Download

1 / 34
340 likes | 492 Views
An FPGA Implementation of the Ewald Direct Space and Lennard-Jones Compute Engines. By: David Chui Supervisor: Professor P. Chow. Overview. Introduction and Motivation Background and Previous Work Hardware Compute Engines Results and Performance Conclusions and Future Work.

E N D
An FPGA Implementation of theEwald Direct Space and Lennard-JonesCompute Engines By: David Chui Supervisor: Professor P. Chow
Overview • Introduction and Motivation • Background and Previous Work • Hardware Compute Engines • Results and Performance • Conclusions and Future Work
What is Molecular Dynamics (MD) simulation? • Biomolecular simulations • Structure and behavior of biological systems • Uses classical mechanics to model a molecular system • Newtonian equations of motion (F = ma) • Compute forces and integrate acceleration through time to move atoms • A large scale MD system takes years to simulate
Motivation • Special-purpose computers for MD simulation have become an interesting application • FPGA technology • Reconfigurable • Low cost for system prototype • Short turn around time and development cycle • Latest technology • Design portability
Objectives • Implement the compute engines on FPGA • Calculate the non-bonded interactions in an MD simulation (Lennard-Jones and Ewald Direct Space) • Explore the hardware resources • Study the trade-off between hardware resources and computational precision • Analyze the hardware pipeline performance • Become the components of a larger project in the future
Lennard-Jones Potential • Attraction due to instantaneous dipole of molecules • Pair-wise non-bonded interactions O(N2) • Short range force • Use cut-off radius to reduce computations • Reduced complexity close to O(N)
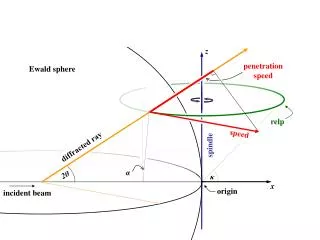
Electrostatic Potential • Attraction and repulsion due to electrostatic charge of particles (long range force) • Reformulate using Ewald Summation • Decompose to Direct Space and Reciprocal Space • Direct Space computation similar to Lennard-Jones • Direct Space complexity close to O(N)
Recent work - FPGA based MD simulator Transmogrifier-3 FPGA system • University of Toronto (2003) • Estimated speedup of over 20 times over software with better hardware resources • Fixed-point arithmetic, function table lookup, and interpolation Xilinx Virtex-II Pro XC2VP70 FPGA • Boston University (2005) • Achieved a speedup of over 88 times over software • Fixed-point arithmetic, function table lookup, and interpolation
MD Simulation software - NAMD • Parallel runtime system (Charm++/Converse) • Highly scalable • Largest system simulated has over 300,000 atoms on 1000 processors • Spatial decomposition • Double precision floating point
Purpose and Design Approach • Implement the functionality of the software compute object • Calculate the non-bonded interactions given the particle information • Fixed-point arithmetic, function table lookup, and interpolation • Pipelined architecture
Function Lookup Table • The function to be looked up is a function of |r|2 (the separation distance between a pair of atoms) • Block floating point lookup • Partition function based on different precision
Simulation Overview • Software model • Different coordinate precisions and lookup table sizes • Obtain the error compared to computation using double precision
Hardware Improvement Operating frequency: • Place-and-route constraints • More pipeline stages Throughput: • More hardware resources • Avoid sharing of multipliers
Compared with previous work • Pipelined adders and multipliers • Block floating point memory lookup • Support different types of atoms
Hardware Precision • A combination of fixed-point arithmetic, function table lookup, and interpolation can achieve high precision • Similar result in RMS energy fluctuation and average energy • Coordinate precision of {7.41} • Table lookup size of 1K • Block floating memory • Data precision maximized • Different types of functions
Hardware Performance • Compute engines operating frequency: • Ewald Direct Space 82.2 MHz • Lennard-Jones 80.0 MHz • Achieving 100 MHz is feasible with newer FPGAs
Future Work • Study different types of MD systems • Simulate computation error with different table lookup sizes and interpolation orders • Hardware usage: storing data in block RAMs instead of external ZBT memory