destroys correlation structure
Restricted Eigenvalue Condition [Bickel, Ritov, & Tsybakov ‘09] Ex: Restricted Eigenvalue Cone restriction “restricted strong convexity” Note: Sufficient to prove exact recovery for basis pursuit!
Sample Complexity Analysis Concentration of Restricted Eigenvalue Population Transformed Eigenvalue - with probability with high probability Exact Recovery for Basis Pursuit with high probability
Sample Complexity Analysis Concentration of Restricted Eigenvalue Population Transformed Eigenvalue - with probability Sample Complexity Bound: with high probability Exact Recovery for Basis Pursuit with high probability
Population Minimum Eigenvalue • Hermite expansion of • off-diagonals decay fast! • Apply to Hermite formula: • Apply Gershgorin Circle Theorem: (for large enough )
Concentration of Restricted Eigenvalue • - • Log-transformed variables are sub-exponential • Elementwise error concentrates [Kuchibhotla & Chakrabortty ‘18]
Recap • Attribute-efficient algorithm for monomials • Prior (nonlinear) work: uncorrelated features • This work: allow highly correlated features • Works beyond multilinear monomials • Blessing of nonlinearity
Future Work • Rotations of product distributions • Additive noise • Sparse polynomials with correlated features Thanks! Questions?