Download

1 / 17
170 likes | 315 Views
Metadata Extraction @ ODU for DTIC. Presentation to Senior Management May 16, 2007 Kurt Maly, Steve Zeil, Mohammad Zubair {maly, zeil, zubair} @cs.odu.edu. Outline. Metadata Extraction Project System overview Demo Current status Why ODU

E N D
Metadata Extraction @ ODUforDTIC Presentation to Senior Management May 16, 2007 Kurt Maly, Steve Zeil, Mohammad Zubair {maly, zeil, zubair} @cs.odu.edu
Outline • Metadata Extraction Project • System overview • Demo • Current status • Why ODU • Research, new technology, Inexpensive, Maintenance (Department commitment) • Why DTIC as Lead • Amortize development cost, Expand template set (helpful in future too), Consistent with DTIC strategic mission • Required enhancements
Status • Completely Automated Software for: • Drop in pdf file • Process and produce output metadata in XML format • Easy (less than 5 minutes) installation process • Default set of templates for: • RDP containing documents • Non-form documents • Statistical models of DTIC collection(800,000 documents) and NASA collection (30,000 documents) • Phrase dictionaries: personal authors, corporate authors • Length and English word presence for title and abstract • Structure of dates, report numbers
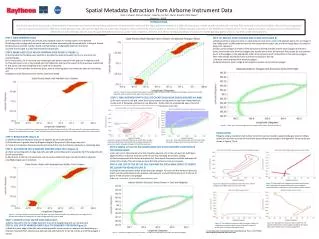
Status Metadata Extraction Results for 98 documents that were randomly selected from the DTIC Collection • * Notes • Accuracy is defined as successful completion of the extractor with reasonable metadata values extracted • “Reasonable” implies that values could be automatically processed (see required enhancements) into standard format • Accuracy for documents without RDP could be enhanced with additional templates, (see required enhancements)
Why - software from ODU • Research, new technology • ODU digital library research group is world class and has made many contributions to advancing field. $2.5M funding in last five years from various agencies National Science Foundation, Andrew Mellon Foundation, Los Alamos, Sandia National Laboratory, Air Force Research Laboratory, NASA Langley, DTIC, and IBM • State of art in automated metadata extraction is good for homogenous collection but not effective for large, evolving, heterogeneous collections (such as DTIC’s) • Need for new methods, techniques and processes
Why - software from ODU • Inexpensive (relatively) • ODU is university with low overhead (43%) • Universities can use students and pay them assistantships rather than fulltime salaries • Department adds matching tuition waivers for research assistants which is big incentives for students to apply for research work • Faculty are among best in field, require partial funding.
Why - software from ODU • Long term software maintenance through department • Department commits continuity independent of faculty on projects • Department will find and assign faculty and student who can become conversant with code and maintain it (not evolve it) • Likely that there would be other faculty who are interested in evolving code for appropriate funding
Why – DTIC as Lead Agency • Amortize Development Cost • We are working with NASA and plan to get on GPO board soon. NASA gave us partial funding to investigate the applicability of our approach for their collection.
Why – DTIC as Lead Agency • Cross Fertilization • DTIC has distinctive requirements that can benefit from enhancing the metadata extraction technology for other agencies (for example richer template set) • Heterogeneity: DTIC collects documents… • of many different types • from an unusually large number of sources • with minimal format restrictions • Evolution:DTIC collection spans time frame in which • submission formats change from typewritten to word processed, scanned to electronic • asserts minimal control over layouts & formats
Why – DTIC as Lead Agency • Consistent with DTIC Strategic Mission • DTIC is largest organization with most diverse collection and has stature to disseminate to other government agencies
Required Enhancements – Priority 1 • Enhance portability • Standardized output • Template creation (initial release), • Text PDF input • MS Word input
Required Enhancements – Priority 2 • PrimeOCR input • Multipage metadata • Template Creation (enhanced release) • Template Creation Tool
Required Enhancements – Priority 3 • Human intervention software
Time Line • May 2007 to September 2007 • Add flexibility to code • Enable the current product to produce standardized output • Create new templates that will cover the Larger Contributors • Investigate different approaches to handle text pdf documents and finalize the design?
Time Line • October 2007 to September 2008 • Validate the extraction according to the DTIC provided Cataloging document . • Module that would allow the functional user to create a new template that would easily integrate into the extraction software. • Create new templates that will cover the Larger Contributors of DTIC • Create a module that converts Prime OCR into IDM • Create the code necessary to enable the non-form documents to be able to extract the metadata from more than one single page • Implement the support for the text pdf as finalized in the first part • Implement support for Word documents • Create the code necessary to display the scoring on validation at the documents level (for workers) and collection level (managers)