A Web-Based Data Mining Application for the Contraceptive Method Choice Database
A Web-Based Data Mining Application for the Contraceptive Method Choice Database. Kerey Carter Presented To: Dr. Donald Kraft (Chair) Dr. John Tyler Dr. Bert Boyce. Outline. Introduction Technical Description Data Mining Algorithms System Layout Demo / Results Conclusion.


A Web-Based Data Mining Application for the Contraceptive Method Choice Database
E N D
Presentation Transcript
A Web-Based Data Mining Application for the Contraceptive Method Choice Database Kerey Carter Presented To: Dr. Donald Kraft (Chair) Dr. John Tyler Dr. Bert Boyce
Outline • Introduction • Technical Description • Data Mining Algorithms • System Layout • Demo / Results • Conclusion
Introduction - Overview • Statement of Problem:According to (United Nations Population Fund), the progress in the contraceptive prevalence rate (CPR) for Indonesia seems to have stalled at about 57 percent.A critical challenge for Indonesia remains the access to affordable contraceptives by all its citizens, especially the poor. • Solution: Use data mining techniques to predict the current contraceptive method choice (no use, long-term methods, or short-term methods) of an Indonesian woman based on her demographic and socio-economic characteristics. Predicting the contraceptive method choice of Indonesian women can assist the government with how and where to target and provide information on contraceptive choices for its female population.
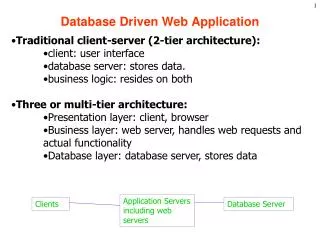
Introduction – Project Description • Architecture Used: Web-based 3-Tier Client/Server • Features: Administrator and User Data Manipulation options; Access Logs • Data Mining Algorithms used for Prediction: • Naive Bayesian Classification • One-Rule Classification • Decision Tree
Introduction – The Dataset • This dataset comes via a subset of the 1987 National Indonesia Contraceptive Prevalence Survey. It was created and donated by Tjen-Sien Lim on June 7, 1997. The contents were downloaded from the UCI Machine Learning Depository • The samples contained in the survey are of married women who were either not pregnant or did not know if they were pregnant at the time of the interview. • The number of instances is 1473, and the number of attributes is 11, including the primary key (ID) and the classifying attribute (cmchoice)
Introduction – Website Design • Administrator Privileges: • Add, Delete, Edit, and Search Records • Add Users, Change Admin Password • User Privileges: • Add Records, Search Records • Dual Access: • Access Logs, Data Mining Results
Technical Description – Three-Tier Model • Three-Tier Client/Server Architecture • Increases scalability and reliability by separating the three major logical functions of an application (user interaction, business logic, data storage) from one another. Is easier to maintain and can utilize same business logic for multiple interfaces, vs. client/server • Client Side Front-End: Web browser (I.E.) / HTML • Middle-Tier: CGI, Perl, ASP, VBScript • Server Side Back-End: Access, CSV Text File
Technical Description – Middle Tier • Common Gateway Interface (CGI) • A standard for interfacing external applications with information servers, such as HTTP or Web servers • A CGI program is executed in real-time, which means that it can output dynamic data to a Web page. • Allows visitors to a Web page to run a program on the server where the CGI document is hosted • CGI programs must reside in a special directory, so that the Web server knows to execute the program instead of merely displaying it to the browser. • Ex. /cgi-bin
Technical Description – Middle Tier • Practical Extraction Report Language (Perl) • Language used in writing many CGI programs • Combines many features of C, sed, awk, and sh, as well as csh, Pascal, and BASIC-PLUS • Available for most operating systems, including virtually all Unix-like platforms • Optimized for scanning arbitrary text files, extracting information from those text files, and printing reports based on that information • Does not arbitrarily limit the size of the user’s data, as long as the required memory is available
Technical Description – Middle Tier • Active Server Pages (ASP) • Components that allow Web developers to create server-side scripted templates • Templates generate dynamic, interactive web server applications • HTML output by an Active Server Page is browser independent • Visual Basic Script (VBScript) • Scripting language based on the Visual Basic programming language used to create ASP Web pages
What is Data Mining? • Data mining is the exploration and analysis, by automatic or semiautomatic means, of large quantities of data in order to discover meaningful patterns and rules (Berry, Linoff, pg. 5) • It is a process of taking data and analyzing, interpreting, and transforming it into useful information. Data mining can be used to make predictions after data has been transformed.
Data Mining Algorithms • Naive Bayesian Classification • Bayes Theorem illustrates how to calculate the probability of one event given that it is known some other event has occurred, expressed algebraically as: P(A|B) = P(A) * P(B|A) / P(B) Or, The probability that A takes place given that B has occurred (P(A|B)) equals the probability that A occurs (P(A)) times the probability that B occurs if A has happened (P(B|A)), divided by the probability of B occurring (P(B))
Data Mining Algorithms • Bayesian Network - consists of nodes and arcs that can connect pairs of nodes. For each variable, exactly one node exists. A major restriction for the Bayesian network is that arcs are not allowed to form loops. • NOT a Bayesian network:
Data Mining Algorithms • Bayesian network dependency model example: • A and B are dependent on each other if we know something about C or D (or both). • A and C are dependent on each other no matter what we know and what we don't know about B or D (or both). • B and C are dependent on each other no matter what we know and what we don't know about A or D (or both). • C and D are dependent on each other no matter what we know and what we don't know about A or B (or both) • There are no other dependencies that do not follow from those listed above.
Data Mining Algorithms • One-Rule Classification • Creates one data mining rule for the dataset based on one attribute (one column in a database table). • After comparing the error rates from all the attributes, the rule is chosen that gives the lowest classification error. • The rule will assign to one category or class each distinct value of one chosen attribute
Data Mining Algorithms • Pseudocode for One-Rule Classification: • For each attribute in the data set • For each distinct value of the attribute • Find the most frequent classification • Assign the classification to the value • Calculate the error rate for the value • Calculate the total error rate for the attribute • Choose the attribute with the lowest error rate
Data Mining Algorithms • Decision Tree: • (1) Begins by finding the test that performs the best task of splitting the data among the preferred categories • (2) At each successive level of the tree, subsets created by the previous split are themselves split, making a path down the tree • (3) Each of the paths through the tree represents a rule, and some rules are more useful than other ones
Data Mining Algorithms • Decision Tree (cont.) • (4) At each node of the tree, three things can be measured: the number of records entering the node, the percentage of records classified correctly at the node, and the way the records would be classified if it were a leaf node. • (5) The tree continues to grow until it is no longer possible to locate more useful ways to split the incoming records
Conclusion • All 3 data mining algorithms were successful at making predictions of the contraceptive method choice. • Naive Bayesian - the estimated classification accuracy of the best model found was 48.74% • One Rule - determined that the no_child attribute was the best predictor of the contraceptive method choice • Decision Tree - • determined that the best predictor of the contraceptive method choice was the rule where no_child <=0, which would predict the no use category (95.7%) • The regular decision tree had an error rate of 25.0%, while the decision tree with fuzzy thresholds had an error rate of 25.5%