Learning Optical Flow
E N D
Presentation Transcript
Learning Optical Flow Goren Gordon and Emanuel Milman Advanced Topics in Computer Vision May 28, 2006 • After Roth and Black: • On the Spatial Statistics of Optical Flow, ICCV 2005. • Fields of Experts:A Framework for Learning Image Priors, CVPR 2005.
Overview • Optical Flow Reminder and Motivation. • Learning Natural Image Priors: • Product of Experts (PoE). • Markov Random Fields (MRF). • Fields of Experts (FoE) = PoE + MRF. • Training FoE: • Markov Chain Monte Carlo (MCMC). • Contrastive Divergence (CD). • Applications of FoE: • Denoising. • Inpainting. • Optical Flow Computation.
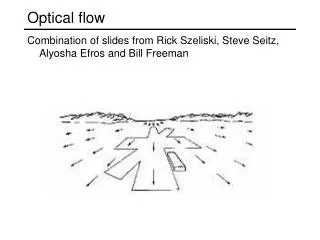
Optical Flow (Reminder from last week) … (taken from Darya and Denis’s presentation)
Optical Flow Reminder Optical Flow (Reminder) I(x,y,t) = Sequence of Intensity Images. Brightness Constancy Assumption under optical flow field (u,v): First order Taylor approximation -Optical Flow Constraint Equation: + = Partial derivatives Aperture Problem: one equation, two unknowns. Can only determine the normal flow = component of (u,v) parallel to (Ix,Iy). frame #2 frame #1 flow field (images taken from Darya and Denis’s presentation)
Optical Flow Reminder Finding Optical Flow (Reminder) • Local Methods (Lucas-Kanade) – assume (u,v) is locally constant: • - Pros: robust under noise. • - Cons: if image is locally constant, need interpolation steps. • Global Methods (Horn-Schunck) – use global regularization term: • - Pros: automatic filling-in in places where image is constant. • - Cons: less robust under noise. Combined Local-Global Method (Weickert et al.)
Optical Flow Reminder CLG Energy Functional Kσ – smoothing kernel (spatial or spatio-temporal):
Optical Flow Motivation Spatial Regularizer - Revisited ρD, ρS- quadratic robust (differentiable) penalty functions. Motivation: why use ? Answer: Optical-flow is piecewise smooth; lets hope that spatial term captures this behaviour. • Questions: • Which ρS to use? Why are some functions better than others? • Maybe more information in wthan first order? • Maybe are dependant?
Optical Flow Motivation Learning Optical Flow Roth and Black, “On the Spatial Statistics of Optical Flow”, ICCV 2005. Idea: learn (from training set) prior distribution on w, and use its energy-functional as spatial-term! First-order selected prior Higher-order learned prior FoE = Fields of Experts
Optical Flow Motivation Fields of Experts (FoE) Fields of Experts = Product of Experts + Markov Random Fields (FoE) (PoE) (MRF) Roth and Black, “Fields of Experts: A framework …”, CVPR 2005. Model rich prior distributions for natural images. • Many applications: • Denoising. √ • Inpainting. √ • Segmentation. • more… Detour: review FoE model on natural images.
Need to model correlations in image structure over extended neighborhoods. Natural Images Modeling Natural Images • Challenging: • High dimensionality ( |Ω| ≥10000 ). • Non-Gaussian statistics (even simplest models assume MoG).
Natural Images Observations • Observations (Olshausen, Field, Mumford, Simoncelli, etc..) • Many linear filters have non-Gaussian responses: concentrated around 0 with “heavy tails”. www.cvgpr.uni-mannheim.de/heiler/natstat
Natural Images Observations • Observations (Olshausen, Field, Mumford, Simoncelli, etc..) • Many linear filters have non-Gaussian responses: concentrated around 0 with “heavy tails”. • Responses of different filters are usually not independent. • Statistics of image pixels are higher-order than pair-wise correlations.
Natural Images Image Patches Modeling Image Patches • Example-based learning (Freeman et al.) – use measure of consistency between image patches. • FRAME (Zhu, Wu and Mumford) – use hand selected filters and discretized histograms to learn image prior for texture modeling. • Linear models: n-dim patch x is stochastic linear combination of m basis patches {Ji}.
Natural Images Image Patches Linear Patch Models n dim patch 1. PCA – if ai are Gaussian(decompose CoVar(x) into eigenvectors). (Non-realistic.) 2. ICA – if aiare independentnon-Gaussian and n=m. (Generally impossible to find n independent basis patches.) 3. Sparse Coding (Olshausen and Field) – use m>n and assume aiare highly concentrated around 0, to derive sparse representation model with an over-complete basis. (Need computational inference step to calculate ai.) 4. Product of Experts = PoE (Hinton).
Product of Experts = ? X X X
Natural Images Image Patches Product of Experts Product of Experts (PoE) • Model high-dim distributions as product of low-dim expert distributions. subspace x – data θi – i’th expert’s parameter • Each expert works on a low(1)-dim subspace - easy to model. • Parameters{θi} can be learned on training sequence. • PoEs produce sharper and expressive distributions than individual expert models (similar to Boosting techniques). • Very compact model compared to mixture-models (like MoG).
Natural Images Image Patches Product of Experts PoE Examples • General framework, not restricted to CV applications. • Sentences: • One expert can ensure that tenses agree. • Another expert can ensure that subject and verb agree. • Grammar expert. • Etc… • Handwritten digits: • One set of experts can model the overall shape of digit. • Another set of experts can model the local stroke structure. Given ‘7’ prior User written Mayraz and Hinton Given ‘9’ prior
Natural Images Image Patches Product of Experts Product of Student-T (PoT) • Filter responses on images - concentrated, heavy tailed distributions. • Welling, Hinton et al “Learning … with product of Student-t distributions”, 2003. Model with Student-t: Polynomial tail decay!
Natural Images Image Patches Product of Experts Product of Student-T (PoT) x J1 JN …
In Gibbs form: Partition function - Parameters - Natural Images Image Patches Product of Experts Product of Student-T (PoT)
Natural Images Image Patches Product of Experts PoE Training Set ~60000 5*5 patches randomly cropped from Berkely Segmentation Benchmark DB.
Natural Images Image Patches Product of Experts PoE Learned Filters • Will discuss learning procedure in FoE model. • 5*5-1=24 filters Ji were learned (no DC filter): • Gabor-like filters accounting for local edge structures. • Samecharacteristics when training more experts. • Results are comparative to ICA.
Natural Images Image Patches Product of Experts PoE – Final Thoughts • PoE permits fewer, equal or more experts than dimension. • Over-complete case allows dependencies between different filters to be modeled, and thus more expressive than ICA. • Product structure forces the learned filters to be “as independent as possible”, capturing different characteristics of patches. • Contrary to example-based approaches, the parametric representation generalizes better and beyond the training data.
Natural Images From Patches to Images • Extending former approach to entire images is problematic: • Image-size is too big. Need huge number of experts. • Model would depend on particular image-size. • Model would not be translation-invariant. Natural model for extending local patch model to entire image: Markov Random Fields.
Markov Random Fields (just 2 slides!)
Natural Images Markov Random Fields Markov Random Fields (MRF) have joint distribution P. is a Markov Random Field on G if: N(S) = {neighbors of S} \ S
Natural Images Markov Random Fields Gibbs Distributions Hammersley-Clifford Theorem: is a MRF with P>0 iffP is a Gibbs distribution. P is a Gibbs distribution on X if: C = set of all maximal cliques (complete sub-graphs) in G. Vc = potential associated to clique c. Connects local property (MRF) with global property (Gibbs dist.)
Natural Images Fields of Experts Fields of Experts (FoE) Fields of Experts = Product of Experts + Markov Random Fields (FoE) (PoE) (MRF) MRF: V = image lattice, E = connect all nodes in m*m patch x(k) . Overlapping Make model translation invariant: Vk = W. Model potential W using a PoE: Vk
Natural Images Fields of Experts FoE Density • Other MRF approaches typically use hand selected clique potentials and small neighborhood systems. • In FoE, translation invariant potential W is directly learned from training images. • FoE = density is combination of overlapping local experts. • (MRF) (PoE)
Natural Images Fields of Experts FoE Model Pros • Overcomes previously mentioned problems: • - Parameters Θ depend only on patch’s dimensions. • - Applies to images of arbitrary size. • - Translation invariant by definition. • Explicitly models overlap of patches, by learning from training images. • Overlapping patches are highly correlated; learned filters Ji and αi must account for this
Natural Images Fields of Experts Learned Filters FoE PoE
Natural Images Training FoE Training FoE Given training-set X=(x1,…,xn), its likelihood is: Find Θ which maximize likelihood = minimize minus log-likelihood Difficulty: computation of Z(Θ) is severely intractable:
Natural Images Training FoE Gradient Descent X – empirical data distribution; pFoE – model distribution. Conclusion: need to calculate <f>p, even if p is intractable.
Natural Images Training FoE Markov Chain Monte Carlo Markov Chain Monte Carlo MCMC – method for generating sequence of random (correlated) samples from an arbitrary density function . Calculating q is tractable, p may be intractable. Use: approximate where xi ~ p using MCMC. Developed by physicists in late 1940’s (Metropolis).Introduced to CV community by Geman and Geman (1984). Idea: build a Markov chain which converges from an arbitrary distribution to p(x). Pros: easy to mathematically prove convergence to p(x). Cons: no convergence rate guaranteed; samples are correlated.
Natural Images Training FoE Markov Chain Monte Carlo MCMC Algorithms • Metropolis Algorithm • Select any initial position x0. • At iteration k: • Create new trial position x* = xk+∆x, ∆x ~ symmetric trial distribution. • Calculate ratio . • If r≥1 or with probability r, accept: xk+1 = x*; otherwise stay put: xk+1 = xk. x* xk xk+1 x* x0 • Resulting distribution converges to p !!! • Creates a Markov Chain since xk+1 depends only on xk. • Trial distribution dynamically scaled to have fixed acceptance rate.
Natural Images Training FoE Markov Chain Monte Carlo MCMC Algorithms Other algorithms to build sampling Markov chain: • Gibbs Sampler (Geman and Geman): • Vary only one coordinate of xat a time. • Draw new value of xj from conditional p(xj | x1,..,xj-1,xj+1,..,xn) - usually tractable when p is a MRF. • Hamiltonian Hybrid Monte Carlo (HMC): • State of the art; very efficient. • Details omitted.
Natural Images Training FoE Back to FoE Gradient Descent Step size X0 = empirical data distribution (xi with probability 1/n). Xm = distribution of MCMC (initialized by X0) after m iterations. X∞ = MCMC converges to desired distribution . Contrastive Divergence (Hinton) Use where yj ~ X∞ using MCMC. Computationally Intensive
Natural Images Training FoE Contrastive Divergence Contrastive Divergence (CD) Intuition: running MCMC sampler for few iterations from X0 draws samples closer to target distribution X∞ enough to “feel” gradient. Formal justification of “Contrastive Divergence” (Hinton): Maximizing Likelihood p(X0|X∞) = Minimizing KL Divergence X0 || X∞ CD is (almost) equivalent to minimizing X0 || X∞ - Xm || X∞ .
Natural Images Training FoE FoE Training Implementation • Size of training images should be substantially larger than patch (clique) size to capture spatial dependencies of overlapping patches. • Trained on 2000 randomly cropped 15*15 images (5*5 patch) from 50 images in Berkley Segmentation Benchmark DB. • Learned 24 expert filters. • FoE Training is computationally intensive but off-line feasible.
Natural Images Training FoE FoE Training – Question Marks • Note that under the MRF model: p(5*5 patch | rest of image) = p(5*5 patch | 13*13 patch \ 5*5 patch). • Therefore we feel that: • 15*15 images are too small to learn MRF’s 5*5 clique potentials. • Better to use 13*13-1 filters instead of 5*5-1. • Details which were omitted: • - HMC details. • - Parameter values. • - Faster convergence by whitening patch pixels before computing gradient updates. 5 13 15
inpainting E = (data term) + (FoE term) Natural Images FoE Applications General E = (data term) + (spatial term) denoising E = (noise) + (FoE term) optical flow E = (local data term) + (FoE term)
Natural Images FoE Applications Denoising Field of Experts: Denoising y x http://www.cs.brown.edu/~roth/
Natural Images FoE Applications Denoising Field of Experts: adding noise Noisy image true image Gaussian noise x y
Natural Images FoE Applications Denoising Field of Experts: Denoising Use the posterior probability distribution Known noise distribution Distribution of Image using Prior Experts Learned