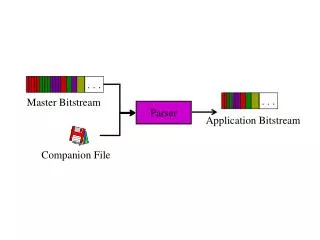
Building deep dependency structures with a wide-coverage CCG parser
This paper presents a novel statistical parser that leverages Combinatory Categorial Grammar (CCG) to derive dependency structures effectively. Unlike traditional tree-bank parsers, this approach captures long-range dependencies through a specialized grammar and probability model. The parser is trained and tested using dependency structures derived from a CCG-normal-form treebank, enhancing its ability to recover unbounded dependencies while managing spurious ambiguity. The paper details the grammar framework, estimation techniques for dependency probabilities, parser design, experimental setup, and results, concluding with directions for further work in this area.


Building deep dependency structures with a wide-coverage CCG parser
E N D
Presentation Transcript
Building deep dependency structures with a wide-coverage CCG parser Stephen Clark ACL2002 발표자 : 박 경 미
목차 • abstract • 1 introduction • 2 the grammar • 3 the probability model • 3.1 estimating the dependency probabilities • 4 the parser • 5 experiments • 6 results • 7 conclusions and further work
abstract • To derive dependency structures • Describes a wide-coverage statistical parser that uses Combinatory Categorial Grammar (CCG) • In capturing the long-range dependencies • A CCG parser differs from most existing wide-coverage tree-bank parsers • A set of dependency structures used for training and testing the parser • Is obtained from a treebank of CCG normal-form • Have been derived (semi-) automatically from the Penn Treebank
1. introduction • Models based on lexical dependencies • The dependencies are typically derived from a context-free phrase structure tree • Using simple head percolation heuristics • Does not work well for the long-range dependencies • CCG • “mildly context-sensitive” formalism • Provides the most linguistically satisfactory account of the dependencies • Is to facilitate recovery of unbounded dependencies
1. introduction • CCG is unlike other formalisms • In that the standard predicate-argument relations can be derived via non-standard surface derivations • Non-standard surface derivations • impacts on how best to define a probability model for CCG • the “spurious ambiguity” of CCG derivations may lead to an exponential number of derivations • Some of the spurious derivations may not be present in the training data • One solution • is to consider only the normal-form derivation
1. introduction • Another problem with the non-standard surface derivations • Is that the standard PARSEVAL performance measures over such derivations are uninformative • Lin(1995) and Carroll et al.(1998) • Propose recovery of head-dependencies characterising predicate-argument relations as a meaningful measure • The training and testing material for CCG parser • Is a treebank of dependency structures • Have been derived from a set of CCG derivations developed for use with another (normal-form) CCG parse
2 the grammar • 결합 범주 문법(어휘 사전, 구문 범주 형태) • identify a lexical item as either a functor or argument • For the functors • The category specifies the type and directionality of the arguments and the type of the result • Ex) the category for the transitive verb bought • The slash determines that the argument is respectively to the right (/) or to the left (\) of the functor • Its first argument as a noun phrase (NP) to its right • Its second argument as an NP to its left • Its result as a sentence
2 the grammar • Extend CCG categories • To express category features, and head-word and dependency information • The feasure [dcl] specifies the category’s S result as a declarative sentence • bought identifies its head • The numbers denote dependency relations
2 the grammar • Using a small set of typed combinatory rules • Derivation • Underlines indicating combinatory reduction • Arrows indicating the direction of the application • X/Y Y : X/Y가 뒤의 Y와 결합하여 X가 된다. (순행 연산) • Y X/Y : X/Y가 앞의 Y와 결합하여 X가 된다. (역행 연산)
2 the grammar • A dependency is defined as a 4-tuple: <hf, f, s, ha> • hf is the head word of the functor • f is the functor category • s is the argument slot • ha is the head word of the argument • Ex) the object dependency yielded by the first step of (3)
2 the grammar • Variables • Be used to denote heads • Be used via unifications to pass head information from one category to another • Ex) the expanded category for the control verb persuade • Ex) I persuaded him to go to the party • The head of the infinitival complement’s subject • Is identified with the head of the object • Unification “passes” the head of the object to the subject of the infinitival
2 the grammar • Raising • A syntactic process by which a NP or other element is moved from a SC into the structure of the larger clause • Ex) I believe [him to be honest] → I believe him [to be honest] • The kinds of lexical items that use the head passing mechanism • Are raising, auxiliary and control verbs, modifiers, and relative pronouns • The relative pronoun category • Show how heads are co-indexed for object-extraction
2 the grammar • Type-rasing (T) and functional composition (B), along with co-indexing of heads • Mediate transmission of the head of the NP the company onto the object of buy
2 the grammar • With the convention that arcs point away from arguments • The relevant argument slot in the functor category labels the arcs • Encode the subject argument of the to category as a dependency relation (Marks is a “subject” of to) • To encode every argument as a dependency
3.1 estimating the dependency probabilities • W is the set of words in the data • C is the set of lexical categories
4 The parser • Parser는 2가지 단계에서 문장을 분석 • 1. 문장의 각 단어에 category 할당 • supertagger(Clark, 2002) : category 확률이 constant factor β안에 있는 모든 category 할당 • 문장에 대해 여러가지 category sequence가 가능 • Parser에 의해 return될 category sequence는 확률 모델에 의해 결정됨 • Supertagger의 2가지 역할 • 1. parser의 search space 줄여줌 • 2. Category sequence model 제공
4 The parser • Supertagger는 “category dictionary”참조 • data에서 관찰된 category 집합을 각 단어마다 가짐 • 2. CKY bottom-up chart-parsing algorithm 적용 • Parser가 사용한 결합 규칙, 대등 규칙 • Type-raising, generalised forward composition…… • Type-raising : category NP, PP, S[adj]\NP(형용사구)에 적용됨 • NP, PP, S[adj]\NP가 발견되면 chart에 미리 정의된 type-raised category 추가 • type-raised category 집합은 CCGbank section 02-21의 빈번하게 발생한 type-raising rule에 기반함 • 8 type-raised categories for NP • 2 categories each for PP and S[adj]\NP
4 The parser • Parser는 또한 lexical rule 사용 • CCGbank section 02-21에서 200번 이상 발생한 것들 • Ex) ing형태의 동사구로부터 명사를 수식하는 어구 만들기 • Comma에 관한 규칙도 사용 • Ex) comma를 conjunct로 다룸 • John likes apples, bananas and pears • NP object가 3가지 head를 가짐, 모두 like의 직접 목적어 • Parser의 search space와 통계 모델 • If there is not already a constituent with the same head word, same category, and some DS with a higher of equal score • If the score for its dependency structure is within some factor α • A constituent is only placed in a chart cell
5 experiments • 말뭉치 • Training : section 02-21 of the CCGbank (39,161) • Development : section 00 (1,901) • Testing : section 23 (2,379) • Category set : section 02-21 (10번 이상, 398) • Estimating the probabilities • P(C|S)의 estimate : CCGbank로부터 직접 획득 • To obtain dependencies for estimating P(D|C,S) • Tree에 대해 derivation동안 적용된 결합 규칙들을 찾고 dependency를 출력 • Increased the coverage on sec23 to 99%(2,352) • By identifying the cause of the parse failures and adding the additional rules and categories
5 experiments • Initial parser • β=0.01 for the supertagger (an average of 3.8 c/w) • K=20 for the category dictionary • α=0.001 for the parser • 2,098 of the 2,352 sentences • received analysis, with 206 timing out and 48 failing • If any sentence took longer than 2 CPU minutes to parse • 48 no-analysis case : K=100 증가, 23문장 분석 • 206 time-out case : β=0.05 증가, 181문장 분석 • With 18 failing to parse, and 7 timing out • Almost 98% of the 2,352 unseen sentences
6 results • To measure the performance of the parser • Compared the dependencies output by the parser with those in the gold standard • The category set distinguishes around 400 distinct types • Ex) tensed transitive buy is treated as a distinct category from infinitival transitive buy • More stringent (Penn Treebank 약 50개 품사 태그) • “distance measure” (Δ) : less useful • The CCG grammar provides many of the constraints given by Δ, and d.m. are biased against long-range dependencies
6 results • 다른 parser와의 비교 어렵다 • Different data or different sets of dependencies • The 24 cases of extracted objects in the gold-standard • that were passed down the object relative pronoun category • 10 (41.7%) were recovered correctly by the parser • 10 were incorrect because the wrong category was assigned to the relative pronoun • Reflect the fact that complementiser that is fifteen times as frequent as object relative pronoun that • The suppertagger alone gets 74% of the o.r.p. correct • Dependency model is further biased against object extractions • A first attempt at recovering these long-range dependencies
7 Conclusion and further work • Accurate, efficient wide-coverage parsing is possible with CCG • The parser is able to capture a number of long-range dependencies • Is necessary for any parser that aims to support wide-coverage semantic analysis • Long-range dependency recovery가 후처리 단계가 아니라 문법,파서와 통합된 과정 • Building alternative structures that include the long-range dependencies • using better motivated probability models