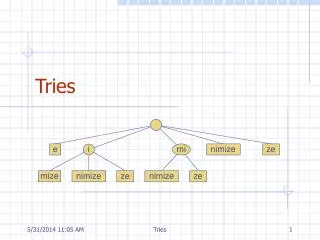
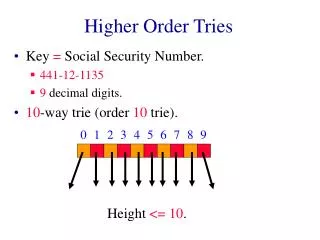
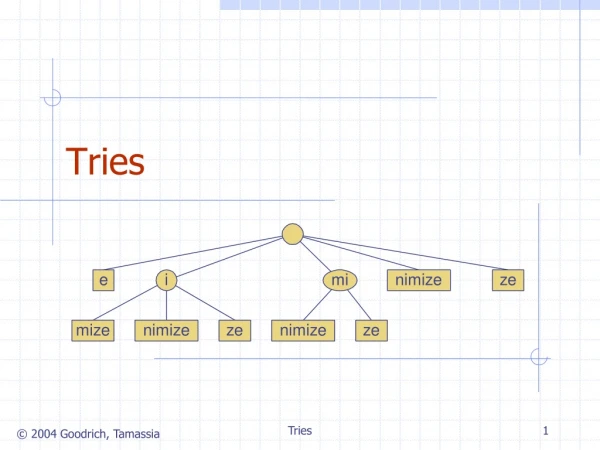
Tries
Tries. [Fredkin, CACM 1960]. 1. 2. 2. 0. 5. 1. 4. 5. 6. 7. 2. 3. (Compacted) Trie. Performance: Search ≈ O(|P|) time Space ≈ O(K + N). s. y. z. omo. aibelyite. stile. zyg. ( 2 ; 3,5). czecin. etic. ygy. ial.


Tries
E N D
Presentation Transcript
[Fredkin, CACM 1960] 1 2 2 0 5 1 4 5 6 7 2 3 (Compacted) Trie • Performance: • Search≈ O(|P|) time • Space≈ O(K + N) s y z omo aibelyite stile zyg (2; 3,5) czecin etic ygy ial systilesyzygeticsyzygialsyzygyszaibelyiteszczecinszomo
[Fredkin, CACM 1960] 2 2 0 5 1 1 4 5 6 7 2 3 (Compacted) Trie • Performance: • Search≈ O(|P|) time • Space≈ O(K + N) s y z • ... But in practice… • Search: random memory accesses • Space: len + pointers + strings omo aibelyite stile zyg (2; 3,5) czecin etic ygy ial systilesyzygeticsyzygialsyzygyszaibelyiteszczecinszomo
Internal Memory Disk 2-level indexing • 2 advantages: • Search≈ typically 1 I/O • Space≈ Front-coding over buckets CT on a sample • 2 limitations: • Sampling rate≈ lengths of sampled strings • Trade-off ≈ speed vsspace (because of bucket size) systileszaielyite ….0systile 2zygetic 5ial 5y 0szaibelyite 2czecin 2omo….
2 2 0 5 1 1 4 5 6 7 2 3 [Morrison, J.ACM 1968] An old idea: Patricia Trie s y z omo aibelyite stile zyg czecin etic ygy ial
2 2 0 1 5 • Search(P): • Phase 1: tree navigation 5 2 1 0 [Ferragina-Grossi, J.ACM 1999] A new search Three-phase search: P = syzyyea s • Phase 2: Compute LCP y z • Phase 3: tree navigation g < y z a o s Only 1 string is checked Trie Space ≈ #strings, NOT their length c P’s position e y i ….systilesyzygeticsyzygialsyzygyszaibelyiteszczecinszomo….
Internal Memory Disk 2-level indexing A limitation is n < M Typically 1 I/O PT on all strings What about n > M ….Locality Preserving Front Coding….
+ • Search(P) • O((p/B) logB n) I/Os • O(occ/B) I/Os It is dynamic... 1 string checked : O(p/B) O(logB n) levels PT PT PT PT PT PT PT PT PT PT 29 1 9 5 2 26 10 4 7 13 20 16 28 8 25 6 12 15 22 18 3 27 24 11 14 29 2 26 13 20 25 6 18 3 14 21 23 21 17 23 [Ferragina-Grossi, J.ACM 1999] The String B-tree 29 13 20 18 3 23 Lexicographic position of P Knuth, vol 3°, pag. 489: “elegant”
3 0 6 5 3 6 4 0 In-order visit + Path covering Knuth 1 6 7 2 3 4 5 On Front-Coding… Front Coding AGA GCGC AGAAGA 5 G 3 C 0 GCGCAGA 6 G 4 GGA 6 GA GG AG AG C A G G GA A A FC + ... is searchable Compacted Trie = FC + tree structure What about other traversals ?
AGA GCGC 3 6 5 3 6 4 0 0 In Front-coding the Lcp information is encoded many times GG AG AG C A G G GA A A 7 6 5 4 1 2 3 Why pre-order visit AGAAGA 1 G 3 C 4 GCGCAGA 1 G 3 GGA 1 GA Rear Coding
What do we mean by “Indexing” ? • Word-based indexes, here a notion of “word” must be devised ! • Inverted lists, Signature files, Bitmaps. • Full-text indexes, no constraint on text and queries ! • Suffix Array, Suffix tree, String B-tree,...
Pattern P occurs at position i of T iff P is a prefix of the i-th suffix of T (ie. T[i,N]) P i T T[i,N] • T =mississippi • mississippi 4,7 P = si From substring search To prefix search Basic notation and facts Occurrences of P in T = All suffixes of T having P as a prefix Reduction SUF(T)= Sorted set of suffixes of T
The Suffix Tree 0 # s i 1 12 si p 1 i Space: #nodes 3 ssi mississippi# # Search pattern P 2 ppi# 1 ppi# ssippi# 4 Maximal repeated substring = node ppi# ssippi# 6 3 i# ppi# pi# ssippi# 7 4 11 8 5 2 1 10 9 Label = <pos,len> T# = mississippi# 2 4 6 8 10
5 T = mississippi# SA SUF(T) 12 11 8 5 2 1 10 9 7 4 6 3 # i# ippi# issippi# ississippi# mississippi# pi# ppi# sippi# sissippi# ssippi# ssissippi# suffix pointer • Suffix Array • SA: Q(N log2 N) bits • Text T: N chars • In practice, a total of 5N bytes The Suffix Array Prop 1. All suffixes in SUF(T) with prefix P are contiguous. Prop 2. Starting position is the lexicographic one of P. T = mississippi# P=si
SA 12 11 8 5 2 1 10 9 7 4 6 3 P is larger 2 accesses per step P = si Searching a pattern Indirected binary search on SA:O(p) time per suffix cmp T = mississippi#
SA 12 11 8 5 2 1 10 9 7 4 6 3 • Suffix Array search • O(log2 N) binary-search steps • Each step takes O(p) char cmp • overall, O(p log2 N) time P is smaller P = si + [Manber-Myers, ’90] Searching a pattern Indirected binary search on SA:O(p) time per suffix cmp T = mississippi#
SA 12 11 8 5 2 1 10 9 7 4 6 3 • Suffix Array search • O (p + log2 N + occ) time si# occ=2 si$ Locating the occurrences T = mississippi# 4 7 12 11 8 5 2 1 10 9 7 4 6 3 12 11 8 5 2 1 10 9 7 4 6 3 where # < S < $ sippi sissippi
SA 12 11 8 5 2 1 10 9 7 4 6 3 Text mining Lcp[1,N-1]= longest-common-prefix between suffixes adjacent in SA • How long is the common prefix between T[i,...] and T[j,...] ? • Min of the subarray Lcp[h,k-1] s.t. SA[h]=i and SA[k]=j Lcp # i# ippi# issippi# ississippi# mississippi pi# ppi# sippi# sissippi# ssippi# ssissippi# 0 1 1 4 0 0 1 0 2 1 3 Lcp(7,3) = 1 = min{2,1,3}
SA 12 11 8 5 2 1 10 9 7 4 6 3 Text mining Lcp[1,N-1]= longest-common-prefix between suffixes adjacent in SA • Does it exist a repeated substring of length ≥ L ? • Maximal Lcp of a suffix is with its adjacent • Search for Lcp[i] ≥ L Lcp # i# ippi# issippi# ississippi# mississippi pi# ppi# sippi# sissippi# ssippi# ssissippi# 0 1 1 4 0 0 1 0 2 1 3
SA 12 11 8 5 2 1 10 9 7 4 6 3 Text mining Lcp[1,N-1]= longest-common-prefix between suffixes adjacent in SA • Does exist a substring of length ≥ L occurring ≥ C times ? • Exist ≥ C equal substrings of length ≥ L chars • Exist ≥ C suffixes sharing a prefix of ≥ L chars • These suffixes may be not contiguous, but... • Their “block” has a common prefix of ≥ L chars • Search for Lcp[i,i+C-2] whose entries are ≥ L Lcp # i# ippi# issippi# ississippi# mississippi pi# ppi# sippi# sissippi# ssippi# ssissippi# 0 1 1 4 0 0 1 0 2 1 3 L = 1, C = 4
SA 12 11 8 5 2 1 10 9 7 4 6 3 Elegant but inefficient How to construct SA from T ? # i# ippi# issippi# ississippi# mississippi pi# ppi# sippi# sissippi# ssippi# ssissippi# • Obvious inefficiencies: • Q(n2 log n) time in the worst-case • Q(n log n)cache misses or I/O faults Input: T = mississippi#
T(n) = O(split) + T(2n/3) + O(|S1|) + O(merge) = O(n) The skew algorithm • The key problem: Compare efficiently two suffixes • Brute-force = Q(n) time per cmp, Q(n2 log n) total In order to sort the suffixes of S 1. Divide the suffixes of S in two groups • S0,2 = suffixes starting at positions 0 mod 3 or 2mod 3 • S1 = suffixes starting at positions 1mod 3 2a. Sort recursively S0,2 (they are 2n/3) 2b. Sort S1: suffix(3i+1) = S[3i+1] suff(3i+2) 3. Merge the sorted S0,2 with the sorted S1
Sort recursively S0,2 We turn this problem into the SA-construction of a shorter string of length (2/3)n. S=AAT GTG AGA TGA $$$ • RadixSort all triplets that start at positions 0,2 mod 3 • T = {ATG, TGT, TGA, GAG, GAT, ATG, GA$, A$$} • Sort(T) = (A$$, ATG, GA$, GAG, GAT, TGA, TGT) • Assign lexicographic names (log n bits) • A$$=1, ATG=2, GA$=3,… • Build s0,2 and encode it: • ATG TGA GAT GA$ TGT GAG ATG A$$ • 2 6 5 3 7 4 2 1 1 2 3 4 5 6 7 8 9 10 11 12 13
Lex-order is preserved Sort recursively S0,2 • Given S=AAT GTG AGA TGA $$$ • We have built: • s0,2= ATG TGA GAT GA$ TGT GAG ATG A$$ • enc(s0,2) = 2 6 5 3 7 4 2 1 • It is SA0,2 = [12, 9, 2, 11, 6, 8, 5, 3] A suffix of s0,2 1 2 3 4 5 6 7 8 9 10 11 12 13 A suffix of enc(s0,2) SA(enc(s0,2)) gives SA0,2
Sort S1 We turn this problem into the sort of pairs S=AAT GTG AGA TGA $$$ Key observation:suff(1) = <A, pos(2)> = <A,3> suff(7) = <A, pos(8)> = <A,6> SA0,2 = [12, 9, 2, 11, 6, 8, 5, 3] Suffix of S1 1 2 3 4 5 6 7 8 9 10 11 12 13 SA1 = [1, 7, 4, 10]
SA0,2 SA1 SA The merge step S=AAT GTG AGA TGA $$$ 1 2 3 4 5 6 7 8 9 10 11 12 13 • To merge suffix si in S0,2 with suffix sk in S1, note that • If (i mod 3) = 2 si+1 and sk+1 belong to S0,2 • If (i mod 3) = 0 si+2 and sk+2 belong to S0,2 • their order can be derived from SA0,2 in O(1) time T(n) = T(2n/3) + O(n) + O(merge) = O(n)