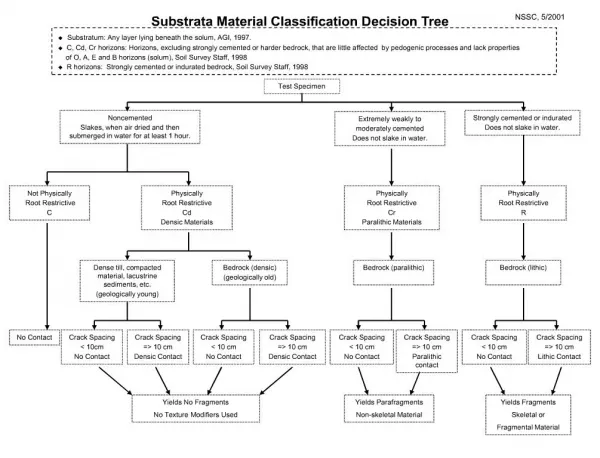
Download

1 / 32
320 likes | 473 Views
Decision tree based classification s of heterogeneous lung cancer data. Student: Yi LI Supervisor: Associate Prof. Jiuyong Li Data: 15 th May 2009. Outline. Microarray data Motivations Related work Our integrated framework Experiments Discussions Conclusion. Microarray data.

E N D
Decision tree based classifications of heterogeneous lung cancer data Student: Yi LI Supervisor: Associate Prof. Jiuyong Li Data: 15th May 2009
Outline Microarray data Motivations Related work Our integrated framework Experiments Discussions Conclusion
Microarray data Microarray rationale (Babu, 2004b)
Microarray data (con’d) Snapshot of DNA oligonucleotides Reveal rich biological information: DNA sequences, cell structures & cancer Hugh amount of data: Number of attributes in thousands or more Number of samples in hundreds or less
Microarray data (con’d) Gene name Patient samples its values A part of a microarray data set
Motivations • Key goal: to find out reliable and robust predictors (gene sets) • However, microarray studies addressing similar prediction tasks report different sets of predictive genes
Motivations (con’d) • Two-dimensional cluster analysis + leave-one-out cross-validation [van’t Veer et al. (2002)] • Cox’s proportional-hazards regression + clustering [Wang et al. (2005)]
Research question How to build up a framework to improve the prediction accuracy among heterogeneous microarray data sets?
Dilemma 1 Usually a microarray data set contains thousands of features, but with limited number of samples. It creates troubles to expect robust and reliable classifiers.
Related work • Curse of data set sparsity + curse of dimensionality [Somorjai et al. (2003)] • Use simple classifiers to show how those curses influence outcomes • Samples per feature ratio (SFR) in microarray data set is too small to expect robust classifiers. • Conventional solutions: feature redundant, apply classifiers that do not require feature space redundant.
Related work • Probably approximately correct sorting (PAC) [Ein-Dor et al. (2006)] • Use PAC to evaluate the robustness of results • Determine the number of samples that are required to achieve any desired level of reproducibility
Dilemma 2 Heterogeneous microarray platforms, differences in equipment and protocols, and differences in the analysis methods may also cause discordance between independent experiments.
Related work • Correlation and concordance calculations [Kuo et al. (2002)] • Median rank scores + quantile discretization + SVM [Warnat et al. (2005)] • Stanford type cDNA microarrays and Affymetrix oligonucleotide microarrays
Dilemma 3 Eliminating the factors mentioned in dilemma 1 & 2, the discrepancies between studies still remain.
Related work • Expand standard strategy to multiple sets [Michiels et al. (2005)] • SVM-RFE + 5-fold cross-validation + joint-core [Fishel, I et al. (2007)] • There are many optimal predictive gene sets, which are strongly dependent on the subset of samples chosen for training.
Research goal Our purpose to build a robust and reliable model to study heterogeneous microarray data sets, to reduce study-specific biases, and aiming to yield results which offer improved reliability and validity.
Our integrated framework • Classification on single data set • Standard classification • Single tree, Bagging & Random Forest • Classification on integrated data sets • Low-level data integration • Single tree, Bagging & Random Forest • Classification on integrating models from multiple data sets • High-level model integration • Integrated model based on two single trees
Available data sets * All data sets are in .CSV format * Attribute names are denoted by gene probe names * All data sets are independent to each other
Available data sets (con’d) • Harvard_Unique_probname.csv • Michigan_Unique_probname.csv • Two columns: Probe & Gene Symbol • Mapping files: maps probe names with its corresponding gene symbols • Multiple probe names may map to one gene symbol
Data pre-processing • Gene name substitution • R-programming language • Remove missing values • Remove duplicated genes • Remove all, including the 1st appeared one • Find out overlapping genes • Find the common gene subsets between Harvard and Michigan
Data pre-processing (con’d) • Substitute gene symbols with probe names • H and M contain the same set of genes (not same sequence) • Stanford contains the same set, too
Data pre-processing (con’d) • Feature selection • Weka • GainRatioAttributeEval > Ranker • Select 100 highly ranked genes from H & M, separately • 48 of them are overlapped, 52 genes are unique
Data pre-processing (con’d) • 3 parts: unique genes of H’, overlapping genes and unique genes of M’ • H’ , M’ and S’: with gene set of the union parts above: • H’: ‘?’s to indicate unique genes of M’ • M’: ‘?’s to indicate unique gene of H’ • S’: no missing values generated in this stage
Data pre-processing (con’d) • Discretization • Mean value • R-programming language • Missing values
Data pre-processing (con’d) • Handle incompatible format • ARFF format • Attribute section • Same sequence of attributes • Same possible values with same sequence • Data section • Values must match their corresponding data types
Experiments 1 • Weka Explorer • Build single decision trees on data sets • Classify > Classifier > trees > J48 • Test options > Supplied test set • Build Bagging trees on data sets • Classify > Classifier > meta > Bagging • Build Random Forest on data sets • Classify > Classifier > meta > RandomCommittee (Classifier >RandomForest)
Experiment 2 • Matlab • Build single trees upon H and M, separately • For an unseen instance, do prediction on two models, • if the predicted classes are the same, then keep it as it is; • otherwise, the class label with greater confidence value wins. • Accuracy = no. of correctly predicted / total
Major reference Babu, M. M. 2004b, “An introduction to Microarray data analysis” MRC Lab page, visited on 15 June 2008, <http://www.mrc-lmb.cam.ac.uk/genomes/madanm/microarray/.> Choi. J.K. et al. (2003) Combining multiple microarray studies and modeling interstudy variation. Bioinformatics, 19, i84-i90. Ein-Dor, L. et al. (2005) Outcome signature genes in breast cancer: is there a unique set? Bioinformatics, 21, 171-178. Ein-Dor, L. et al.(2006) Thousands of samples are needed to generate a robust gene list for predicting outcome in cancer. PNAS, 103, 5923-5928. Fishel, I. et al. (2007) Meta-analysis of gene expression data: a predictor-based approach. Bioinformatics, Vol. 23, 1599-1606. Jiang, H. et al. (2004) Joint analysis of two microarray gene expression data sets to select lung adenocarcinoma marker genes. BMC Bioinformatics, 5, 81. Kuo, W.P. et al. (2002) Analysis of matched mRNA measurements from two different microarray technologies. Bioinformatics, 18, 405-412. Michiels, S. et al. (2005) Prediction of cancer outcome with microarrays: a multiple random validation strategy, Lancet, 365, 488-492. Rhodes, D. R. et al. (2002) Meta-analysis of microarrays: interstudy validation of gene expression profiles reveals pathway dysregulation in prostate cancer. Cancer Res.,62, 4427-4433. Van’t Veer, L.J. (2002) Gene expression profiling predicts clinical outcome of breast cancer. Nature, 415, 530-536. Wang, Y. et al. (2005) Gene-expression profiles to predict distant metastasis of lymph-node-negative primary breast cancer. Lancet,365, 671-679.