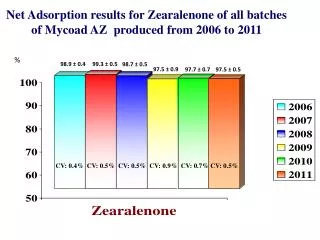
MACSio 0.9 Design and Current Capabilities
MACSio 0.9 Design and Current Capabilities. LLNL Internal Review. June 2015. Mark C. Miller. What is MACSio?. Multi-purpose Application-Centric Scalable i/o Proxy Application We aim to use it to MACS-imize I/O performance. L2 Milestone Description.


MACSio 0.9 Design and Current Capabilities
E N D
Presentation Transcript
MACSio 0.9Design and Current Capabilities LLNL Internal Review • June 2015 • Mark C. Miller
What is MACSio? • Multi-purpose • Application-Centric • Scalable i/o • Proxy Application We aim to use it to MACS-imize I/O performance
L2 Milestone Description This milestone will fill a gap in the DOE co-design space by developing a proxy application on which various parallel I/O methods and libraries can be easily tested and studied for scalability, performance impacts of software abstractions, impact of techniques such as compression or checksumming, and the use of burst buffers. The core of the application will be common system for generating collections of data structures (e.g. arrays [float|double|int], strings, key/value pairs) that in aggregate closely mimic the checkpoint data of real applications. Generation of the data will be user-definable through fully parameterized attributes for the types, quantity, lengths, and randomness of data. A plug-in architecture will be designed to allow users to study different I/O libraries (e.g. HDF5 vs netCDF), parallel I/O techniques (e.g. file-per-processor vs collective), and support for burst buffers (e.g. SCR).
L2 Milestone Completion Criteria • A functional proxy app with abstractions to support at least two I/O libraries commonly used at the ASC labs is demonstrated, and initial feedback sought from the broader community. • Silo (r/w), HDF5 (w), Exodus (w), Raw Posix (w) • Full documentation on how the proxy app can be extended to support new plug-ins. • Doxygenated sources and examples + design docs • A report (white paper or presentation) is delivered describing the proxy app, and reporting on performance results gathered through its use on at least two platforms (e.g. TLCC2 and Sequoia with Lustre). • Design Doc + This presentation
Why an I/O Proxy App is Needed • Existing “Benchmarks” are limited in scope • More on that in a later slide • Whole apps and app kernels are often inflexible • Often ignore I/O entirely • Able to test only one specific way of doing I/O • Measuring and diagnosing I/O performance is complicated • I/O Stack and level of abstraction • File systems are getting more complex • There are a myriad of options • Aim to evaluate a variety of I/O relevant options • HDF5 vs. netCDF (+ params within each lib) • Overhead of Silo on HDF5 or Exodus on netCDF • Collective vs. Independent • Different parallel I/O paradigms • hzip vs. szip vs. no-compression (of realistic data) • Burst buffers
Common Parallel I/O Paradigms • Single, Shared File (SSF), Aka “N:1”, “Rich Mans” • Concurrent access to a single, shared file • Requires a “true” parallel file system • Sometimes further divided into strided and segmented • My take: These terms suggest granularity of different MPI rank’s data co-mingling in file • Often a challenge to get good, scalable performance • Best for academic, single physics, homogeneous, and/or structured, array codes • Multiple Independent File (MIF), Aka “N:M”, “Poor Mans” • Concurrent (app-managed) access to multiple files • File count independent of MPI comm size • Easier than SSF to get good, scalable performance • Best for multi-physics, heterogeneous, and/or unstructured mesh codes • File Per Processor (FPP), Aka “N:N” • Really just a special case of MIF (but also very common) • At extreme scale, places huge demand on file system metadata • Sometimes need “throttling” knob (number of simultaneous files) • Collective vs. Independent I/O Requests • Possible within any paradigm but collective typical/easiest with SSF
Mutiple Indep. File 0 Proc File 4 Proc File 3 Proc File 2 Proc File 1 Proc File 0 Mutiple Indep. File 1 Single Shared File Collective SSF (N:1) (strided shown) Independent P0 P2 P1 P3 P4 P0 P2 P1 P3 P4 P0 P2 P3 P4 P1 MIF (N:M) FPP (N:N)
Why codes do I/O? • Restart • Save state of code to restart it at a later time • Protect cost to re-compute against various failures • Other aspects • Precision: Full, typically cannot tolerate loss • Extent of content: Everything needed to successfully restart the code • Frequency: MTBF, re-compute cost & user tolerance • Longevity: short, often never migrated to main file system (SCR) • Portability (of data/files): Only writer needs to read it (not always)and often only on same platform • Analysis (AKA: plot, post-process, presentation, movies, etc.) • Save only key mesh(s) & var(s) from code essential to analysis • Other aspects: • Precision: Single, often can tolerate loss • Extent of content: Only those data objects needed for the down-stream analysis • Frequency: varies widely, governed by down-stream presentation/analysis needs • Longevity: Can be years/decades, always migrated to main file system • Portability (of data/files): Across many tools, platforms, file systems, versions of I/O libs and years of use leads to the need for useful data abstractions
Notes to Self and What They Teach us about the HPC I/O Stack • When I write a note I never expect anyone else to read • Often, result is something lik this... • Sadly, if too much time passes, I can’t even read it myself ;) • Moral: Writing stuff you want others to read requires • care • common conventions • mutually agreed upon terms • formalisms • data models and abstractions • “others”=“self” a year from now
Level of Abstraction (LOA)and the HPC I/O Stack Picture includes levels we don’t often think of as part of HPC I/O stack Increasing LOA
The HPC I/O Stack is similar toIP Protocol Stack Increasing LOA
Level of Abstraction (LOA)and the HPC I/O Stack Increasing LOA
Level of Abstraction (LOA)and the HPC I/O Stack Increasing LOA
LOA of Existing Benchmarking Tools Increasing LOA Fewer Tools ManyTools
LOA of MACSio Increasing LOA MACSio Existing Tools
Evaluation of Existing Benchmarks • LOA=Level of Abstraction • PMode=Parallel Mode • SSF=Single Shared File • MIF=Multiple Independent File • FPP=file per processor • Coll=Collective I/Os • Abs Keep=Abstraction Preserving? • DIT=Data in transit services • precision, cksum, compress, re-order... • MPI+=MPI+MC/OpenMP/Threads • Perf DB=Performance Database • EZ-Extend (how hard to add) • Parallel Mode, I/O library, X in MPI+X
Simple Questions, Hard to Answer • What I/O performance will application X see on platform Y? • What overhead does Silo cost over HDF5? • Can collective I/O to SSF achieve better performance than MIF? • How much will compression algorithm X improve performance? • Why does HDF5 with >10000 groups hit a wall? • Application A writes 100 Gb/s via stdio, why are we seeing only 1 Gb/s with library B?
Notional I/O Performance Overheads @ this request size 20% Disk hardware limit { I/O Bandwidth { { % of dump request from somewherein stack Raw Lustre Down HPC I/O Stack request from app HDF5 Silo Request Size
Useful Features of an I/O Proxy Appand how MACSio addresses them • Easy scaling of data sizes • Physically realistic data, Not all zeros/random() • Variety of I/O libraries • Various I/O Paradigms • Data Validation • Able to drive DIT services • Able to drive variety & mix of I/O loads • Easy Timing/Logging • Integrate with other tools • Mesh part size & # parts/rank • Variable exprs+ noise, Vary size, shapeacross rank • Plugins: HDF5, Silo, Exodus... • SSF, MIF, FPP, coll./indep. • Use plugin reader + cksums • float conv., compress, cksum, etc. • Restart/plot, movie, linker, time-histories • Timing and logging classes • SCR, VisIt, Darshan, Caliper
Perlin Noise or some other Chaotic Process for Numerically Similar Data • Images above are variations on Ken Perlin’s procedural texture algorithms • Metric: It kinda looks like stuff HPC generates
How MACSio 0.9 Operates • Very simple mesh + variable generation • Vars are expressions over global spatial extents box • Very simple decomp of mesh across MPI ranks • Different ranks can have different # of mesh parts • Currently, individual parts are all same size • Should add option for randomization around nominal size • Static plugins linked into MACSio @ link time • All methods in a plugin are file-scope static • MACSio main gets pointers to key methods during init • Uses modified JSON-C library for marshaling data between MACSio and plugins • Opted for JSON-C to support Fortran plugins
MACSio’s Main Object (Dictionary) {“clargs”:<clarg-obj>, “parallel”: {“mpi_size”:<int>, “mpi_rank”:<int>}, “global_mesh”: {“num_parts”:<int>, “bounds”: [<dbl>,<dbl>,<dbl>,<dbl>,<dbl>,<dbl>]}, “local_mesh”: [<part-obj>,<part-obj>,...] }
MACSio’s Main Object (Dictionary) "Mesh": { "MeshType": "rectilinear", "ChunkID": 0, # unique per part "GeomDim": 2, "TopoDim": 2, "LogDims": [50,100], "Bounds": [0,0,0,1,1,0], "Coords": { "CoordBasis": "X,Y,Z", "XAxisCoords": [...], "YAxisCoords": [...] }, "Topology": { "Type": "Templated", "DomainDim": 2, "RangeDim": 0, "ElemType": "Quad4", "Template": [0,1,51,50] } }, "Vars": [ {...}, {...}, { "name": "spherical", "centering": "zone", "data": [...] }, {...}, {...}, {...} ], "GlobalLogIndices": [...], "GlobalLogOrigin": [...] } Would like to use VisIt’s/LibSim2 Metadata
JSON Data object constructed on all processors • Global parts are identical across ranks • Local parts are specific to each rank • No communication involved (yet) • Once generated, call plugin’s Dump method /* do the dump */ (*(iface->dumpFunc))(argi, argc, argv, main_obj, dumpNum, dumpTime);
MACSio Plugin Operation • Traverse main JSON-C object • Query for various metadata rank = JsonGetInt(main_obj, "parallel/mpi_rank"); size = JsonGetInt(main_obj, "parallel/mpi_size"); intndims = JsonGetInt(part, "Mesh/GeomDim"); • Decide equivalent object for plugin to write • For rect mesh & Silo, DBPutQuadmesh/DBPutQuadvar • Convert where necessary (time apart from i/o) • Output the data (time as i/o)
MACSio Logging • For events, diagnotics, debugging, etc. • Single row & column formatted ascii file • Default #cols is 128 but settable on CL • Default #rows per mpi is 64 but settable on CL • Each rank’s section acts like a circular queue • Can loose messages but always have most recent N prior to a serious issue
Sample usage • mpirun –np 4 macsio –interface silo • defaults to write, 1 part per rank, 1 file per processor (MIF), 80000 byte requests, 10 dumps • mpirun –np 4 macsio–parallel_file_mode MIF 3 –part_size 1M \ –avg_num_parts 2.5 –interface hdf5 • each mesh part is 1Mb, 10 dumps to 3 MIF files using HDF5 interface • mpirun –np 4 macsio –interface hdf5 \ –parallel_file_mode SIF –plugin-args–compression gzip level=9 • mpirun –np 4 macsio –read_pathfoo.silo • Have attempted to make Silo read general enough to read any code’s restart/plot • mpirun –np 4 macsio –interface exodus –plugin_args \ –use_large_model always • mpirun –np 4 macsio –interface hdf5 –meta_type tabular \--meta_size5M 20M
MACSio Examples • 4 processors, avg_num_parts = 2.5, tot=10 parts • Silo output • Showing spherical, sinusoid and random vars
Parts vs. Ranks • avg_num_parts=2.5 • Some ranks get 2 • Some ranks get 3 • Minor bug: • More realistic if middle row parts were swapped
A note about SI Prefixes • How many bytes in a “Kilo”-byte? • Does “Kilo” mean 1000 or 1024? • 2.4% error for “Kilo” ~10% error for “Tera” • International ElectrotechnicalCommission (IEC) • “Decimal” prefixes (1000 bytes), Kb, Mb, Gb, Tb, Pb • “Binary” prefixes (1024 bytes), Ki, Mi, Gi, Ti, Pi • Kibibyte, Mebibyte, Gibibyte, Tebibyte, Pebibyte. • MACSio will use either (default is Binary) • --units_prefix_systemCL argument
Initial Performance DataCollection Missteps • srun –n and –N argument confusion • Silo BG-optimized VFD not getting used • default setting for “bgp” and “bgl” but no “bgq” • Not going to large enough request sizes • Not getting enough resources for largest runs • What is better measure for aggregate BW? • Sum of each BW observed at each task? • Total bytes / (Last Finisher’s Time – First start’s Time) • This is generally 10-20% lower
About MACSio • Currently all C and uses GMake • MACSio main + utils: ~4500 lines (including doc) • MACSio plugins • Silo: ~900 lines • HDF5: ~600 lines • Exodus: ~600 lines • Raw-Posix: ~350 lines • Its currently called the “miftmpl” for MIF Template
MACSio Availability & Next Steps • Currently on LLNL CZ Git/Stash • Can give permission to anyone with LLNL CZ Token • BSD Open Source Release in progress • Expected BSD release end of June • Put up link on codesign.llnl.gov • Maybe “mirror” on GitHub or (suggestions) • Volunteers for new plugins? Users? • Contact: miller86@llnl.gov
Next Steps • Short Term: • Mark to continue support/development but taper down • Medium Term: • Shift responsibilities to a dedicated proxy app team • Long Term: • Evolve to a true community open source project
L2 Milestone Description This milestone will fill a gap in the DOE co-design space by developing a proxy application on which various parallel I/O methods and libraries can be easily tested and studied for scalability, performance impacts of software abstractions, impact of techniques such as compression or checksumming, and the use of burst buffers. The core of the application will be common system for generating collections of data structures (e.g. arrays [float|double|int], strings, key/value pairs) that in aggregate closely mimic the checkpoint data of real applications. Generation of the data will be user-definable through fully parameterized attributes for the types, quantity, lengths, and randomness of data. A plug-in architecture will be designed to allow users to study different I/O libraries (e.g. HDF5 vs netCDF), parallel I/O techniques (e.g. file-per-processor vs collective), and support for burst buffers (e.g. SCR).
L2 Milestone Completion Criteria • A functional proxy app with abstractions to support at least two I/O libraries commonly used at the ASC labs is demonstrated, and initial feedback sought from the broader community. • Silo (r/w), HDF5 (w), Exodus (w), Raw Posix (r/w) • Full documentation on how the proxy app can be extended to support new plug-ins. • Doxygenated sources and examples + design docs • A report (white paper or presentation) is delivered describing the proxy app, and reporting on performance results gathered through its use on at least two platforms (e.g. TLCC2 and Sequoia with Lustre). • Design Doc + This presentation
Thanks • Rob Neely and Chris Clouse • For funding me to work on this • Eric Brugger and Cyrus Harrison • For allowing me time away from my other responsibilities