boyer moore
E N D
Presentation Transcript
KISHKINDA UNIVERSITY FACULTY OF ENGINEERING AND TECHNOLOGY DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING MTech-First Semester Seminar Report on “Boyer Moore Algorithm“ Submitted by Name: P Sahana Prasad Registration ID: KUB24MCS015 Under the Guidance of Mr. G Vannurswamy Associate Professor Department of Computer Science and Engineering Kishkinda University Main Campus Mount View Campus, Off 28Kms, Ballari - Siruguppa Road, Near Sindhigeri, GP NO.735, Hagaluru, Siruguppa Taluk, Ballari - 583120, Karnataka
KISHKINDA UNIVERSITY FACULTY OF ENGINEERING AND TECHNOLOGY(FET) DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING CERTIFICATE This is to certify that the SEMINAR entitled “ Boyer Moore Algorithm” has been successfully presented by P Sahana Prasad bearing USN KUB24MCS015 a student of I semester M. Tech for the partial fulfillment of the requirements for the Master Degree in Computer Science & Engineering of the KISHKINDA UNIVERSITY during the academic year 2024-2025. Mr. G Vannurswamy Assistant Professor Dept of Computer Science and Engineering Kishkinda University Dr. Rajashree V Biradar Chairperson Dept of Computer Science and Engineering Kishkinda University
ACKNOWLEDGEMENT It is my privilege and primary duty to express my gratitude and respect to all those who guided and inspired me in successful completion of this Seminar. I express my sincere thanks to Dr. Rajashree V Biradar, chairperson of Kishkinda University, Ballari. Mr. G Vannuswamy Assistant Professor & teaching & non-teaching staff of the Department of Computer Science and Engineering for their cooperation in completion of the Seminar and Management of Kishkinda University College, Ballari for providing the facilities to carry out the Seminar. Lastly, I would like to express my gratitude to all those who have directly or indirectly contributed their efforts in making Seminar a success. P Sahana Prasad KUB24MCS015
Table of Contents S.no Chapter Page no. Acknowledgement I 1 Introduction 1 2 Algorithm Description 2-3 3 Applications of Boyer Moore Algorithm 4 4 Implementation of Boyer Moore Algorithm 5-6 5 Conclusion
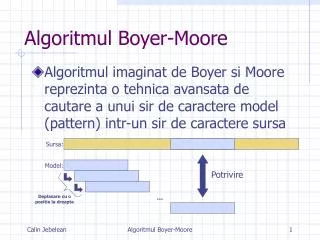
Boyer Moore algorithm 2024 Chapter 1 INTRODUCTION The Boyer-Moore algorithm is a highly efficient string-searching technique designed to find a pattern within a text by comparing the pattern to the text from right to left, rather than the typical left to right. It uses two main heuristics to improve search efficiency: the bad-character heuristic and the good-suffix heuristic. The bad-character heuristic shifts the pattern based on mismatches between the pattern and the text, allowing the pattern to skip over parts of the text where no match is possible. The good-suffix heuristic, on the other hand, uses the portion of the pattern that has already matched to shift the pattern more efficiently, ensuring that no unnecessary comparisons are made. As a result, the algorithm often avoids many comparisons and can skip ahead in the text significantly, making it faster than simpler algorithms like the naive approach and Knuth-Morris- Pratt (KMP) in practical use. Although the worst-case time complexity is O(n * m), where n is the length of the text and m is the length of the pattern, the average case is typically much better, making Boyer-Moore one of the most effective algorithms for searching long patterns in large texts. The bad-character heuristic shifts the pattern based on mismatches, ensuring that the pattern skips over parts of the text where no match is possible. In the event of a partial match, the good-suffix heuristic shifts the pattern based on the portion of the pattern that has already matched, further minimizing the need for redundant comparisons. These two heuristics work together to significantly reduce the number of character comparisons required, particularly when the pattern is long relative to the text. This efficiency makes it particularly useful for searching large texts with long patterns, such as in DNA sequence analysis, text processing, and pattern recognition tasks. DEPT OF CSE, KISHKINDA UNIVERSITY, BALLARI Page 1
Boyer Moore algorithm 2024 Chapter 2 ALGORITHM DESCRIPTION The Boyer-Moore algorithm is a right-to-left string-searching algorithm, meaning it compares the pattern (P) to the text (T) from the rightmost character of the pattern to the leftmost character, rather than from left to right. This right-to-left comparison is the key to the algorithm's efficiency. Steps in the Boyer-Moore Algorithm: 1.Initialization: oStart by aligning the pattern P with the beginning of the text T. oIf the length of the pattern is m and the length of the text is n, the initial alignment is at position i = 0, with the first character of P compared against the first character of T. 2.Pattern Comparison: oBegin comparing characters of the pattern P with the text T from right to left (i.e., compare the last character of P with the corresponding character of T). oIf there is a match, move one character to the left and continue comparing the next characters of P with the corresponding characters of T. oIf there is a mismatch, apply the bad-character heuristic and/or good-suffix heuristic to determine how far the pattern can be shifted. 3.Bad-Character Heuristic (Mismatch Handling): oWhen a mismatch occurs, the bad-character heuristic helps determine the next position to align the pattern. This heuristic works as follows: Find the mismatched character in the text (let's call it T[i]). Check the pattern to see if the mismatched character exists in the pattern P. If it exists, shift the pattern such that the last occurrence of the mismatched character aligns with T[i]. If the mismatched character does not exist in the pattern at all, shift the pattern entirely past the mismatched character in the text (i.e., shift it by the length of the pattern). 4.Good-Suffix Heuristic (Partial Match Handling): oIf part of the pattern has already matched (e.g., part of the pattern before the mismatch), the good-suffix heuristic helps decide how to shift the pattern. This heuristic uses the longest suffix of the pattern that matches the text and shifts the pattern to align that suffix with another occurrence of the same suffix in the pattern (if it exists). If no such occurrence exists, shift the pattern by the largest possible amount that avoids unnecessary comparisons. DEPT OF CSE, KISHKINDA UNIVERSITY, BALLARI Page 2
Boyer Moore algorithm 2024 5.Repeat the Process: oAfter applying the heuristics, shift the pattern according to the calculated shifts and repeat the comparison from the new alignment. oContinue shifting and comparing until one of the following conditions is met: A match is found, and the position in the text where the pattern begins is recorded. The entire text is scanned, and no match is found. 6.Termination: oIf a match is found, the algorithm terminates and returns the position of the match. oIf the pattern cannot be found in the text, the algorithm terminates after scanning the entire text. DEPT OF CSE, KISHKINDA UNIVERSITY, BALLARI Page 3
Boyer Moore algorithm 2024 Chapter 3 APPLICATIONS OF BOYER MOORE ALGORITHM The Boyer-Moore algorithm is widely used in various applications due to its efficiency in searching for patterns within large texts. Some of the key applications include: 1.Text Search Engines: The Boyer-Moore algorithm is used in search engines and text editors to quickly find keywords or phrases within large documents or across websites. Its ability to skip over large sections of text makes it ideal for handling vast amounts of data. 2.DNA Sequence Analysis: In bioinformatics, Boyer-Moore is applied to search for specific gene sequences or motifs in DNA strings. This is crucial in tasks like gene alignment, mutation detection, and bioinformatics research, where large genomic datasets need to be analyzed for specific patterns. 3.Data Mining: Boyer-Moore is used in data mining tasks for pattern recognition in large datasets, including searching for patterns or anomalies within vast collections of data, such as logs or transactional data. 4.Pattern Recognition: In machine learning and computer vision, Boyer-Moore can be applied for detecting patterns or objects in images, particularly when searching for specific shapes, textures, or sequences in image data. 5.String Matching in Compilers: Boyer-Moore is utilized in compilers for lexical analysis, where it helps in identifying keywords, operators, or symbols within source code. Its efficiency ensures that syntax analysis can be performed quickly. 6.Antivirus Software: In antivirus programs, Boyer-Moore is used for searching virus signatures or known malicious patterns in files and directories, enabling faster scanning of large numbers of files. 7.Text Processing Tools: It is widely used in text processing tools for performing operations like find-and-replace in large files or datasets, allowing for fast pattern searching and manipulation. 8.Digital Forensics: In digital forensics, the algorithm is used to search for specific keywords or patterns within digital evidence, helping investigators quickly locate important information in large datasets. 9.Compression Algorithms: Boyer-Moore can also be part of the search phase in some compression algorithms, helping identify repeated patterns that can be compressed efficiently. DEPT OF CSE, KISHKINDA UNIVERSITY, BALLARI Page 4
Boyer Moore algorithm 2024 Chapter 4 IMPLEMENTATION OF BOYER MOOR ALGORITHM Here's a basic Python implementation of the Boyer-Moore algorithm to search for a pattern in a given text. This implementation includes the Bad-Character Heuristic and the Good-Suffix Heuristic. Python Code: def bad_character_heuristic(pattern): """ Preprocess the pattern to create a bad character shift table. """ m = len(pattern) bad_char = {} for i in range(m): bad_char[pattern[i]] = i return bad_char def good_suffix_heuristic(pattern): """ Preprocess the pattern to create a good suffix shift table. """ m = len(pattern) good_suffix = [m] * (m + 1) last_prefix = [False] * (m + 1) # Mark all the suffixes that are prefixes for i in range(m): last_prefix[i] = pattern[:i+1] == pattern[m-i-1:] # Fill the good_suffix table j = 0 for i in range(m-1, -1, -1): if last_prefix[i]: good_suffix[j] = m - i - 1 j += 1 return good_suffix def boyer_moore_search(text, pattern): """ Boyer-Moore string search algorithm to find all occurrences of pattern in text. """ n = len(text) m = len(pattern) # Preprocess bad character and good suffix tables bad_char = bad_character_heuristic(pattern) good_suffix = good_suffix_heuristic(pattern) DEPT OF CSE, KISHKINDA UNIVERSITY, BALLARI Page 5
Boyer Moore algorithm 2024 # Search phase i = 0 while i <= n - m: j = m - 1 # Compare the pattern with the current text window from right to left while j >= 0 and pattern[j] == text[i + j]: j -= 1 if j == -1: # Match found print(f"Pattern found at index {i}") i += good_suffix[0] # Shift pattern by good suffix value else: # Use the bad character rule and good suffix rule to shift bad_char_shift = j - bad_char.get(text[i + j], -1) good_suffix_shift = good_suffix[j] # Shift pattern by the maximum of the two i += max(bad_char_shift, good_suffix_shift) # Example usage text = "ABABDABACDABABCABAB" pattern = "ABAB" boyer_moore_search(text, pattern) DEPT OF CSE, KISHKINDA UNIVERSITY, BALLARI Page 6
Boyer Moore algorithm 2024 Demo Photograph DEPT OF CSE, KISHKINDA UNIVERSITY, BALLARI Page 7
Boyer Moore algorithm 2024 CONCLUSION The Boyer-Moore algorithm stands out as one of the most efficient string-searching algorithms due to its ability to skip over large sections of the text and reduce the number of character comparisons. This is in stark contrast to simpler approaches, like the naive search algorithm, which checks each character of the pattern one by one in the text. By using the bad-character and good- suffix heuristics, Boyer-Moore often performs fewer comparisons, making it particularly well- suited for scenarios involving large datasets or long patterns. The bad-character heuristic optimizes the search by shifting the pattern when a mismatch occurs, aligning the pattern with the last occurrence of the mismatched character or skipping the entire section of the text if no such character exists in the pattern. The good-suffix heuristic ensures that the pattern is shifted in such a way that the matched portion is maximized, thus avoiding redundant checks of previously matched characters. Together, these heuristics make the Boyer-Moore algorithm more efficient by allowing it to "jump" over sections of the text that cannot possibly match, resulting in significantly fewer comparisons. In terms of practical applications, Boyer-Moore is widely used in a variety of fields such as text searching in search engines and text editors, DNA sequence analysis for finding genetic patterns, data mining for pattern matching in large datasets, and digital forensics for identifying keywords in massive data logs. Its efficiency in processing large volumes of data makes it indispensable in areas requiring fast, high-performance string matching, such as real-time data analysis and bioinformatics. However, it is important to note that the worst-case performance of Boyer-Moore can still degrade to O(n * m), especially in situations where the pattern contains many repetitive characters or when the text and pattern have a lot of common elements. Despite this, in most practical cases, the algorithm outperforms others like the Knuth-Morris-Pratt (KMP) and naive string matching algorithms due to its heuristic optimizations. Overall, the Boyer-Moore algorithm is a powerful tool for string searching, offering a significant improvement over simpler algorithms, particularly in cases where the text is large and the pattern is relatively long. It is a cornerstone in the field of string matching algorithms, and its principles are widely used across various domains, including text processing, computational biology, and data analysis. DEPT OF CSE, KISHKINDA UNIVERSITY, BALLARI Page 8