Load Balancing
Load Balancing. Definition : A load is balanced if no processes are idle. How? Partition the computation into units of work (tasks or jobs) Assign tasks to different processors Load Balancing Categories Static (load assigned before application runs)


Load Balancing
E N D
Presentation Transcript
Load Balancing Definition: A load is balanced if no processes are idle • How? • Partition the computation into units of work (tasks or jobs) • Assign tasks to different processors • Load Balancing Categories • Static (load assigned before application runs) • Dynamic (load assigned as applications run) • Centralized (Tasks assigned by the master or root process) • De-centralized (Tasks reassigned among slaves) • Semi-dynamic (application periodically suspended and load balanced) • Load Balancing Algorithms are: • Adaptive if they adapt to system load levels using thresholds • Stable if load balancing traffic is independent of load levels • Symmetric if both senders and receivers initiate action • Effective if load balancing overhead is minimal Note: Load balancing is an NP-Complete problem
Improving the Load Balance By realigning processing work, we improve speed-up
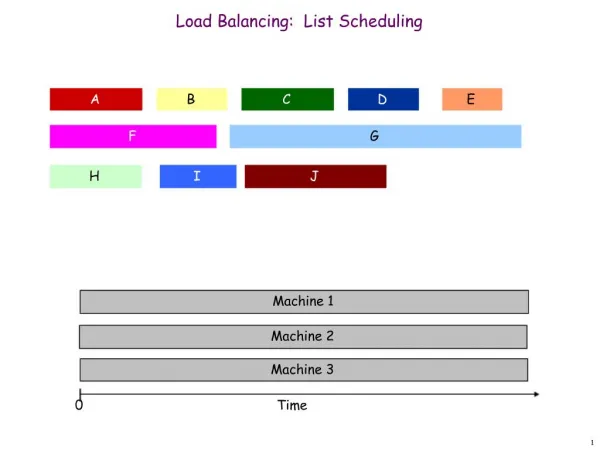
Round Robin Tasks assigned sequentially to processors If tasks > processors, the allocation wraps around Randomized: Tasks are assigned randomly to processors Partitioning – Tasks are represented by a graph Recursive Bisection Simulated Annealing Genetic Algorithms Multi-level Contraction and Refinement Advantages Simple to implement Minimal run time overhead Disadvantages Predicting execution times is often not knowable Affect of communication dynamics is often ignored The number of iterations required by processors to converge on a solution is often indeterminate Static Load Balancing Done prior to executing the parallel application Note: The Random algorithm is a popular benchmark for comparison
A Load Balancing Partitioning Graph • The Nodes represent tasks • The Edges represent communication cost • The Node values represent processing cost • A second node value could represent reassignment cost
Simulated Annealing • Overview • A heuristic used to address many NP-Complete problems, which is more efficient than exhaustively searching graphs • Metallurgy: heating and cooling causes some atoms to temporarily randomly move through higher energy states; settling in a more stable state • Algorithm WHILE balance is not good enough FOR each node in the graph Compute its energy (computation/communication requirements) IF probabilistic calculation indicates that node should move Pick a set of neighbors assigned to other processors FOR each neighbor in the set Compute impact of reassigning the node Move the node to the best neighbor partition
Simplifying the Problem Recursive Bisection Multi-level Approaches Overview: Similar to Recursive Bisection, but refines the approach Contraction phase shrinks the graph, Refinement phase restores it to its original size Algorithm WHILE graph is too large Find bisection point and contract the graph WHILE graph is smaller contracted, refine the graph, and reassign nodes if improvements are possible • Overview: Dividing the graph in two is an easier problem than tackling the entire problem • Algorithm IF graph is too large • Split the graph in two, minimizing computation and communication requirements • Color each side • Recursively continue splitting
Dynamic Load Balancing Done as a parallel application executes • Centralized • A single process hands out tasks • Processes ask for more work when their processing completes • Double buffering (ask for more while still working) can be effective • Decentralized • Processes detect that their work load is low • Processes sense an overload condition • When new tasks are spawned during execution • When a sudden increase in task load occurs • Questions • Which neighbors should participate in the rebalancing? • How should the adaptive thresholds be set? • What are the communications needed to balance? • How often should balancing occur?
Centralized Load Balancing Work Pool, Processer Farm, or Replicated Worker Algorithm Master Processor: Maintains the work pool (queue, heap, etc.) While ( task=Remove()) != null) Receive(pi, request_msg) Send(pi, task) While(more processes) Receive(pi, request_msg) Send(pi, termination_msg) Slave Processor: Perform task and then ask for another task = Receive(pmaster, message) While (task!=terminate) Process task Send(pmaster, request_msg) task = Receive(pmaster, message) Master Slaves In this case, the slaves do not spawn new tasks How would the pseudo code change if they did?
Centralized Termination How do we terminate when slave processes spawn new tasks? Necessary Requirements • The task queue is empty • Every process is waiting for a new task Master Processor WHILE (true) Receive(pi, msg) IF msg contains a new task Add the new task to the task queue ELSE Add pi to wait queue and waitCount++ IF waitCount>0 and task queue not empty Remove pi & task respectively from wait & task queue Send(task, pi) and waitCount—- IF waitCount==P THEN send termination messages & exit
Decentralized Load Balancing (Worker processes interact among themselves) • There is no Master Processor • Each Processor maintains a work queue • Processors interact with neighbors to request and distribute tasks
Balancing Algorithm Application Decentralized Mechanisms Balancing is among a subset of the total running processes • Receiver Initiated • Process requests tasks when it is about to go idle • Effective when the load is heavy • Unstable when the load is light (A request frequency threshold is necessary) • Sender Initiated • Process with a heavy load distributes the excess • Effective when the load is heavy • Can cause thrashing when loads are heavy (synchronizing system load with neighbors is necessary) Task Queue
Process Selection • Global or Local? • Global involves all of the processors of the network • May require expensive global synchronization • May be difficult if the load dynamic is rapidly changing • Local involves only neighbor processes • Overall load may not be balanced • Easier to manage and less overhead than the global approach • Neighbor selection algorithms • Random: randomly choose another process • Easy to implement and studies show reasonable results • Round Robin: Select among neighbors using modular arithmetic • Easy to implement. Results similar to random selection • Adaptive Contracting: Issue bids to neighbors; best bid wins • Handshake between neighbors needed • It is possible to synchronize loads
Choosing Thresholds • How do we estimate system load? • Synchronization averages task queue length or processes • Average number of tasks or projected execution time • When is the load low? • When a process is about to go idle • Goal: prevent idleness, not achieve perfect balance • A low threshold constant is sufficient • When is the load high? • When some processes have many tasks and others are idle • Goal: prevent thrashing • Synchronization among processors is necessary • An exponentially growing threshold works well • What is the job request frequency? • Goal: minimize load balancing overhead
L 1 2 1 1 2 2 2 2 Gradient Algorithm Maintains a global pressure grid • Node Data Structures • For each neighbor • Distance, in hops, to the nearest lightly-loaded process • A load status flag indicating if the current processor is lightly-loaded, or normal • Routing • Spawned jobs go to the nearest lightly-loaded process • Local Synchronization • Node status changes are multicast to its neighbors
Symmetric Broadcast Networks (SBN) Stage 3 5 Global Synchronization Stage 2 1 • Characteristics • A unique SBN starts at each node • Each SBN is lg P deep • Simple operations algebraically compute successors • Easily adapts to the hypercube • Algorithm • Starts with a lightly loaded process • Phase 1: SBN Broadcast • Phase 2: Gather task queue lengths • Load is balanced during the load and gather phases Stage 1 3 7 Stage 0 4 2 0 6 Successor 1 = (p+2s-1)%P; 1≤s≤3Successor 2 = (p-2s-1); 1≤s<3Note: If successor 2<0 successor2 +=P
Hypercube Based SBN Four Dimension Hypercube SBN Hypercube Spanning Tree • Stage = number of bits set • Successors: exclusive or with zero bits to the left, or if none with the first leftmost unset bit • Single hop required between adjacent nodes • Load balance requires 2 lg(P) communications
Find Successor Ranks for (int rank=0; rank<P-1; rank++) { int stage = 0, n = rank; // Compute the number of bits set while (n!=0) { n = n & (n-1); stage++; } System.out.printf("Successors rank %d stage %d = ", rank, stage); if (rank>=P/2) // No unset bits to the left { mask = (1<<(dimension-stage))-1; successor = ((rank & ~mask)>>1) | rank; System.out.println(successor); } else // Successors are all ranks with unset bits to the left { for (int bit = 1<<(dimension-1); bit>rank; bit/=2) { successor = rank | bit; System.out.print(successor + " "); } System.out.println(); } } }
SBN PatternRank 0 Successors rank 0 stage 0 = 8 4 2 1 Successors rank 1 stage 1 = 9 5 3 Successors rank 2 stage 1 = 10 6 Successors rank 3 stage 2 = 11 7 Successors rank 4 stage 1 = 12 Successors rank 5 stage 2 = 13 Successors rank 6 stage 2 = 14 Successors rank 7 stage 3 = 15 Successors rank 8 stage 1 = 12 Successors rank 9 stage 2 = 13 Successors rank 10 stage 2 = 14 Successors rank 11 stage 3 = 15 Successors rank 12 stage 2 = 14 Successors rank 13 stage 3 = 15 Successors rank 14 stage 3 = 15 • For other ranks, simply exclusive or the desired source rank with the above pattern • For example: Consider the source rank of 5 • The stage 2 processors are 3^5 (6), 5^5 (0), 6^5 (3), 9^5 (12), 10^5 (15), and 12^5 (9) • The successors to 3^5 (6) are 11^5 (14) and 7^5 (2)
pi pi+1 requests task Request task if queue not full Receive task from request Deliver task to pi+1 Dequeue and process task Line BalancingAlgorithm • Master or slave processors adjust pipeline • Slave processors • Request and receives tasks if queue not full • Pass tasks on if task request is posted • Non blocking receives are necessary to implement this algorithm Uses a pipeline approach Note: This algorithm easily extends to a tree topology
Semi-dynamic • Pseudo code Run algorithm Time to check balance? Suspend application IF load is balanced, resume application Re-partition the load Distribute data structures among processors Resume execution • Partitioning • Model application execution by a partitioning graph • Partitioning is an NP-Complete problem • Goals: Balance processing and minimize communication and relocation costs • Partitioning Heuristics • Recursive Bisection, Simulated Annealing, Multi-level, MinEx
P9R6 P6R6 c4 c6 P2R1 c3 P1 c5 P2 c2 P4R1 P4R4 c3 c1 P7R5 P5R3 c1 P8R3 c8 c7 P2R1 Partitioning Graph P1 Load = (9+4+7+2) + (4+3+1+7) = 37 P2 Load = (6+2+4+8+5) + (4+3+1+7) = 40 Question: When can we move a task to improve load balance?
Distributed Termination • Insufficient condition for distributed termination • Empty task queues at every process • Sufficient condition for distributed termination requires • All local termination conditions satisfied • No messages in transit that could restart an inactive process • Termination algorithms • Acknowledgment • Ring • Tree • Fixed energy distribution
Acknowledge first task First task Inactive Active Acknowledgement Termination Pi • Process Receives task • Immediately acknowledge if source is not parent • Acknowledge parent as process goes idle • Process goes idle after it • completes processing local tasks • Sends all acknowledgments • Receives all pending acknowledgments • Notes • The process sending an initial task that activates another process becomes that process's parent • A process always goes inactive before its parent • If the master goes inactive, termination occurs Pj
Single Pass Ring Termination • Pseudo code P0 sends a token to P1 when it goes idle Pi receives token IF Pi is idle it passes token to Pi+1 ELSE Pi sends token to Pi+1 when it goes idle P0receives token Broadcast final termination message • Assumptions • Processes cannot reactivate after going idle • Processes cannot pass new tasks to an idle process Token P0 P1 P2 Pn
Dual Pass Ring Termination Handles task sent to a process that already passed the token on Key Point: Processors pass either Black or White tokens on only if they are idle Pseudo code (Only idle processors send tokens) WHEN P0 goes idle and has token, itsends white token to p1 IF Pi sends a task to pj where j<i Pi becomes a black process WHEN Pi>0 receives token and goes idle IF Pi is a black process Pi colors the token black, Pi becomes White ELSE Pi sends token to p(i+1)%P unchanged in color IF P0 receives token and is idle IF token is White, application terminates ELSE po sends a White token to P1 Process: white=ready for termination, black: sent a task to Pj-x Token: white=ready for termination, black=communication possible
AND Terminated Leaf Nodes Tree Termination • If a Leaf process terminates, it sends a token to it’s parent process • Internal nodes send tokens to their parent when all of their child processes terminate • If the root node receives the token, the application can terminate
Fixed Energy Termination Energy defined by an integer or long value • P0 starts with full energy • When Pi receives a task, it also receives an energy allocation • When Pi spawns tasks, it assigns them to processors with additional energy allocations within its allocation • When a process completes it returns its energy allotment • The application terminates when the master becomes idle • Implementation • Problem: Integer division eventually becomes zero • Solution: • Use two level energy allocation <generation, energy> • The generation increases each time energy value goes to zero
Example: Shortest Path Problem Definitions Graph: Collection of nodes (vertices) and edges Directed Graph: Edge can be traversed in only one direction Weighted Graph: Edges have weights that define cost Shortest Path Problem: Find the path from one node to another in a weighted graph that has the smallest accumulated weights Applications • Shortest distance between points on a map • Quickest travel route • Least expensive flight path • Network routing • Efficient manufacturing design
F 17 9 E D 51 24 13 14 8 10 B C A A Climbing a Mountain B C D • Weights: expended effort • Directed graph • Effort in one direction ≠ effort in another direction • Ex: Downhill versus uphill E F Adjacency List Graphic Representation Adjacency Matrix
di wi,j i j dj Moore’s Algorithm Less efficient than Dijkstra but more easily parallelized • Assume • w[i][j] = weight of edge (i,j) • Dist[v] = distance to vertex v • Pred[v] = predecessor to vertex v • Pseudo code Insert the source vertex into a queue For each vertex, v, dist[v]=∞ infinity, dist[0] = 0 WHILE (v = dequeue() exists) FOR (j=; j<n; j++) newdist = dist[i] + w[i][j] IF (newdist < dist[j]) dist[j] = newdist pred[j] = I append(j) dj=min(dj,di+wi,j)
Centralized Work Pool Solution • The Master maintains • The work pool queue of unchecked vertices • The distance array • Every slave holds: The graph weights which is static • The Slaves • Request a vertex • Compute new minimums • Send updated distance values and vertex to master • The Master • Appends received vertices to its work queue • Sends new vertex and the updated distance array.
Distributed Work Pool Solution • Data held in each processor • The graph weights • The distances to vertices stored locally • The processor assignments • When a process receiving a distance: • If its local value is reduced • Updates its local value of dist[v] • Send distances to adjacent vertices to appropriate processors • Notes • The load can be very imbalanced • One of the termination algorithms is necessary