Download
1 / 51
901 likes | 3.88k Views
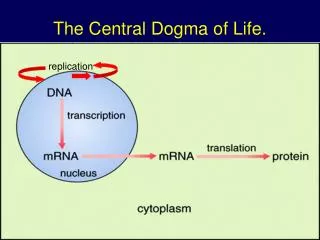
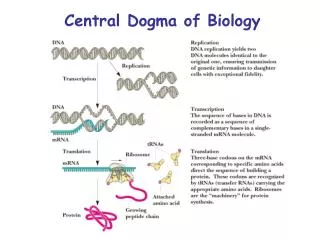
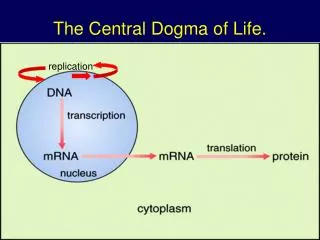
replication. The Central Dogma of Life. Protein Synthesis. The information content of DNA is in the form of specific sequences of nucleotides along the DNA strands The DNA inherited by an organism leads to specific traits by dictating the synthesis of proteins

E N D
replication The Central Dogma of Life.
Protein Synthesis • The information content of DNA is in the form of specific sequences of nucleotides along the DNA strands • The DNA inherited by an organism leads to specific traits by dictating the synthesis of proteins • The process by which DNA directs protein synthesis, gene expression includes two stages, called transcription and translation
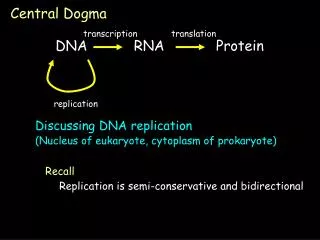
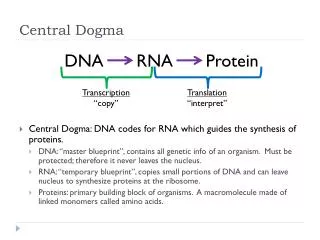
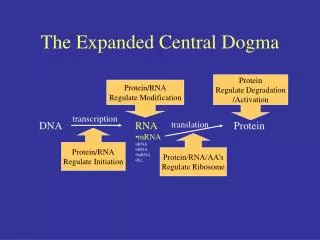
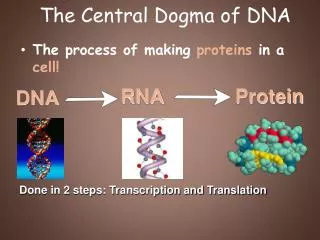
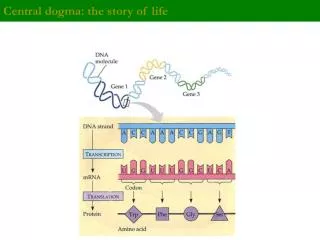
Transcription and Translation • Cells are governed by a cellular chain of command • DNA RNA protein • Transcription • Is the synthesis of RNA under the direction of DNA • Produces messenger RNA (mRNA) • Translation • Is the actual synthesis of a polypeptide, which occurs under the direction of mRNA • Occurs on ribosomes
DNA TRANSCRIPTION mRNA Ribosome TRANSLATION Polypeptide (a) Prokaryotic cell. In a cell lacking a nucleus, mRNAproduced by transcription is immediately translatedwithout additional processing. Transcription and Translation • In prokaryotes transcription and translation occur together Figure 17.3a
Nuclear envelope DNA TRANSCRIPTION Pre-mRNA RNA PROCESSING mRNA Ribosome TRANSLATION (b) Eukaryotic cell. The nucleus provides a separatecompartment for transcription. The original RNAtranscript, called pre-mRNA, is processed in various ways before leaving the nucleus as mRNA. Polypeptide Transcription and Translation • In a eukaryotic cell the nuclear envelope separates transcription from translation • Extensive RNA processing occurs in the nucleus
Transcription • Transcription is the DNA-directed synthesis of RNA • RNA synthesis • Is catalyzed by RNA polymerase, which pries the DNA strands apart and hooks together the RNA nucleotides • Follows the same base-pairing rules as DNA, except that in RNA, uracil substitutes for thymine
RNA • RNA is single stranded, not double stranded like DNA • RNA is short, only 1 gene long, where DNA is very long and contains many genes • RNA uses the sugar ribose instead of deoxyribose in DNA • RNA uses the base uracil (U) instead of thymine (T) in DNA. Table 17.1
1 3 2 Promoter Transcription unit 5 3 3 5 Start point DNA RNA polymerase Initiation. After RNA polymerase binds to the promoter, the DNA strands unwind, and the polymerase initiates RNA synthesis at the start point on the template strand. Template strand of DNA 5 3 3 5 Unwound DNA RNA transcript Elongation. The polymerase moves downstream, unwinding the DNA and elongating the RNA transcript 5 3 . In the wake of transcription, the DNA strands re-form a double helix. Rewound RNA 5 3 3 5 3 RNA transcript 5 Termination. Eventually, the RNA transcript is released, and the polymerase detaches from the DNA. 5 3 3 5 3 5 Completed RNA transcript Synthesis of an RNA Transcript • The stages of transcription are • Initiation • Elongation • Termination
Eukaryotic promoters 1 TRANSCRIPTION DNA Pre-mRNA RNA PROCESSING mRNA Ribosome TRANSLATION Polypeptide Promoter 5 3 A T A T A A A A T A T T T T 3 5 TATA box Start point Template DNA strand Several transcription factors 2 Transcription factors 5 3 3 5 Additional transcription factors 3 RNA polymerase II Transcription factors 3 5 5 3 5 RNA transcript Transcription initiation complex Synthesis of an RNA Transcript - Initiation • Promoters signal the initiation of RNA synthesis • Transcription factors help eukaryotic RNA polymerase recognize promoter sequences • A crucial promoter DNA sequence is called a TATA box.
Non-template strand of DNA Elongation RNA nucleotides RNA polymerase T A C C A T A T C 3 U 3 end T G A U G G A G E A C C C A 5 A A T A G G T T Direction of transcription (“downstream”) 5 Template strand of DNA Newly made RNA Synthesis of an RNA Transcript - Elongation • RNA polymerase synthesizes a single strand of RNA against the DNA template strand (anti-sense strand), adding nucleotides to the 3’ end of the RNA chain • As RNA polymerase moves along the DNA it continues to untwist the double helix, exposing about 10 to 20 DNA bases at a time for pairing with RNA nucleotides
Synthesis of an RNA Transcript - Termination • Specific sequences in the DNA signal termination of transcription • When one of these is encountered by the polymerase, the RNA transcript is released from the DNA and the double helix can zip up again.
Post Termination RNA Processing • Most eukaryotic mRNAs aren’t ready to be translated into protein directly after being transcribed from DNA. mRNA requires processing. • Transcription of RNA processing occur in the nucleus. After this, the messenger RNA moves to the cytoplasm for translation. • The cell adds a protective cap to one end, and a tail of A’s to the other end. These both function to protect the RNA from enzymes that would degrade • Most of the genome consists of non-coding regions called introns • Non-coding regions may have specific chromosomal functions or have regulatory purposes • Introns also allow for alternative RNA splicing • Thus, an RNA copy of a gene is converted into messenger RNA by doing 2 things: • Add protective bases to the ends • Cut out the introns
A modified guanine nucleotide added to the 5 end 50 to 250 adenine nucleotides added to the 3 end TRANSCRIPTION DNA Polyadenylation signal Protein-coding segment Pre-mRNA RNA PROCESSING 5 3 mRNA G P P AAA…AAA P AAUAAA Ribosome Start codon Stop codon TRANSLATION Poly-A tail 5 Cap 5 UTR 3 UTR Polypeptide Alteration of mRNA Ends • Each end of a pre-mRNA molecule is modified in a particular way • The 5 end receives a modified nucleotide cap • The 3 end gets a poly-A tail
RNA Processing - Splicing • The original transcript from the DNA is called pre-mRNA. • It contains transcripts of both introns and exons. • The introns are removed by a process called splicing to produce messenger RNA (mRNA)
Intron Exon 5 Exon Intron Exon 3 5 Cap Poly-A tail Pre-mRNA TRANSCRIPTION DNA 30 31 104 105 146 1 Pre-mRNA RNA PROCESSING Introns cut out and exons spliced together Coding segment mRNA Ribosome TRANSLATION 5 Cap Poly-A tail mRNA Polypeptide 1 146 3 UTR 3 UTR RNA Processing - Splicing • Ribozymes are catalytic RNA molecules that function as enzymes and can splice RNA • RNA splicing removes introns and joins exons Figure 17.10
3 1 2 RNA transcript (pre-mRNA) 5 Intron Exon 1 Exon 2 Protein Other proteins snRNA snRNPs Spliceosome 5 Spliceosome components Cut-out intron mRNA 5 Exon 1 Exon 2 RNA Processing • RNA Splicing can also be carried out by spliceosomes
Alternative Splicing (of Exons) • How is it possible that there are millions of human antibodies when there are only about 30,000 genes? • Alternative splicing refers to the different ways the exons of a gene may be combined, producing different forms of proteins within the same gene-coding region • Alternative pre-mRNA splicing is an important mechanism for regulating gene expression in higher eukaryotes
Gene DNA Exon 1 Exon 2 Intron Exon 3 Intron Transcription RNA processing Translation Domain 3 Domain 2 Domain 1 Polypeptide RNA Processing • Proteins often have a modular architecture consisting of discrete structural and functional regions called domains • In many cases different exons code for the different domains in a protein Figure 17.12
DNA TRANSCRIPTION mRNA Ribosome TRANSLATION Polypeptide Amino acids Polypeptide tRNA with amino acid attached Ribosome Trp Phe Gly tRNA C C C G G Anticodon A A A A G G G U G U U U C Codons 5 3 mRNA Translation • Translation is the RNA-directed synthesis of a polypeptide • Translation involves • mRNA • Ribosomes - Ribosomal RNA • Transfer RNA • Genetic coding - codons
Gene 2 DNA molecule Gene 1 Gene 3 DNA strand (template) 5 3 A C C T A A A C C G A G TRANSCRIPTION A U C G C U G G G U U U 5 mRNA 3 Codon TRANSLATION Gly Protein Phe Trp Ser Amino acid The Genetic Code • Genetic information is encoded as a sequence of nonoverlapping base triplets, or codons • The gene determines the sequence of bases along the length of an mRNA molecule
The Genetic Code • Codons: 3 base code for the production of a specific amino acid, sequence of three of the four different nucleotides • Since there are 4 bases and 3 positions in each codon, there are 4 x 4 x 4 = 64 possible codons • 64 codons but only 20 amino acids, therefore most have more than 1 codon • 3 of the 64 codons are used as STOP signals; they are found at the end of every gene and mark the end of the protein • One codon is used as a START signal: it is at the start of every protein • Universal: in all living organisms
Second mRNA base U C A G U UAU UUU UCU UGU Tyr Cys Phe UAC UUC UCC UGC C U Ser UUA UCA UAA Stop Stop UGA A Leu UAG UUG UCG Stop UGG Trp G CUU CCU U CAU CGU His CUC CCC CAC CGC C C Arg Pro Leu CUA CCA CAA CGA A Gln CUG CCG CAG CGG G Third mRNA base (3 end) First mRNA base (5 end) U AUU ACU AAU AGU Asn Ser C lle AUC ACC AAC AGC A Thr A AUA ACA AAA AGA Lys Arg Met or start G AUG ACG AAG AGG U GUU GCU GAU GGU Asp C GUC GCC GAC GGC G Val Ala Gly GUA GCA GAA GGA A Glu GUG GCG GAG GGG G The Genetic Code • A codon in messenger RNA is either translated into an amino acid or serves as a translational start/stop signal
3 A Amino acid attachment site C C 5 A C G C G C G U G U A A U U A U C G * G U A C A C A * A U C C * G * U G U G G * G A C C G * C A G * U G * * G A G C Hydrogen bonds (a) Two-dimensional structure. The four base-paired regions and three loops are characteristic of all tRNAs, as is the base sequence of the amino acid attachment site at the 3 end. The anticodon triplet is unique to each tRNA type. (The asterisks mark bases that have been chemically modified, a characteristic of tRNA.) G C U A G * A * A C * U A G A Anticodon Transfer RNA • Consists of a single RNA strand that is only about 80 nucleotides long • Each carries a specific amino acid on one end and has an anticodon on the other end • A special group of enzymes pairs up the proper tRNA molecules with their corresponding amino acids. • tRNA brings the amino acids to the ribosomes, The “anticodon” is the 3 RNA bases that matches the 3 bases of the codon on the mRNA molecule
Amino acid attachment site 5 3 Hydrogen bonds A A G 3 5 Anticodon Anticodon (c) Symbol used in the book (b) Three-dimensional structure Transfer RNA • 3 dimensional tRNA molecule is roughly “L” shaped
DNA TRANSCRIPTION mRNA Ribosome TRANSLATION Polypeptide Exit tunnel Growing polypeptide tRNA molecules Large subunit E P A Small subunit 5 3 mRNA Computer model of functioning ribosome. This is a model of a bacterial ribosome, showing its overall shape. The eukaryotic ribosome is roughly similar. A ribosomal subunit is an aggregate of ribosomal RNA molecules and proteins. (a) Ribosomes • Ribosomes facilitate the specific coupling of tRNA anticodons with mRNA codons during protein synthesis • The 2 ribosomal subunits are constructed of proteins and RNA molecules named ribosomal RNA or rRNA
P site (Peptidyl-tRNA binding site) A site (Aminoacyl- tRNA binding site) E site (Exit site) Large subunit E P A mRNA binding site Small subunit Schematic model showing binding sites. A ribosome has an mRNA binding site and three tRNA binding sites, known as the A, P, and E sites. This schematic ribosome will appear in later diagrams. (b) Ribosome • The ribosome has three binding sites for tRNA • The P site • The A site • The E site
Growing polypeptide Amino end Next amino acid to be added to polypeptide chain tRNA 3 mRNA Codons 5 (c) Schematic model with mRNA and tRNA. A tRNA fits into a binding site when its anticodon base-pairs with an mRNA codon. The P site holds the tRNA attached to the growing polypeptide. The A site holds the tRNA carrying the next amino acid to be added to the polypeptide chain. Discharged tRNA leaves via the E site. Building a Polypeptide
ATP loses two P groups and joins amino acid as AMP. 2 3 Appropriate tRNA covalently Bonds to amino Acid, displacing AMP. 4 Activated amino acid is released by the enzyme. Building a Molecule of tRNA • A specific enzyme called an aminoacyl-tRNA synthetase joins each amino acid to the correct tRNA Amino acid Aminoacyl-tRNA synthetase (enzyme) Active site binds the amino acid and ATP. 1 Adenosine P P P ATP Adenosine P Pyrophosphate P Pi Pi Pi Phosphates tRNA Adenosine P AMP Aminoacyl tRNA (an “activated amino acid”) Figure 17.15
Building a Polypeptide • We can divide translation into three stages • Initiation • Elongation • Termination • The AUG start codon is recognized by methionyl-tRNA or Met • Once the start codon has been identified, the ribosome incorporates amino acids into a polypeptide chain • RNA is decoded by tRNA (transfer RNA) molecules, which each transport specific amino acids to the growing chain • Translation ends when a stop codon (UAA, UAG, UGA) is reached
Large ribosomal subunit P site 5 3 U C A Met Met 3 A 5 G U Initiator tRNA GDP GTP E A mRNA 5 5 3 3 Start codon mRNA binding site Small ribosomal subunit Translation initiation complex 2 1 The arrival of a large ribosomal subunit completes the initiation complex. Proteins called initiation factors (not shown) are required to bring all the translation components together. GTP provides the energy for the assembly. The initiator tRNA is in the P site; the A site is available to the tRNA bearing the next amino acid. A small ribosomal subunit binds to a molecule of mRNA. In a prokaryotic cell, the mRNA binding site on this subunit recognizes a specific nucleotide sequence on the mRNA just upstream of the start codon. An initiator tRNA, with the anticodon UAC, base-pairs with the start codon, AUG. This tRNA carries the amino acid methionine (Met). Initiation of Translation • The initiation stage of translation brings together mRNA, tRNA bearing the first amino acid of the polypeptide, and two subunits of a ribosome
1 Codon recognition. The anticodon of an incoming aminoacyl tRNA base-pairs with the complementary mRNA codon in the A site. Hydrolysis of GTP increases the accuracy and efficiency of this step. Amino end of polypeptide DNA TRANSCRIPTION mRNA Ribosome TRANSLATION Polypeptide E mRNA 3 Ribosome ready for next aminoacyl tRNA P A site site 5 GTP 2 GDP 2 E E P A P A 2 Peptide bond formation. An rRNA molecule of the large subunit catalyzes the formation of a peptide bond between the new amino acid in the A site and the carboxyl end of the growing polypeptide in the P site. This step attaches the polypeptide to the tRNA in the A site. GDP Translocation. The ribosome translocates the tRNA in the A site to the P site. The empty tRNA in the P site is moved to the E site, where it is released. The mRNA moves along with its bound tRNAs, bringing the next codon to be translated into the A site. 3 GTP E P A Elongation of the Polypeptide Chain • In the elongation stage, amino acids are added one by one to the preceding amino acid
Release factor Free polypeptide 5 3 3 3 5 5 Stop codon (UAG, UAA, or UGA) The release factor hydrolyzes the bond between the tRNA in the P site and the last amino acid of the polypeptide chain. The polypeptide is thus freed from the ribosome. When a ribosome reaches a stop codon on mRNA, the A site of the ribosome accepts a protein called a release factor instead of tRNA. The two ribosomal subunits and the other components of the assembly dissociate. 2 1 3 Termination of Translation • The final step in translation is termination. When the ribosome reaches a STOP codon, there is no corresponding transfer RNA. • Instead, a small protein called a “release factor” attaches to the stop codon. • The release factor causes the whole complex to fall apart: messenger RNA, the two ribosome subunits, the new polypeptide. • The messenger RNA can be translated many times, to produce many protein copies.
Translation: Initiation • mRNA binds to a ribosome, and the transfer RNA corresponding to the START codon binds to this complex. Ribosomes are composed of 2 subunits (large and small), which come together when the messenger RNA attaches during the initiation process.
Translation: Elongation • Elongation: the ribosome moves down the messenger RNA, adding new amino acids to the growing polypeptide chain. • The ribosome has 2 sites for binding transfer RNA. The first RNA with its attached amino acid binds to the first site, and then the transfer RNA corresponding to the second codon bind to the second site.
Translation: Elongation • The ribosome then removes the amino acid from the first transfer RNA and attaches it to the second amino acid. • At this point, the first transfer RNA is empty: no attached amino acid, and the second transfer RNA has a chain of 2 amino acids attached to it.
Translation: Termination • The elongation cycle repeats as the ribosome moves down the messenger RNA, translating it one codon and one amino acid at a time. • The process repeats until a STOP codon is reached.
Completed polypeptide Growing polypeptides Incoming ribosomal subunits Start of mRNA (5 end) Polyribosome End of mRNA (3 end) An mRNA molecule is generally translated simultaneously by several ribosomes in clusters called polyribosomes. (a) Ribosomes mRNA 0.1 µm This micrograph shows a large polyribosome in a prokaryotic cell (TEM). Polyribosomes • A number of ribosomes can translate a single mRNA molecule simultaneously forming a polyribosome • Polyribosomes enable a cell to make many copies of a polypeptide very quickly
RNA polymerase DNA mRNA Polyribosome Direction of transcription 0.25 mm RNA polymerase DNA Polyribosome Polypeptide (amino end) Ribosome mRNA (5¢ end) Comparing Gene Expression In Prokaryotes And Eukaryotes • In a eukaryotic cell: • The nuclear envelope separates transcription from translation • Extensive RNA processing occurs in the nucleus • Prokaryotic cells lack a nuclear envelope, allowing translation to begin while transcription progresses
DNA TRANSCRIPTION 1 3 4 2 5 RNA is transcribed from a DNA template. 3 Poly-A RNA transcript RNA polymerase 5 Exon RNA PROCESSING In eukaryotes, the RNA transcript (pre- mRNA) is spliced and modified to produce mRNA, which moves from the nucleus to the cytoplasm. RNA transcript (pre-mRNA) Intron Aminoacyl-tRNA synthetase Cap NUCLEUS Amino acid FORMATION OF INITIATION COMPLEX AMINO ACID ACTIVATION tRNA CYTOPLASM After leaving the nucleus, mRNA attaches to the ribosome. Each amino acid attaches to its proper tRNA with the help of a specific enzyme and ATP. Growing polypeptide mRNA Activated amino acid Poly-A Poly-A Ribosomal subunits Cap 5 TRANSLATION C C A U A succession of tRNAs add their amino acids to the polypeptide chain as the mRNA is moved through the ribosome one codon at a time. (When completed, the polypeptide is released from the ribosome.) A E A C Anticodon A A A U G U G G U U U A Codon Ribosome A summary of transcription and translation in a eukaryotic cell Figure 17.26
Post-translation • The new polypeptide is now floating loose in the cytoplasm if translated by a free ribosome. • Polypeptides fold spontaneously into their active configuration, and they spontaneously join with other polypeptides to form the final proteins. • Often translation is not sufficient to make a functional protein, polypeptide chains are modified after translation • Sometimes other molecules are also attached to the polypeptides: sugars, lipids, phosphates, etc. All of these have special purposes for protein function.
Targeting Polypeptides to Specific Locations • Completed proteins are targeted to specific sites in the cell • Two populations of ribosomes are evident in cells: free ribsomes (in the cytosol) and bound ribosomes (attached to the ER) • Free ribosomes mostly synthesize proteins that function in the cytosol • Bound ribosomes make proteins of the endomembrane system and proteins that are secreted from the cell • Ribosomes are identical and can switch from free to bound
Ribosomes mRNA Signal peptide ER membrane Signal- recognition particle (SRP) Signal peptide removed Protein SRP receptor protein CYTOSOL Translocation complex ER LUMEN Targeting Polypeptides to Specific Locations • Polypeptide synthesis always begins in the cytosol • Synthesis finishes in the cytosol unless the polypeptide signals the ribosome to attach to the ER • Polypeptides destined for the ER or for secretion are marked by a signal peptide • A signal-recognition particle (SRP) binds to the signal peptide • The SRP brings the signal peptide and its ribosome to the ER
Mutation Causes and Rate • The natural replication of DNA produces occasional errors. DNA polymerase has an editing mechanism that decreases the rate, but it still exists • Typically genes incur base substitutions about once in every 10,000 to 1,000,000 cells • Since we have about 6 billion bases of DNA in each cell, virtually every cell in your body contains several mutations • Mutations can be harmful, lethal, helpful, silent • However, most mutations are neutral: have no effect • Only mutations in cells that become sperm or eggs—are passed on to future generations • Mutations in other body cells only cause trouble when they cause cancer or related diseases
Mutagens • Mutagens are chemical or physical agents that interact with DNA to cause mutations. • Physical agents include high-energy radiation like X-rays and ultraviolet light • Chemical mutagens fall into several categories. • Chemicals that are base analogues that may be substituted into DNA, but they pair incorrectly during DNA replication. • Interference with DNA replication by inserting into DNA and distorting the double helix. • Chemical changes in bases that change their pairing properties. • Tests are often used as a preliminary screen of chemicals to identify those that may cause cancer • Most carcinogens are mutagenic and most mutagens are carcinogenic.
Viral Mutagens • Scientists have recognized a number of tumor viruses that cause cancer in various animals, including humans • About 15% of human cancers are caused by viral infections that disrupt normal control of cell division • All tumor viruses transform cells into cancer cells through the integration of viral nucleic acid into host cell DNA.
Point mutations • Point mutations involve alterations in the structure or location of a single gene. Generally, only one or a few base pairs are involved. • Point mutations can signficantly affect protein structureandfunction • Point mutations may be caused by physical damage to the DNA from radiation or chemicals, or may occur spontaneously • Point mutations are often caused by mutagens
Wild-type hemoglobin DNA Mutant hemoglobin DNA In the DNA, the mutant template strand has an A where the wild-type template has a T. 3 5 3 5 T T C A T C mRNA mRNA The mutant mRNA has a U instead of an A in one codon. G A A U A G 5 3 5 3 Normal hemoglobin Sickle-cell hemoglobin The mutant (sickle-cell) hemoglobin has a valine (Val) instead of a glutamic acid (Glu). Val Glu Point Mutation • The change of a single nucleotide in the DNA’s template strand leads to the production of an abnormal protein
Types of Point Mutations • Point mutations within a gene can be divided into two general categories • Base-pair substitutions - is the replacement of one nucleotide and its partner with another pair of nucleotides • Base-pair insertions or deletions - are additions or losses of nucleotide pairs in a gene
Wild type A A G G G G A U U U C U A A U mRNA 5 3 Lys Protein Met Phe Gly Stop Amino end Carboxyl end Base-pair substitution No effect on amino acid sequence U instead of C A U G A A G U U U G G U U A A Lys Met Phe Gly Stop Missense A instead of G A A U G A A G U U U A G U U A Lys Met Phe Ser Stop Nonsense U instead of A G A A G G U U G A A U U U U C Met Stop Base-Pair Substitutions • Silent - changes a codon but codes for the same amino acid • Missense - substitutions that change a codon for one amino acid into a codon for a different amino acid • Nonsense -substitutions that change a codon for one amino acid into a stop codon