Download

1 / 18
190 likes | 358 Views
Patch Based Prediction Techniques University of Houston. By : Paul AMALAMAN From : UH-DMML Lab Director: Dr. Eick. Introduction 1. Research Goals 2. Problem Setting 3. Solutions: TPRTI-A & TPRTI-B 4. Results 5. Conclusion Future Work. UH-DMML Lab 1. Research Goals.

E N D
Patch Based Prediction TechniquesUniversity of Houston By: Paul AMALAMANFrom: UH-DMML LabDirector: Dr. Eick
Introduction1. Research Goals 2. Problem Setting 3. Solutions: TPRTI-A & TPRTI-B4. Results5. ConclusionFuture Work UH-DMML Lab 1
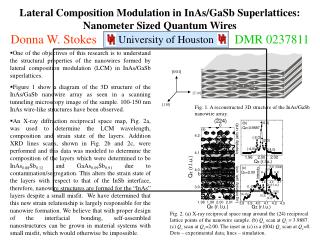
Research Goals To improve Machine Learning techniques for inducing predictive models based on efficient subdivisions of the input space(patches) Areas of Focus: • Linear Regression Tree Induction • Classification Tree Induction UH-DMML Lab 2
Background (Research Goals Continued) Linear regression is a global model, where there is a single predictive formula holding over the entire data-space. Y = β0 + βTX + ϵ Linear Regression Tree When the data has lots of input attributes which interact in complicated, nonlinear ways, assembling a single global model can be very difficult. An alternative approach to nonlinear regression is to split, or partition, the space into smaller regions, where the interactions are more manageable. We then partition the sub-divisions again - this is called recursive partitioning - until finally we get to chunks of the space which can fit simple models to them. Splitting Method • selecting the pair {split variable, split value} • minimizing some error/objective function UH-DMML Lab 3
Background (Research Goals Continued) Popular approaches: 1-Variance-based • {split variable, split value} selection: try each mean value of each input attribute • objective function: variance minimization scalable, complex trees, often less accurate 2-RSS-based • {split variable, split value} selection: try each value for each input attribute (Exhaustive search) • objective function: RSS minimization (Residual Sum of Squared Errors) Less scalable, smaller trees, better accuracy Our Research Goals: Toinduce smaller trees with better accuracy while improving on scalability by designing better splitting methods (patches), and objective functions UH-DMML Lab 4
Problem Setting Exhaustive search y x Variance-based y A B G (A) (D) (B) (C) (G) (F) (E) x UH-DMML Lab 5
Problem Setting y A (B) (C) (A) B C x Our Research Goals: Toinduce smaller trees with better accuracy while improving on scalability by designing better splitting methods (patches), and objective functions UH-DMML Lab 6
Example (Problem Setting Continued) x1 and x2=0, and y 1-Variance –based approaches like M5 will miss the optimum split point 2-Exhaustive search approaches like RETIS will find optimum split point but at cost of expensive search (not scalable) UH-DMML Lab 7
Solutions Current Proposed Solution • Detect areas in the dataset where the general trend makes sharp turns (Turning Points) • Use Turning Points as potential split points in a Linear Regression Tree induction algorithm Challenges: • Determining the turning points • Balancing accuracy, model complexity, and runtime complexity UH-DMML Lab 8
Determining Turning Points (Solutions continued) UH-DMML Lab 9
Two New Algorithms (Solutions continued) Two algorithms: TPRTI-A and TPRTI-B Both rely on • detecting potential split points in the dataset (turning points) • then feed a tree induction algorithm with the split points TPRTI-A and TPRTI-B differ by their objective functions • TPRTI-A RSS based node evaluation approach • TPRTI-B uses a two steps node evaluation function • Select split point based on distance • Use RSS computation to select the pair {split variable/split value} UH-DMML Lab 10
Two New Algorithms (Solutions continued) TPRTI-B uses a two steps node evaluation function • Select split point based on distance • Use RSS computation to select the pair {split variable/split value} TPRTI-A RSS based node evaluation approach. Does a look-ahead split for each turning point and select the split that best minimizes RSS UH-DMML Lab 11
Results On Accuracy Table1. Comparison between TPRTI-A, TPRTI-B and state-of-the-art approaches with respect to accuracy (wins/ties/loses) UH-DMML Lab 12
Results On Complexity Table2. Number of times an approach obtained the combination (Best accuracy, fewest leaf-nodes) UH-DMML Lab 13
Results On Scalability UH-DMML Lab 14
Conclusion We propose a new approach for Linear Regression Tree construction called Turning Point Regression Tree Induction (TPRTI) that infuses turning points into a regression tree induction algorithm to achieve • improved scalability while maintaining high accuracy and low model complexity. • Two novel linear regression tree induction algorithms called TPRTI-A and TPRTI-B which incorporate turning points into the node evaluation were introduced and experimental results indicate that TPRTI is a scalable algorithm that is capable of obtaining a high predictive accuracy using smaller decision trees than other approaches. UH-DMML Lab 15
FUTURE WORK We are investigating how turning point detection can also be used to induce better classification trees. UH-DMML Lab 16