Algoritmo
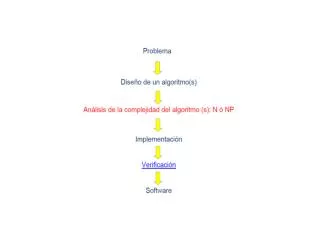
Algoritmo. In informatica, con il termine algoritmo si intende un metodo per la soluzione di un problema adatto a essere implementato sotto forma di programma.


Algoritmo
E N D
Presentation Transcript
Algoritmo In informatica, con il termine algoritmo si intende un metodo per la soluzione di un problema adatto a essere implementato sotto forma di programma. Un algoritmo si può definire come un procedimento che consente di ottenere un risultato atteso eseguendo, in un determinato ordine, un insieme di passi semplici corrispondenti ad azioni scelte solitamente da un insieme finito. Il termine deriva dal nome del matematico persiano Muhammad ibn Mūsa 'l-Khwārizmī, che si ritiene essere uno dei primi autori ad aver fatto riferimento esplicitamente a questo concetto.
Algoritmo di ordinamento • Un algoritmo di ordinamento è un algoritmo che viene utilizzato per elencare gli elementi di un insieme secondo una sequenza stabilita da una relazione d'ordine, in modo che ogni elemento sia minore (o maggiore) di quello che lo segue. In assenza di altre specifiche, la relazione d'ordine viene sempre considerata totale (cioè tale da rendere sempre possibile il confronto tra due elementi dell'insieme): le relazioni d'ordine parziale danno origine agli algoritmi di ordinamento topologico. A seconda del verso della relazione considerato, un ordinamento può essere ascendente o discendente.
Selection sort Il SelectionSort è un algoritmo di ordinamento decisamente semplice ed intuitivo. L' idea di base si fonda nel selezionare ad ogni iterazione l' i-esimo valore piú piccolo, e sostituirlo con quello che in quel momento occupa l' i-esima posizione. In altre parole: -alla prima iterazione dell’algoritmo verrà selezionato l’elemento più piccolo dell’intero insieme e sarà scambiato con quello che occupa la prima posizione; -alla seconda iterazione è selezionato il secondo elemento più piccolo dell’insieme, ossia l’elemento più piccolo dell’insieme “ridotto”costituitodagli elementi {a2,a3,...,an}ed è scambiato con l’elemento che occupa la seconda posizione; -Si ripete fino ad aver collocato nella posizione corretta tutti gli elementi.
Pseudocodice voidselection_sort(int[]A,intn) { Int i=0; for(i=0;i<n;i++) { Int j=0; for(j=i+1;j<n;j++) { if(a[j] < a[i]) { Int temp=a[j]; a[j]=a[i]; a[i]=temp; } } }
Insertion sort L'Insertionsort, in italiano ordinamento a inserimento, è un algoritmo relativamente semplice per ordinare un array. Non è molto diverso dal modo in cui un essere umano, spesso, ordina un mazzo di carte. Esso è un algoritmo in place, cioè ordina l'array senza doverne creare una copia, risparmiando memoria. Pur essendo molto meno efficiente di algoritmi più avanzati, può avere alcuni vantaggi: ad esempio, è semplice da implementare ed è efficiente per insiemi di partenza che sono quasi ordinati.
Pseudocodice Void insertion_sort(int[]A,intn) { Int i=0,j=0; for(i=1;i<n;i++) { Int x=a[i], s=1, d=i-1; while(s<=d) { Int m=(s+d)/2; if(x<a[m]) d=m-1; elses=m+1; } for(j=i-1,j>=s;j--) a[j+1]=a[j];a[s]=x; } }
Bubble sort In informatica il Bubble sort o bubblesort (letteralmente: ordinamento a bolle) è un semplice algoritmo di ordinamento dei dati. Il suo funzionamento è semplice: ogni coppia di elementi adiacenti della lista viene comparata e se essi sono nell'ordine sbagliato vengono invertiti. L'algoritmo scorre poi tutta la lista finché non vengono più eseguiti scambi, situazione che indica che la lista è ordinata. L'algoritmo deve il suo nome al modo in cui gli elementi vengono ordinati, con quelli più piccoli che "risalgono" verso le loro posizioni corrette all'interno della lista così come fanno le bollicine in un bicchiere di spumante. In particolare, alcuni elementi attraversano la lista velocemente (come bollicine che emergono dal fondo del bicchiere), altri più lentamente: i primi sono in gergo detti "conigli" e sono gli elementi che vengono spostati nella stessa direzione in cui scorre l'indice dell'algoritmo, mentre i secondi sono detti "tartarughe" e sono gli elementi che vengono spostati in direzione opposta a quella dell'indice. Come tutti gli algoritmi di ordinamento, può essere usato per ordinare dati di un qualsiasi tipo su cui sia definita una relazione d'ordine. Il Bubble sort non è un algoritmo efficiente: ha una complessità computazionale dell'ordine di O(n^2) confronti, con n elementi da ordinare; si usa solamente a scopo didattico in virtù della sua semplicità, e per introdurre i futuri programmatori al ragionamento algoritmico e alle misure di complessità. Dell'algoritmo esistono numerose varianti, per esempio lo shaker sort.
Pseudocodice Voidbubble_sort(int[]A,intn) { Bool scambio=true; Int ultimo=n-1,i=0; while(scambio) { scambio=false; for(i=0;i<ultimo;i++) { if(a[i]>a[i+1]) { Inttemp=a[i]; a[i]=a[i+1]; a[i+1]=temp; scambio=true; } } ultimo--; } }
Quick sort Quicksort è un algoritmo di ordinamento ricorsivo in place che, come merge sort, si basa sul paradigma divide et impera. La base del suo funzionamento è l'utilizzo ricorsivo della procedura partition: preso un elemento da una struttura dati (es. array) si pongono gli elementi minori a sinistra rispetto a questo e gli elementi maggiori a destra. Il Quicksort, termine che tradotto letteralmente in italiano indica ordinamento rapido, è l'algoritmo di ordinamento che ha, in generale, prestazioni migliori tra quelli basati su confronto. È stato ideato da Charles Antony Richard Hoare nel 1961.
Pseudocodice Voidsort(int[]array,intbegin,intend) { Int pivot, l, r; if(end > begin) { pivot = array[begin]; l = begin + 1; r = end+1; while(l < r) { if(array[l] < pivot) l++; else { r--; swap(array[l], array[r]);
Merge sort Il merge sort è un algoritmo di ordinamento basato su confronti che utilizza un processo di risoluzione ricorsivo, sfruttando la tecnica del Divide et Impera, che consiste nella suddivisione del problema in sottoproblemi della stessa natura di dimensione via via più piccola. Fu inventato da John von Neumann nel 1945. Una descrizione dettagliata e un'analisi della versione bottom-up dell'algoritmo apparve in un articolo di Goldstine e Neumann già nel 1948.
Pseudocodice Void merge (int[]a,intleft,intcenter,intright) Int i = left, j=center + 1,k=0; int[] b; while ((i <= center) && (j <= right)) { if(a[i] <= a[j]){ b[k]=a[i]; i=i + 1; } else { b[k] = a[j]; j=j + 1; } k=k + 1; }
Shell sort Lo Shell sort (o Shellsort) è uno dei più vecchi algoritmi di ordinamento. È stato ideato nel 1959 da Donald L. Shell. L' algoritmo è veloce e facile da comprendere e da implementare, ma è difficile analizzarne il tempo di esecuzione. Lo Shell sort è simile all'insertionsort, ma funziona spostando i valori di più posizioni per volta man mano che risistema i valori, diminuendo gradualmente la dimensione del passo sino ad arrivare ad uno. Alla fine, lo Shell sort esegue un insertionsort, ma per allora i dati saranno già piuttosto ordinati. Consideriamo un valore piccolo posizionato inizialmente all'estremità errata di un array dati di lunghezza n. Usando l'insertionsort, ci vorranno circa n confronti e scambi per spostare questo valore lungo tutto l'array fino all'altra estremità. Con lo Shell sort, si muoveranno i valori usando passi di grosse dimensioni, cosicché un valore piccolo andrà velocemente nella sua posizione finale con pochi confronti e scambi.
Bucketsort Il Bucketsort è un algoritmo di ordinamento per valori numerici che si assume siano distribuiti uniformemente in un intervallo semichiuso (0,1). La complessità del bucketsort è lineare O(n+m) (ove m è il valore max nell'array), questo è possibile in quanto l'algoritmo non è basato su confronti. L'intervallo dei valori, noto a priori, è diviso in intervalli più piccoli, detti bucket (cesto). Ciascun valore dell'array è quindi inserito nel bucket a cui appartiene, i valori all'interno di ogni bucket vengono ordinati e l'algoritmo si conclude con la concatenazione dei valori contenuti nei bucket.
Pseudocodice BucketSort(array A, intero M) for i ← 1 to length[A] do // restituisce un indice di bucket per l'elemento A[i] bucket ← f(A[i], M) // inserisce l'elemento A[i] nel bucket corrispondente aggiungi(A[i], B[bucket]) for i ← 1 to M do // ordina il bucket ordina(B[i]) // restituisce la concatenazione dei bucket return concatena(B)