Download

1 / 11
550 likes | 1.31k Views
Accuracy Assessment. Having produced a map with classification is only 50% of the work, we need to quantify how good the map is. This step is called the accuracy assessment, meaning we need to evaluate the classes with independent data. Depending on

E N D
Accuracy Assessment • Having produced a map with classification is only 50% of the work, we need • to quantify how good the map is. This step is called the accuracy assessment, • meaning we need to evaluate the classes with independent data. Depending on • the data you have or time and resources available, you may evaluate you map • with the following data. • An existing map that was produced by someone else with known accuracy • Air photos • Take your map in the field and compare with the real world. The data • collected in the field with regard to its category are called ground truth. • Of the three methods, the last one is the most reliable, but it is the most costly • and time consuming approach.
Step 1 Sampling Design: • Usually there are millions, if not infinite, of pixels in a map we make. It is impossible that we check each of the pixels in the field. Rather we only check a small representative portion of the pixels on the ground. Then how do we choose the small representative portion of the pixel to check? • Simple Random Sampling: equal change in selecting sample units. But sometimes not two sites may be right next to each other. • Systematic Sampling: sample units picked over equal interval. Samples are uniformly distributed throughout study area. • Stratified Random Sampling: To ensure small classes has appropriate representative samples • Sample size: Standard size is 50 sites per class. • Adjust sample size according to importance and class size.
Step 2. Sampling Unit Minimum map unit. We cannot assess accuracy of maps with 1x1 km pixel size using 30x30 m pixels. 1. Single pixel: Not often used, don’t necessarily relate to landscape features. due to mixture pixels. Hard to locate in the field, even with GPS. Suffer from misregistration the greatest. 2. Cluster of pixels (e.g. 2x2, 3x3): Most commonly used. Reduces registration problems, reduce confusion from mixture pixels. Larger, easier to locate in the field. 3. Multi-pixel region (e.g. a forest stand polygon) Rarely used Minimizes registration problems Usually adopted for special applications, such as wildlife management unit.
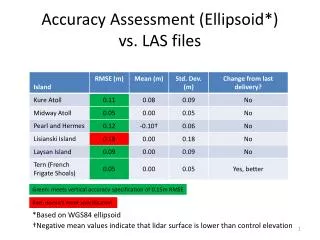
Step 3. Produce Classification Error Matrix The classification error matrix, also called the confusion matrix or contingency table, is the core to accuracy assessment. Here is an example error matrix Reference data W S F U C H row total Classified W 226 0 0 12 0 1 239 S 0 216 0 92 1 0 309 F 3 0 360 228 3 5 599 U 2 108 2 397 8 4 521 C 1 4 48 132 190 78 453 H 1 0 19 84 36 219 359 Column total 233 328 429 945 238 307 2480 W:water, S: sand, F: forest, U: urban, C: corn, H: hay
Map Accuracies Producer’s accuracy: the percentage of pixels in the reference data for a certain class that are correctly identified by the classifier. User’s Accuracy: the percentage of pixels classified as a certain class that agrees with the reference data Overall accuracy: the percentage of the total pixels that are correctly identified. Producer’s Accuracy W=226/233=97% S=216/328=66% F=360/429=84% U=397/945=42% C=190/238=80% H=219/307=71% User’s Accuracy W=226/239=94% S=216/309=70% F=360/599=60% U=397/521=76% C=190/453=42% H=219/359=61% Overall Accuracy=(226+216+360+397+190+219)/2480=65%
Omission and Commission Errors Omission error for a class is the percentage of pixels that belongs to a class in the reference data, but classified to something else (omitted). Commission error for a class is the percentage of pixels that is classified as the class, but belong to other classes in reference data. Commission Errors W=13/239=6% S=93/309=30% F=239/599=40% U=124/521=24% C=263/453=58% H=180/359=39% Omission Errors W=7/233=3% S=112/328=34% F=79/429=16% U=548/945=58% C=48/238=20% H=88/307=29% Omission Errors: 58% of the urban is identified as something else Commission errors: 24% of the classified urban are not urban
K_hat Statistics If we close our eyes and randomly assign the pixels to the classes, we still would have some of them put in the correct class. K_hat statistic is a measure of difference between the map accuracy the accuracy and random assignment. K_hat is a numerical measure of the extent to which the percentage correct values of an error matrix are due to “true” agreement versus “chance” agreement. K_hat varies between 0 and 1. 0 means the classification is no better than random classification, and 1 means true agreement. For example, K_hat=0.67 means that the classification is 67% better than randomly assign the pixels to the classes. It is common practice for any classification work that the overall accuracy and the K-hat value are given simultaneously.
K-hat Computation Where: N=total number of samples r= number of classes xii= diagonal values in the matrix x i+ =total samples in row i x+i=total samples in column i
Limitations of Traditional Accuracy Assessment (Gopal and Woodcock, 1994, PE&RS) • It is assumed that each area in the map can be unambiguously assigned to a single map category. The expert assign a single category from each ground location and match this with the map value. • Information on the magnitude of errors is limited to noting the pattern of mismatches between the categories in the map. The magnitude and the seriousness of these mismatches as indicated by the conditions of the ground site cannot be used. • The users need to be provided with more complete and interpretable information about he map than is currently practiced. Detailed information on errors will help the used to check if the map can be used for a particular purpose.
Accuracy Assessment Based on Fuzzy Sets Pixel class memberships are not always as clear as black and white. For example, a pixel may be a mixture of grass and a forest, calling it either one is not wrong completely. Accuracy is constructed on a linguistic scale: Absolutely wrong: the answer is absolutely unacceptable, very wrong. Understandable but wrong: Not a good answer. There is something at the site make the answer understandable, but there is clearly a better answer. This answer would pose a problem to the users of the map. Reasonable or acceptable answer: Maybe not the best possible answer, but it is acceptable, and this answer does not pose a problem to the users of the map. Good answer: Would be happy to find this answer given on the map. Absolutely Right: No doubt about the match.
Problems to Accuracy Assessment • Mis-registration • Ground truthing can only be applicable to small areas. • Error in reference data, particularly for reference data at continental or global scale the error in reference data may exceed that from remotely sensed data. • No spatial distribution of errors is available from confusion matrix. Often errors are not randomly distributed across an image. • Importance of error for classes is different