Download

1 / 9
90 likes | 179 Views
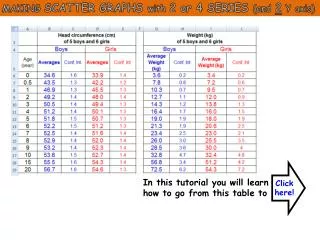
Explore information gain based on target heading angles relative to UAV. Analyze variance and Fisher information in various scenarios with Guassians. Compare results with Monte Carlo sampling.

E N D
The following slides show the information gain (y axis) vs. heading of the target relative to the UAV (x axis). Each graph shows the gain from a second measurement after an initial measurement is taken at varying angles listed on each slide. All measurements are taken at a constant range. Variance for heading and range are set at .00001 for all slides (roughly a standard deviation of .06 degrees in regard to heading) except slide 5 where variance is raised to .001
KL divergence info for single Guassian update vice Fisher info
Log of KL divergence again for single Guassian, note similarity to slide 2
Variational approximation to KL divergence using log of KL divergence internally for mixtures of 2 Guassians with means at <0 0 0 0 0 0> and <.01 .01 .01 .01 .01 .01>
Variational approximation to KL divergence using log of KL divergence internally for mixtures of 2 Guassians with means at <0 0 0 0 0 0> and <1 1 1 1 1 1>
Variational approximation to KL divergence using scaled KL divergence internally for mixtures of 2 Guassians with means at <0 0 0 0 0 0> and <.01 .01 .01 .01 .01 .01>
Variational approximation to KL divergence using scaled KL divergence internally for mixtures of 2 Guassians with means at <0 0 0 0 0 0> and <1 1 1 1 1 1>
Note that in all experiments with mixed Gaussians the information values decrease when the means of the two Gaussians are spaced further apart. To confirm that this behavior is acceptable a comparison against the monte carlo sampling (Dmc(f||g)) was performed.Dmc gave the following decreasing values with 0, 3, 6, but then increased at 6, 9, 12: >> kl_mc_sample ans = 0.9164 >> kl_mc_sample ans = 0.1949 >> kl_mc_sample ans = -0.1433 >> kl_mc_sample ans = 0.2514 >> kl_mc_sample ans = 1.3295 Values continued to increase after 12. At a mean difference of 100 the value had risen to 333. This seems a programming bug since the max value obtainable By either GMM is 1.