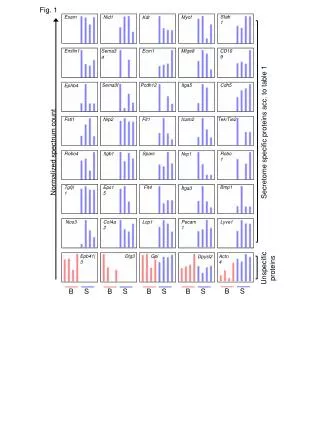
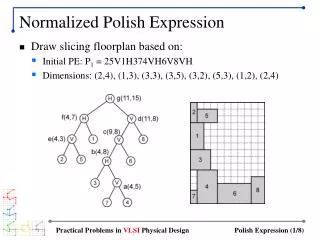
Normalized Discounted Cumulative Gain
Normalized Discounted Cumulative Gain. In more detail. NDCG. NDCG components Gain → Cumulated Gain → Discounted Cumulated Gain → Normalized Discounted Cumulated Gain. Cumulative Gain. DCG based on t wo assumptions 높은 Relevance 를 가진 문서들은 낮은 Relevance 를 가진 문서보다 가치가 높다


Normalized Discounted Cumulative Gain
E N D
Presentation Transcript
Normalized DiscountedCumulative Gain In more detail
NDCG • NDCG components • Gain → Cumulated Gain → Discounted Cumulated Gain → Normalized Discounted Cumulated Gain
Cumulative Gain • DCG based on two assumptions • 높은 Relevance를 가진 문서들은 낮은 Relevance를 가진 문서보다 가치가 높다 • 높은 Relevance의 문서들이 뒤쪽에 있다면, 정보이용자는 문서를 보지 못할 가능성이 높다 • Cumulative Gain • Predecessor of DCG • Sum of graded relevance of all results in a search result • Do not include rank information
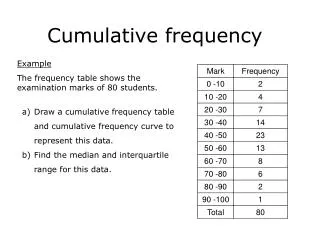
Cumulative Gain • 200개 문서의 relevance score를 0~3으로 한다면, (0: non-relevant ~ 3: highly relevant) Information Need에 대한 Gain은 다음과 같이 나타낼 수 있다. G’ = {3, 2, 3, 0, 0, 1, 2, 2, 3, 0, …} G’: gain • Cumulative gain은 Rank 1~i번까지 문서의 relevance score의 합 • CG[i] = G[1] if i=1 CG[i – 1] + G[i] otherwise • CG’ = {3, 5, 8, 8, 8, 9, 11, 13, 16, 16, …} CG’: cumulative gain ∴ CG’[7] = 11 Which is read as, at rank 7: cumulated gain is 11
Discount Cumulated Gain • Rank가 뒤쪽으로 갈 수록 정보이용자가 볼 가능성이 낮음 • 이를 근거로 Relevance score에 반영, 뒤쪽 Rank에 해당할수록 Cumulative Gain값이 낮아지도록 조정 • 너무 급격하게 값이 낮아지지 않는 log를 기반으로 함 (e.g. division by rank) • DCG[i] = CG[i] (if i < b) DCG[i – 1]+G[i]/logbi (if i≥ b) • log base보다 i가 작을 때는 logarithm discount를 적용 안 함 • base수가 클수록 discount rate가 작아지며, 다른 의미로 searcher들이 base rank까지는 문서를 찾아 볼 것이라는 현실적인 가정을 생각해볼 수 있음 • log base가 2일 때,rank 7에서의 DCG는 8.66 DCG’ = {3, 5, 6.89, 6.89, 7.28, 7.99, 8.66, 9.61, 9.61, …}
Discount Cumulated Gain • DCG[i] = CG[i] (if i < b) DCG[i – 1]+G[i]/logbi (if i≥ b) • Alternative formulation • 높은 Rank(=Result에서상위에 위치)의 문서들을 좀 더 강조
Normalized DCG • Search result의 길이는 query에 따라 다름 • IR system마다 query에 대한 응답이 다르기 때문에 DCG는 IR system간의 측정 기준이 될 수 없음 • DCG에서 어떤 rank position에서든 Ideal Performance의 측정이 1이 되도록 하는 것 • Relative to the Ideal Measure • DCG vector가 V={v1, v2, v3,.. vk} 이고 Ideal Gain Vector가 I={i1, i2, i3,… ik} 라고 하면 Normalized DCG(V,I) = {v1/i1, v2/i2,… vk/ik}
Ideal Gain Vector • 각각 k, l, m개의 문서가 Relevance level이 1, 2, 3이라고 가정한다(level range: 0~3, 3 is high) • 각 level의 문서마다 score를 매김 • 1…m까지의 score는 3 • m+1…m+l까지의 score는 2 • m+l+1…m+l+k까지의 score는 1이 된다. • Sample Ideal Vector I(for a query) • for k, l, m relevant documents at the relevance level 1~3 • I’ = { 3, 3, 3, 2, 2, 2, 1, 1, 1, 0, 0, 0,… } • Based on sample ideal gain vector I’, Ideal CG, DCG(b=2) also obtained • CG’I = { 3, 6, 9, 11, 13, 15, 16, 17, 18, 19, 19, 19, … } • DCG’I = { 3, 6, 7.89, 8.89, 9.75, 10.52, 10.88, 11.21, 11.53, 11.83, 11.83…}
Normalized DCG • nCG’ = norm-vect(CG’, I’) = {1, 0.83, 0.89, 0.73, 0.62, 0.6, 0.69, 0.76, 0.89, 0.84.. } • Normalized DCG vector와 Normalized Ideal DCG vector의 Area 차이는 시스템의 quality를 나타낸다 • NDCG는 AUC과 같이 IR 시스템 간 성능을 비교하는 데 쓰일 수 있다. • e.g. Average of an NDCG up to the position k
NDCG in Book • NDCG Definition shown in Book • In a query set Q, within top k results • Designed for situations of non-binary notions of relevance • Evaluated over some number k of top search results • R(j, d) is the relevance score, on document d for query j • Zk is normalization factor calculated to perfect ranking’s NDCG at k is 1 • Finally Results are averaged between queries in a query set Q
NDCG in Book • NDCG Example(for 1 query) • nDCG’6 = DCG’6/IDCG’6 = 7.99 / 10.52 = 0.7595


![Cumulative distribution [%]](https://cdn1.slideserve.com/2142714/slide1-dt.jpg)